Chapter: An Introduction to Parallel Programming : Shared-Memory Programming with OpenMP
Shared-Memory Programming with OpenMP
Chapter 5
Shared-Memory Programming with OpenMP
Like Pthreads, OpenMP is an
API for shared-memory parallel programming. The “MP” in OpenMP stands for
“multiprocessing,” a term that is synonymous with shared-memory parallel
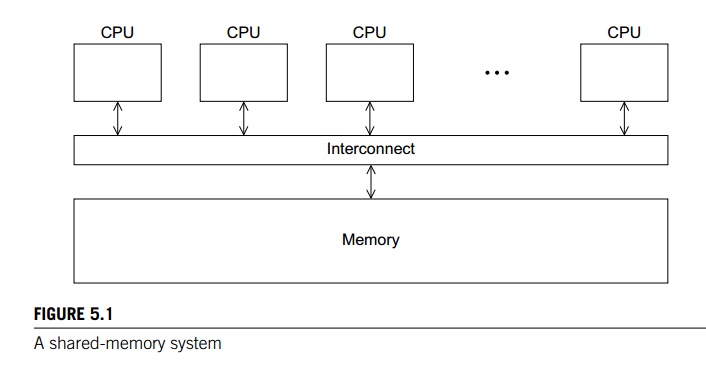
computing. Thus, OpenMP is designed for systems in which each thread or process
can potentially have access to all available memory, and, when we’re
programming with OpenMP, we view our system as a collection of cores or CPUs,
all of which have access to main memory, as in Figure 5.1.
Although OpenMP and Pthreads
are both APIs for shared-memory programming, they have many fundamental differences.
Pthreads requires that the programmer explicitly specify the behavior of each
thread. OpenMP, on the other hand, some-times allows the programmer to simply
state that a block of code should be executed in parallel, and the precise
determination of the tasks and which thread should execute them is left to the
compiler and the run-time system. This suggests a further differ-ence between
OpenMP and Pthreads, that is, that Pthreads (like MPI) is a library of
functions that can be linked to a C program, so any Pthreads program can be
used with any C compiler, provided the system has a Pthreads library. OpenMP,
on the other hand, requires compiler support for some operations, and hence
it’s entirely possible that you may run across a C compiler that can’t compile
OpenMP programs into parallel programs.
These differences also
suggest why there are two standard APIs for shared-memory programming: Pthreads
is lower level and provides us with the power to program virtually any
conceivable thread behavior. This power, however, comes with some associated
cost—it’s up to us to specify every detail of the behavior of each thread.
OpenMP, on the other hand, allows the compiler and run-time system to
deter-mine some of the details of thread behavior, so it can be simpler to code
some parallel behaviors using OpenMP. The cost is that some low-level thread
interactions can be more difficult to program.
OpenMP was developed by a
group of programmers and computer scien-tists who believed that writing
large-scale high-performance programs using APIs such as Pthreads was too
difficult, and they defined the OpenMP specification so that shared-memory
programs could be developed at a higher level. In fact, OpenMP was explicitly
designed to allow programmers to incrementally parallelize
existing serial programs;
this is virtually impossible with MPI and fairly difficult with Pthreads.
In this chapter, we’ll learn
the basics of OpenMP. We’ll learn how to write a program that can use OpenMP,
and we’ll learn how to compile and run OpenMP pro-grams. We’ll then learn how
to exploit one of the most powerful features of OpenMP: its ability to
parallelize many serial for loops with only small changes to the source
code. We’ll then look at some other features of OpenMP: task-parallelism and
explicit thread synchronization. We’ll also look at some standard problems in
shared-memory programming: the effect of cache memories on shared-memory
programming and problems that can be encountered when serial code—especially a
serial library—is used in a shared-memory program. Let’s get started.
1. GETTING STARTED
OpenMP provides what’s known as a
“directives-based” shared-memory API. In C and C++, this means that there are special preprocessor instructions known
as pragmas. Pragmas are typically added to a system to allow behaviors that
aren’t part of the basic C specification. Compilers that don’t support the pragmas are free to ignore them. This allows a program that uses the pragmas to run on platforms that don’t support them. So, in principle, if
you have a carefully written OpenMP pro-gram, it can be compiled and run on any
system with a C compiler, regardless of whether the compiler supports OpenMP.
Pragmas in C and C++ start with
#pragma
As usual, we put the pound sign, #, in column 1, and like other preprocessor direc-tives, we shift
the remainder of the directive so that it is aligned with the rest of the code.
Pragmas (like all preprocessor directives) are, by default, one line in
length, so if a pragma won’t fit on a single line, the newline needs
to be “escaped”—that is, preceded by a backslash n. The details of what follows the #pragma depend entirely on which extensions are being used.
Let’s take a look at a very simple example, a “hello, world” program that
uses OpenMP. See Program 5.1.
Program 5.1: A “hello,world” program that uses OpenMP
#include
<stdio.h>
#include
<stdlib.h>
#include
<omp.h>
void
Hello(void); / Thread function /
int
main(int argc, char argv[]) {
/* Get number of threads from command line */
int
thread_count = strtol(argv[1], NULL, 10);
# pragma omp parallel num_threads(thread count)
Hello();
return
0;
} /*
main */
void
Hello(void) {
int
my_rank = omp_get_thread_num();
int
thread_count = omp_get_num_threads();
printf("Hello
from thread %d of %d\n", my rank, thread count);
} /* Hello */
1. Compiling and running OpenMP
programs
To compile this with gcc we need to include the fopenmp option:
$ gcc -g -Wall -fopenmp -o omp_hello omp_hello.c
To run the program, we specify the number of
threads on the command line. For example, we might run the program with four
threads and type
$ ./omp_hello 4
If we do this, the output might be
Hello from thread 0 of 4
Hello from thread 1 of 4
Hello from thread 2 of 4
Hello from thread 3 of 4
However, it should be noted that the threads
are competing for access to stdout, so there’s no guarantee that the output will
appear in thread-rank order. For example, the output might also be
Hello from thread 1 of 4
Hello from thread 2 of 4
Hello from thread 0 of 4
Hello from thread 3 of 4
or
Hello from thread 3 of 4
Hello from thread 1 of 4
Hello from thread 2 of 4
Hello from thread 0 of 4
or any other permutation of the thread ranks.
If we want to run the program with just one
thread, we can type
$ ./omp_hello 1
and we would get the output
Hello from thread 0 of 1
2. The program
Let’s take a look at the source code. In
addition to a collection of directives, OpenMP consists of a library of
functions and macros, so we usually need to include a header file with
prototypes and macro definitions. The OpenMP header file is omp.h, and we include it in Line 3.
In our Pthreads programs, we specified the
number of threads on the command line. We’ll also usually do this with our OpenMP
programs. In Line 9 we therefore use the strtol function from stdlib.h to get the number of threads. Recall that the
syntax of this function is
long strtol(
const char* number
p /* in */,
char end
p /* out */,
int base /* in */);
The first argument is a string—in our example,
it’s the command-line argument— and the last argument is the numeric base in
which the string is represented—in our example, it’s base 10. We won’t make use
of the second argument, so we’ll just pass in a NULL pointer.
If you’ve done a little C programming, there’s
nothing really new up to this point. When we start the program from the command
line, the operating system starts a single-threaded process and the process
executes the code in the main function. How-ever, things get interesting in
Line 11. This is our first OpenMP directive, and we’re using it to specify that
the program should start some threads. Each thread that’s forked should execute
the Hello function, and when the threads return from the call to Hello, they should be terminated, and the process should then terminate
when it executes the return statement.
That’s a lot of bang for the buck (or code). If
you studied the Pthreads chapter, you’ll recall that we had to write a lot of
code to fork and join multiple threads: we needed to allocate storage for a
special struct for each thread, we used a for loop to start each thread, and we used another for loop to terminate the threads. Thus, it’s
immediately evident that OpenMP is higher-level than Pthreads.
We’ve already seen that pragmas in C and C++ start with
# pragma
OpenMP pragmas always begin with
# pragma omp
Our first directive is a parallel directive, and, as you might have guessed it spec-ifies that the structured block of code that follows should be executed by
multiple threads. A structured block is a C statement or a compound C statement
with one point of entry and one point of exit, although calls to the function exit are allowed. This definition simply prohibits code that branches
into or out of the middle of the structured block.
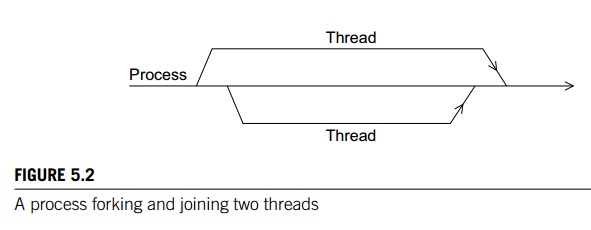
Recollect that thread is short for thread of execution. The name is meant to sug-gest a sequence of
statements executed by a program. Threads are typically started or forked by a process, and they share most of the
resources of the process that starts them—for example, access to stdin and stdout—but each thread has its own stack and program
counter. When a thread completes execution it joins the process that started it. This terminology comes from diagrams
that show threads as directed lines. See Figure 5.2. For more details see
Chapters 2 and 4.
At its most basic the parallel directive is simply
# pragma omp parallel
and the number of threads that run the
following structured block of code will be determined by the run-time system.
The algorithm used is fairly complicated; see the OpenMP Standard [42] for
details. However, if there are no other threads started, the system will
typically run one thread on each available core.
As we noted earlier, we’ll usually specify the
number of threads on the command line, so we’ll modify our parallel directives with the num
threads clause. A clause in OpenMP is just some text that modifies a directive. The num threads clause can be added to a parallel directive. It allows the programmer to specify
the number of threads that should execute the following block:
# pragma omp parallel num_threads(thread_count)
It should be noted that there may be
system-defined limitations on the number of threads that a program can start. The
OpenMP Standard doesn’t guarantee that this will actually start thread count threads. However, most current systems can start hundreds or even
thousands of threads, so unless we’re trying to start a lot of threads, we will almost always get the
desired number of threads.
What actually happens when the program gets to
the parallel directive? Prior to the parallel directive, the program is using a
single thread, the process started when the program started execution. When the
program reaches the parallel direc-tive, the original thread continues
executing and thread count 1 additional threads are started. In OpenMP
parlance, the collection of threads executing the parallel block—the original
thread and the new threads—is called a team, the original thread is called the
master, and the additional threads are called slaves. Each thread in the team
executes the block following the directive, so in our example, each thread
calls the Hello function.
When the block of code is completed—in our
example, when the threads return from the call to Hello—there’s an implicit barrier. This means that a thread that has completed
the block of code will wait for all the other threads in the team to complete
the block—in our example, a thread that has completed the call to Hello will wait for all the other threads in the team to return. When
all the threads have completed the block, the slave threads will terminate and
the master thread will continue executing the code that follows the block. In
our example, the master thread will execute the return statement in Line 14, and the program will terminate.
Since each thread has its own stack, a thread
executing the Hello function will create its own private, local variables in the
function. In our example, when the func-tion is called, each thread will get
its rank or id and the number of threads in the team by calling the OpenMP
functions omp get thread num and omp get
num threads, respectively. The rank or
id of a thread is an int that is in the range 0, 1, ….., thread
count-1. The syntax for these functions is
int omp_get_thread_num(void);
int omp_get_num_threads(void);
Since stdout is shared among the threads, each thread can
execute the printf state-ment, printing its rank and the number of threads. As we
noted earlier, there is no scheduling of access to stdout, so the actual order in which the threads print their results is
nondeterministic.
3. Error checking
In order to make the code more compact and more
readable, our program doesn’t do any error checking. Of course, this is
dangerous, and, in practice, it’s a very good idea—one might even say mandatory—to try to anticipate errors
and check for them. In this example, we should definitely check for the
presence of a command-line argu-ment, and, if there is one, after the call to strtol we should check that the value is positive. We might also check
that the number of threads actually created by the parallel directive is the same as thread
count, but in this simple example, this isn’t crucial.
A second source of potential problems is the
compiler. If the compiler doesn’t support OpenMP, it will just ignore the parallel directive. However, the attempt to include omp.h and the calls to omp_get_thread_num and omp_get_num_threads will cause errors. To handle these problems, we can check whether the
preprocessor macro OPENMP is defined. If this is defined, we can include
omp.h and make the calls to the OpenMP functions. We might make the
following modifications to our program.
Instead of simply including omp.h in the line
#include <omp.h>
we can check for the definition of OPENMP before trying to include it:
#ifdef _OPENMP
# include <omp.h>
#endif
Also, instead of just calling the OpenMP
functions, we can first check whether_OPENMP is defined:
# ifdef OPENMP
int my_rank = omp_get_thread num();
int thread_count = omp_get_num_threads();
# else
int my_rank = 0;
int thread_count = 1;
# endif
Here, if OpenMP isn’t available, we assume that
the Hello function will be single-threaded. Thus, the single thread’s rank
will be 0 and the number of threads will be one.
The book’s website contains the source for a
version of this program that makes these checks. In order to make our code as
clear as possible, we’ll usually show little, if any, error checking in the
code displayed in the text.
Related Topics