Chapter: Database Management Systems : Introduction to DBMS
Relational Algebra
Relational Query Languages
•
Languages for describing queries on a
relational database
•
Structured Query Language (SQL)
–Predominant
application-level query language
–Declarative
• Relational Algebra
–Intermediate
language used within DBMS
–Procedural
What is Algebra?
•
A language based on operators and a
domain of values
•
Operators map values taken from the
domain into other domain values
•
Hence, an expression involving operators
and arguments produces a value in the domain
•
When the domain is a set of all
relations (and the operators are as described later), we get the relational
algebra
•
We refer to the expression as a query
and the value produced as the query
Relational Algebra
•
Domain:
set of relations
•
Basic operators:
select, project, union, set difference, Cartesian product
•
Derived operators:
set intersection, division, join
•
Procedural:
Relational expression specifies query by describing an algorithm (the sequence
in which operators are applied) for determining the result of an
expression
Select Operator
• Produce table containing subset of rows of
argument table satisfying condition

Selection Condition
• Operators: 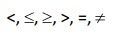
• Simple selection condition:
–<attribute>
operator <constant>
–<attribute>
operator <attribute>
•
<condition> AND <condition>
•
<condition> OR <condition>
•
NOT <condition>
Project Operator
Produces table containing subset of columns of
argument table
• Example:

Set Operators
•
Relation is a set of tuples => set
operations should apply
•
Result of combining two relations with a
set operator is a relation => all its elements must be tuples having same
structure
•
Hence, scope of set operations limited
to union compatible relations
Union Compatible Relations
•
Two relations are union compatible
if
– Both have
same number of columns
– Names of
attributes are the same in both
– Attributes
with the same name in both relations have the same domain
•
Union compatible relations can be
combined using union, intersection, and set difference
Cartesian product
•
If R and S are two
relations, R S is the set of all concatenated tuples <x,y>,
where x is a tuple in R and y is a tuple in S
– (R
and S need not be union compatible)
•
R
S is expensive to compute:
– Factor of
two in the size of each row
– Quadratic
in the number of rows
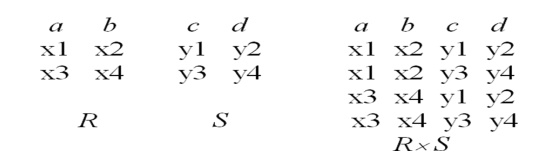
GROUP BY
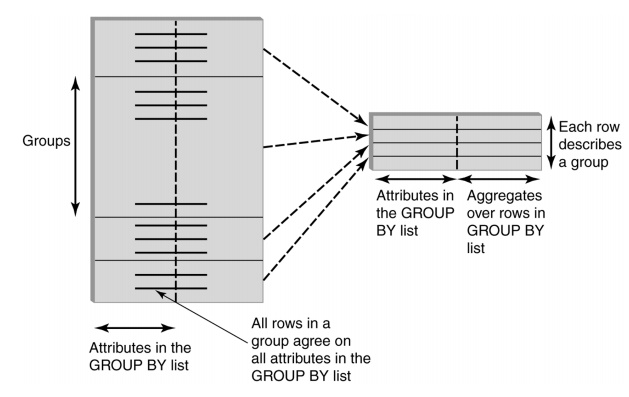
HAVING Clause
•
Eliminates unwanted groups (analogous to
WHERE clause)
•
HAVING condition constructed from
attributes of GROUP BY list and aggregates of attributes not in list
SELECT
T.StudId, AVG(T.Grade) AS CumGpa,
COUNT
(*) AS NumCrs
WHERE
T.CrsCode LIKE ‘CS%’
GROUP
BY T.StudId
HAVING
AVG (T.Grade) > 3.5.
A Database Management
System is a software environment that structures and manipulatesdata, and
ensures data security, recovery, and integrity. The Data Platform relies on a
database management system (RDBMS) to store and maintain all of its data as
well as execute all the associated queries. There are two types of RDBMS : the
first group consists of single software packages which support only a single
database, with a single user access and are not scalable (i.e. cannot handle
large amounts of data). Typical examples of this first group are MS Access and
FileMaker. The second group is formed by DBMS composed of one or more programs
and their associated services which support one or many databases for one or
many users in ascalable fashion. For example an enterprise database server can
support the HR database,the accounting database and the stocks database all at
the same time. Typical examples ofthis second group include MySQL, MS SQL
Server, Oracle and DB2. The DBMS selected for the Data Platform is MS SQL
Server from the second group.
Table
A table is set of data
elements that has a horizontal dimension (rows) and a vertical dimension
(columns) in a relational database system. A table has a specified number of
columns but can have any number of rows. Rows stored in a table are
structurally equivalent to records from flat files. Columns are often referred
as attributes or fields. In a database managed by a DBMS the format of each
attribute is a fixed datatype. For example the attribute date can only contain
information in the date time format.
Identifier
An identifier is an
attribute that is used either as a primary key or as a foreign key. The integer
datatype is used for identifiers. In cases where the number of records exceed
the allowed values by the integer datatype then a biginteger datatype is used.
Primary key
A column in a table
whose values uniquely identify the rows in the table. A primary key value
cannot be NULLto matching columns in other tables\
Foreign key
A column in a table
that does not uniquely identify rows in that table, but is used as a link to
matching columns in other tables.
Relationship
A relationship is an
association between two tables. For example the relationship between the table
"hotel" and "customer" maps the customers to the hotels
they have used.
Index
An index is a data structure which enables a query
to run at a sublinear-time. Instead of having to go through all records one by
one to identify those which match its criteria the query uses the index to
filter out those which don't and focus on those who do.
View
A view is a virtual or logical table composed of the
result set of a pre-compiled query. Unlike ordinary tables in a relational
database, a view is not part of the physical schema: it is a dynamic, virtual
table computed or collated from data in the database. Changing the data in a
view alters the data stored in the database
Query
A query is a request to retrieve data from a
database with the SQL SELECT instruction or to manipulate data stored in
tables.
SQL
Structured Query Language (SQL), pronounced
"sequel", is a language that provides an interface to relational
database systems. It was developed by IBM in the 1970s for use in System R. SQL
is a de facto standard, as well as an ISO and ANSI standard.
Relational
Database Management System
E. F. Codd‟s Twelve Rules for Relational Databases
Codd's twelve rules call for a language that can be
used to define, manipulate, and query the data in the database, expressed as a
string of characters. Some references to the twelve rules include a thirteenth
rule - or rule zero:
1. Information
Rule: All information in the database should be represented in one and only one way -- as values in a table.
2. Guaranteed
Access Rule: Each and every datum (atomic value) is guaranteed to be logically accessible by resorting to a
combination of table name, primary key value, and column name.
3. Systematic
Treatment of Null Values: Null values (distinct from empty character string or
a string of blank characters and distinct from zero or any other number) are
supported in the fully relational DBMS for representing missing information in
a systematic way, independent of data type.
4. Dynamic
Online Catalog Based on the Relational Model: The database description is
represented at the logical level in the same way as ordinary data, so
authorized users can apply the same relational
language to its interrogation as they apply to regular data.
5. Comprehensive Data Sublanguage Rule: A relational
system may support several languages and various modes of terminal use. However,
there must be at least one language whose statements are expressible, per some
well-defined syntax, as character strings and whose ability to support all of
the following is comprehensible:
a. data
definition
b. view
definition
c. data
manipulation (interactive and by program)
d. integrity
constraints
e. authorization
f. transaction
boundaries (begin, commit, and rollback).
6.View Updating Rule:
All views that are theoretically updateable are also updateable by the system.
6. High-Level
Insert, Update, and Delete: The capability of handling a base relation or a
derived relation as a single operand applies not only to the retrieval of data,
but also to the insertion, update, and deletion of data.
7. Physical
Data Independence: Application programs and terminal activities remain
logically unimpaired whenever any changes are made in either storage
representation or access methods.
8. Logical
Data Independence: Application programs and terminal activities remain
logically
unimpaired when information preserving changes of
any kind that theoretically permit unimpairment are made to the base tables.
10.
Integrity Independence: Integrity
constraints specific to a particular relational database must be definable in
the relational data sublanguage and storable in the catalog, not in the
application programs.
11.
Distribution Independence: The data
manipulation sublanguage of a relational DBMS must enable application programs
and terminal activities to remain logically
unimpaired whether and whenever data are physically
centralized or distributed.
12.
Nonsubversion Rule: If a relational
system has or supports a low-level (single- record-at-a-time) language, that
low-level language cannot be used to subvert or bypass the integrity rules or
constraints expressed in the higher-level (multiple- records-at-a-time)
relational language.
Related Topics