Chapter: Multicore Application Programming For Windows, Linux, and Oracle Solaris : Hardware, Processes, and Threads
Translating from Virtual Addresses to Physical Addresses
Translating
from Virtual Addresses to Physical Addresses
The
critical step in using virtual memory is the translation of a virtual address,
as used by an application, into a physical address, as used by the processor,
to fetch the data from memory. This step is achieved using a part of the
processor called the translation
look-aside buffer (TLB).
Typically, there will be one TLB for translating the address of instructions (the instruction TLB or ITLB) and a
second TLB for translating the address of data (the data TLB, or DTLB).
Each TLB
is a list of the virtual address range and corresponding physical address range
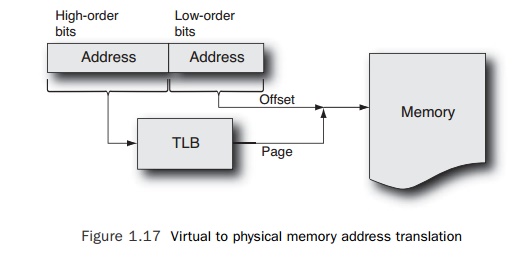
of each page in memory. So when a processor needs to translate a virtual
address to a physical address, it first splits the address into a virtual page
(the high-order bits) and an offset from the start of that page (the low-order
bits). It then looks up the address of this virtual page in the list of
translations held in the TLB. It gets the physical address of the page and adds
the offset to this to get the address of the data in physical memory. It can
then use this to fetch the data. Figure 1.17 shows this process.
Unfortunately,
a TLB can hold only a limited set of translations. So, sometimes a processor
will need to find a physical address, but the translation does not reside in
the TLB. In these cases, the translation is fetched from an in-memory data
structure called a page table, and
this structure can hold many more virtual to physical mappings. When a translation does not reside in the TLB,
it is referred to as a TLB miss, and
TLB misses have an impact on performance. The magnitude of the performance
impact depends on whether the hardware fetches the TLB entry from the page
table or whether this task is managed by software; most current processors handle
this in hardware. It is also possible to have a page table miss, although this
event is very rare for most applications. The page table is managed by
software, so this typically is an expensive or slow event.
TLBs
share many characteristics with caches; consequently, they also share some of
the same problems. TLBs can experience both capacity misses and conflict
misses. A capacity miss is where the amount of memory being mapped by the
application is greater than the amount of memory that can be mapped by the TLB.
Conflict misses are the situation where multiple pages in memory map into the
same TLB entry; adding a new mapping causes the old mapping to be evicted from
the TLB. The miss rate for TLBs can be reduced using the same techniques as
caches do. However, for TLBs, there is one further characteristic that can be
changed—the size of the page that is mapped.
On SPARC
architectures, the default page size is 8KB; on x86, it is 4KB. Each TLB entry
provides a mapping for this range of physical or virtual memory. Modern
proces-sors can handle multiple page sizes, so a single TLB entry might be able
to provide a mapping for a page that is 64KB, 256KB, megabytes, or even
gigabytes in size. The obvi-ous benefit to larger page sizes is that fewer TLB
entries are needed to map the virtual address space that an application uses.
Using fewer TLB entries means less chance of them being knocked out of the TLB
when a new entry is loaded. This results in a lower TLB miss rate. For example,
mapping a 1GB address space with 4MB pages requires 256 entries, whereas
mapping the same memory with 8KB pages would require 131,072. It might be
possible for 256 entries to fit into a TLB, but 131,072 would not.
The
following are some disadvantages to using larger page sizes:
n Allocation
of a large page requires a contiguous block of physical memory to allo-cate the
page. If there is not sufficient contiguous memory, then it is not possible to
allocate the large page. This problem introduces challenges for the operating
sys-tem in handling and making large pages available. If it is not possible to
provide a large page to an application, the operating system has the option of
either moving other allocated physical memory around or providing the
application with multi-ple smaller pages.
An
application that uses large pages will reserve that much physical memory even
if the application does not require the memory. This can lead to memory being used
inefficiently. Even a small application may end up reserving large amounts of
physical memory.
n A problem
particular to multiprocessor systems is that pages in memory will often have a
lower access latency from one processor than another. The larger the page size,
the more likely it is that the page will be shared between threads running on
different processors. The threads running on the processor with the higher
mem-ory latency may run slower. This issue will be discussed in more detail in
the next section, “The Characteristics of Multiprocessor Systems.”
For most
applications, using large page sizes will lead to a performance improvement,
although there will be instances where other factors will outweigh these
benefits.
Related Topics