Chapter: Multicore Application Programming For Windows, Linux, and Oracle Solaris : Hardware, Processes, and Threads
The Characteristics of Multiprocessor Systems
The
Characteristics of Multiprocessor Systems
Although
processors with multiple cores are now prevalent, it is also becoming more
common to encounter systems with multiple processors. As soon as there are
multiple processors in a system, accessing memory becomes more complex. Not
only can data be held in memory, but it can also be held in the caches of one
of the other processors. For code to execute correctly, there should be only a
single up-to-date version of each item of data; this feature is called cache coherence.
The
common approach to providing cache coherence is called snooping. Each proces-sor broadcasts the address that it wants to
either read or write. The other processors watch for these broadcasts. When
they see that the address of data they hold can take one of two actions, they
can return the data if the other processor wants to read the data and they have
the most recent copy. If the other processor wants to store a new value for the
data, they can invalidate their copy.
However,
this is not the only issue that appears when dealing with multiple proces-sors.
Other concerns are memory layout and latency.
Imagine a
system with two processors. The system could be configured with all the memory
attached to one processor or the memory evenly shared between the two
processors. Figure 1.18 shows these two alternatives.
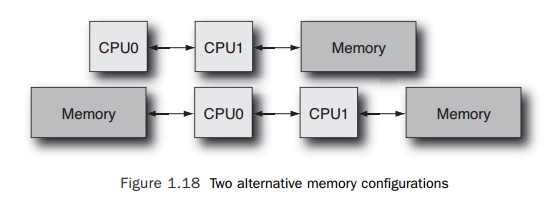
Each link
between processor and memory will increase the latency of any memory access by
that processor. So if only one processor has memory attached, then that
proces-sor will see low memory latency, and the other processor will see higher
memory latency. In the situation where both processors have memory attached,
then they will have both local memory that is low cost to access and remote
memory that is higher cost to access.
For
systems where memory is attached to multiple processors, there are two options
for reducing the performance impact. One approach is to interleave memory,
often at a cache line boundary, so that for most applications, half the memory
accesses will see the short memory access, and half will see the long memory
access; so, on average, applica-tions will record memory latency that is the
average of the two extremes. This approach typifies what is known as a uniform memory architecture (UMA), where
all the processors see the same memory latency.
The other
approach is to accept that different regions of memory will have different
access costs for the processors in a system and then to make the operating
system aware of this hardware characteristic. With operating system support,
this can lead to applica-tions usually seeing the lower memory cost of
accessing local memory. A system with this architecture is often referred to as
having cache coherent nonuniform memory
architecture (ccNUMA).
For the
operating system to manage ccNUMA memory characteristics effectively, it has to
do a number of things. First, it needs to be aware of the locality structure of
the system so that for each processor it is able to allocate memory with low
access latencies. The second challenge is that once a process has been run on a
particular processor, the operating system needs to keep scheduling that
process to that processor. If the operating system fails to achieve this second
requirement, then all the locally allocated memory will become remote memory
when the process gets migrated.
Consider
an application running on the first processor of a two-processor system. The
operating system may have allocated memory to be local to this first processor.
Figure 1.19 shows this configuration of an application running on a processor
and using local memory. The shading in this figure illustrates the application
running on processor 1 and accessing memory directly attached to that
processor. Hence, the process sees local memory latency for all memory
accesses.
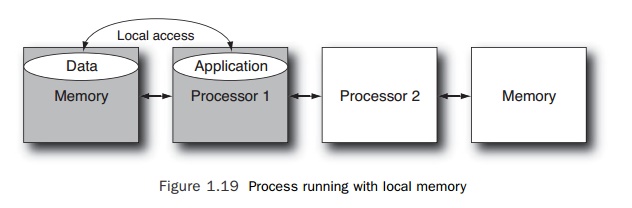
The
application will get good performance because the data that it frequently
accesses will be held in the memory with the lowest access latency. However, if
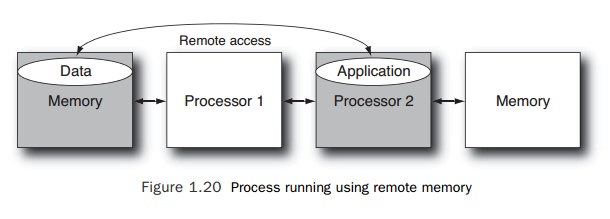
that application then gets migrated to the second processor, the application
will be accessing data that is remotely held and will see a corresponding drop
in performance. Figure 1.20 shows an application using remote memory. The
shading in the figure shows the application run-ning on processor 2 but
accessing data held on memory that is attached to processor 1. Hence, all
memory accesses for the application will fetch remote data; the fetches of data
will take longer to complete, and the application will run more slowly.
Related Topics