Number Systems | Computer Science - Representing Characters in Memory | 11th Computer Science : Chapter 2 : Number Systems
Chapter: 11th Computer Science : Chapter 2 : Number Systems
Representing Characters in Memory
Representing Characters in Memory
As represented in introduction,
all the input data given to the computer should be in understandable format. In
general, 26 uppercase letters, 26 lowercase letters, 0 to 9 digits and special
characters are used in a computer, which is called character set. All these
character set are denoted through numbers only. All Characters in the character
set needs a common encoding system. There are several encoding systems used for
computer. They are
• EBCDIC – Extended Binary Coded Decimal Interchange Code
• ASCII – American Standard Code for Information Interchange
• Unicode
• ISCII - Indian Standard Code for Information Interchange
1. Binary Coded Decimal (BCD)
This encoding system is not in the
practice right now. This is 26 bit encoding system. This can handle
26 = 64 characters only.
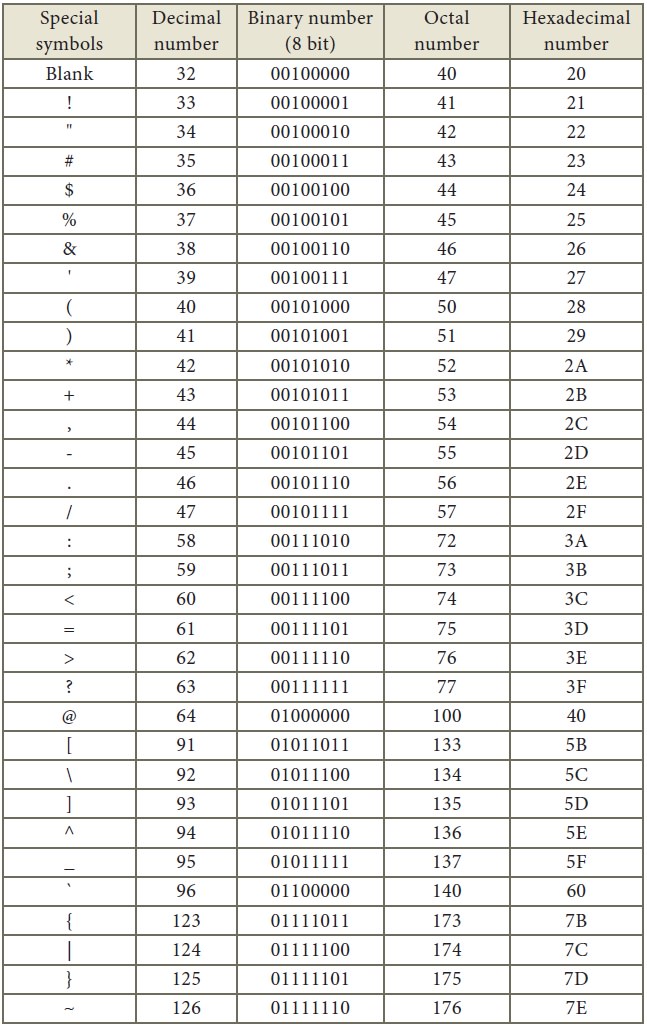
2. American Standard Code for Information Interchange (ASCII)
This is the most popular encoding
system recognized by United States. Most of the computers use this system.
Remember this encoding system can handle English characters only. This can handle
27 bit which means 128 characters.
In this system, each character has
individual number (Refer Appendix).
The new edition (version) ASCII
-8, has 28 bits and can handle 256 characters are represented from 0
to 255 unique numbers.
The ASCII code equivalent to the
uppercase letter ‘A’ is 65. The binary representation of ASCII (7 bit) value is
1000001. Also 01000001 in ASCII-8 bit.
3. Extended Binary Coded Decimal Interchange Code (EBCDIC)
This is similar to ASCII Code with
8 bit representation. This coding system is formulated by International
Business Machine(IBM). The coding system can handle 256 characters. The input
code in ASCII can be converted to EBCDIC system and vice - versa.
4. Indian Standard Code for Information Interchange (ISCII)
ISCII is the system of handling
the character of Indian local languages. This as a 8-bit coding system.
Therefore it can handle 256 (28) characters. This system is
formulated by the department of Electronics in India in the year 1986-88 and
recognized by Bureau of Indian Standards (BIS). Now this coding system is
integrated with Unicode.
5. Unicode
This coding system is used in most
of the modern computers. The popular coding scheme after ASCII is Unicode.
ASCII can represent only 256 characters. Therefore English and European
Languages alone can be handled by ASCII. Particularly there was a situation,
when the languages like Tamil, Malayalam, Kannada and Telugu could not be
represented by ASCII. Hence, the Unicode was generated to handle all the coding
system of Universal languages. This is 16 bit code and can handle 65536
characters.
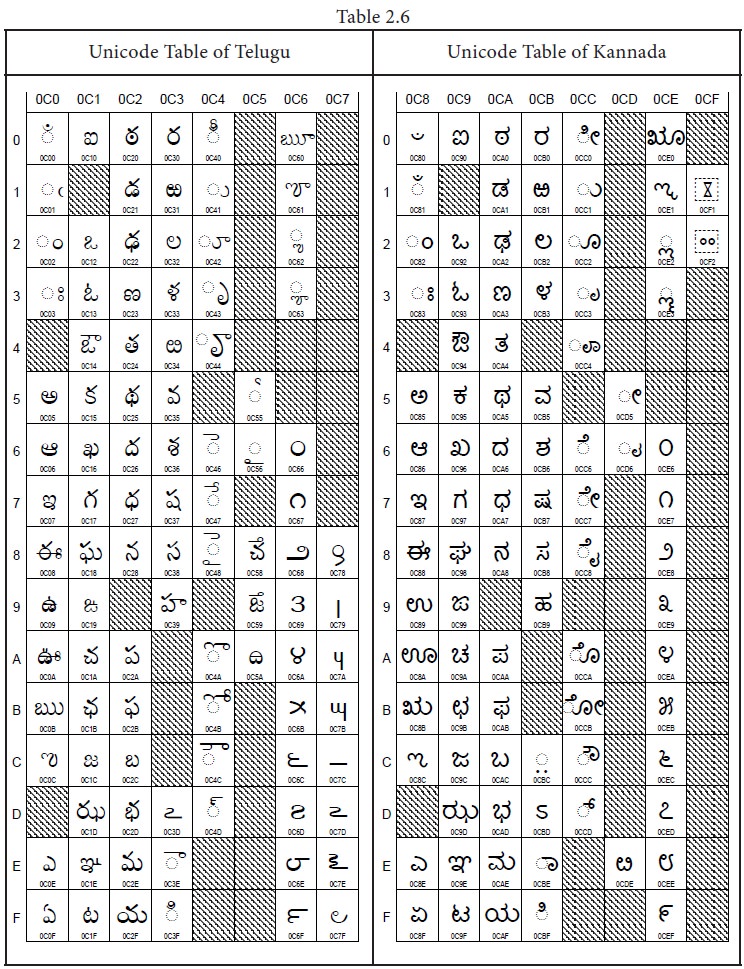
Unicode scheme is denoted by
hexadecimal numbers. The Unicode table of Tamil, Malayalam, Telugu and Kannada
is shown Table 2.6

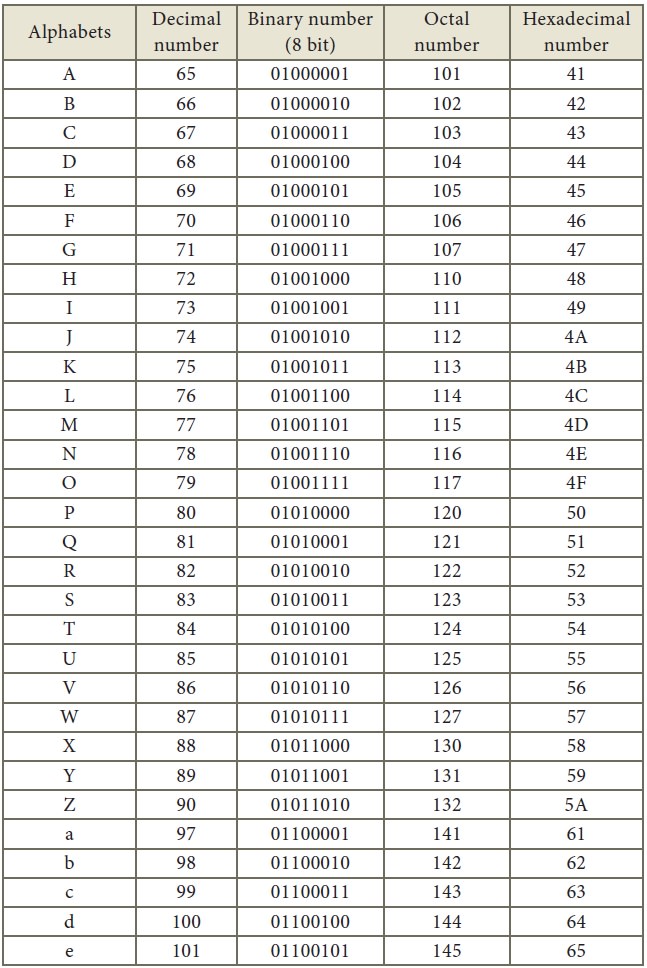
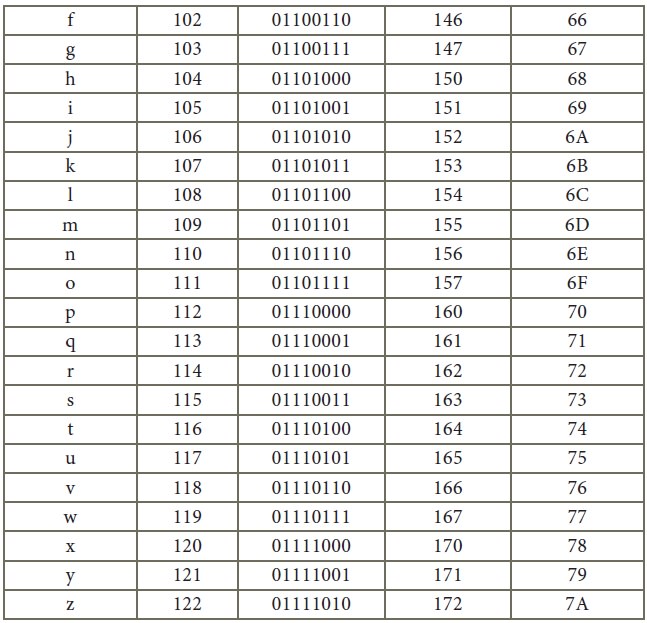
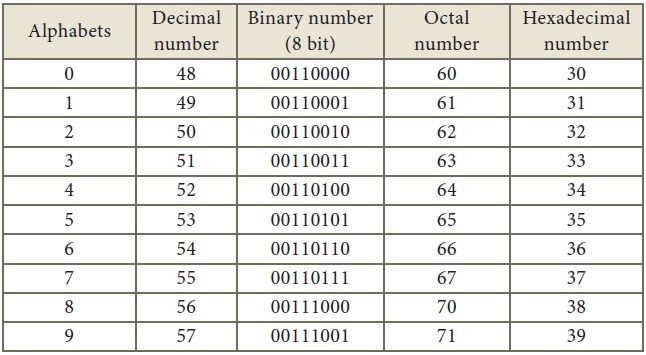
Appendix
American Standard Code for
Information Interchange (ASCII)
(Few specific characters only)
Related Topics