Chapter: Database Management Systems : Introduction to DBMS
File systems vs Database systems
File systems vs Database systems:
DBMS
are expensive to create in terms of software, hardware, and time invested.
So why use them? Why couldn‟t we just ke processors
to edit the files appropriately to insert, delete, or update data? And we could
write our own programs to query the data! This solution is called maintaining
data in flat files. So what is bad about flat files?
o Uncontrolled redundancy
o Inconsistent data
o Inflexibility
o Limited data sharing
o Poor enforcement of standards o Low programmer
productivity
o Excessive program maintenance o Excessive data
maintenance
File System
§
Data
is stored in Different Files in forms of Records
§
The
programs are written time to time as per the requirement to manipulate the data
within files.
§
A program to debit and credit an
account
§
A program to find the balance of an
account
§
A program to generate monthly statements
Disadvantages of File system over DBMS
Most explicit and major
disadvantages of file system when compared to database managementsystem are as
follows:
Data
Redundancy- The files are created in the file
system as and when required by anenterprise over its growth path.
So in that case the repetition of information about anentity cannot be avoided.
Eg. The addresses of customers will be present in
the file maintaining information
about customers holding
savings account and also the address of the customers will be present in file
maintaining the current account. Even when same customer have a saving account
and current account his address will be present at two places.
Data
Inconsistency: Data redundancy leads to greater
problem than just wasting thestorage i.e. it may lead to
inconsistent data. Same data which has been repeated at severalplaces may not
match after it has been updated at some places.
For example: Suppose the customer requests to change
the address for his account in
the Bank and the
Program is executed to update the saving bank account file only but hiscurrent
bank account file is not updated. Afterwards the addresses of the same
customerpresent in saving bank account file and current bank account file will
not match.Moreover there will be no way to find out which address is latest out
of these two.
Difficulty
in Accessing Data: For generating ad hoc reports the
programs will not alreadybe present and only options present will
to write a new program to generate requestedreport or to work manually. This is
going to take impractical time and will be more expensive.
For example: Suppose all of sudden the administrator
gets a request to generate a list of all the customers holding the saving banks
account who lives in particular locality of the city. Administrator will not
have any program already written to generate that list but say he has a program
which can generate a list of all the customers holding the savings account.
Then he can either provide the information by going thru the list manually to
select the customers living in the particular locality or he can write a new
program to generate the new list. Both of these ways will take large time which
would generally be impractical.
Data
Isolation: Since the data files are created at
different times and supposedly bydifferent people the structures
of different files generally will not match. The data will be scattered in
different files for a particular entity. So it will be difficult to obtain
appropriate data.
For example: Suppose the Address in Saving Account
file have fields: Add line1, Add line2, City, State, Pin while
the fields in address of Current account are: House No., Street No.,
Locality, City, State, Pin. Administrator is asked to provide the list
of customers living in a particular locality. Providing
consolidated list of all the customers will require looking in both files. But they both have different way of storing the
address. Writing a program to generate such a list will be difficult.
Integrity
Problems: All
the consistency constraints have to be applied to database through appropriate
checks in the coded programs. This is very difficult when number such
constraint is very large.
For example: An account should not have balance less
than Rs. 500. To enforce this constraint appropriate check should be added in
the program which add a record and the program which withdraw from an account.
Suppose later on this amount limit is increased then all those check should be
updated to avoid inconsistency. These time to time changes in the programs will
be great headache for the administrator.
Security
and access control: Database
should be protected from unauthorized users. Every user should
not be allowed to access every data. Since application programs are added to
the system
For example: The
Payroll Personnel in a bank should not be allowed to access accounts
information of the customers.
Concurrency
Problems: When
more than one users are allowed to process the database. If in
that environment two or more users try to update a shared data element at about
the same time then it may result into inconsistent data. For example: Suppose
Balance of an account is Rs. 500. And User A and B try to withdraw Rs 100 and
Rs 50 respectively at almost the same time using the Update process.
Update:
1. Read
the balance amount.
2. Subtract
the withdrawn amount from balance.
3. Write
updated Balance value.
Suppose A performs Step
1 and 2 on the balance amount i.e it reads 500 and subtract100 from it. But at
the same time B withdraws Rs 50 and he performs the Update process and he also
reads the balance as 500 subtract 50 and writes back 450. User A will also
write his updated Balance amount as 400. They may update the Balance value in
any order depending on various reasons concerning to system being used by both
of the users. So finally the balance will be either equal to 400 or 450. Both
of these values are wrong for the updated balance and so now the balance amount
is having inconsistent value forever.
Sequential Access
The simplest access
method is Sequential Access. Information in the file is processed in order, one
record after the other. This mode of access is by far the most common; for
example, editors and compilers usually access files in this fashion.
The bulk of the
operations on a file is reads and writes. A read operation reads the next portion
of the file and automatically advances a file pointer, which tracks the I/O
location. Similiarly, a write appends to the end of the file and advances to
the end of the newly written material (the new end of file).
File Pointers
When a file is opened,
Windows associates a file pointer with the default stream. This file
pointer is a 64-bit offset value that specifies the next byte to be read or the
location to receive the next byte written. Each time a file is opened, the
system places the file pointer at the beginning of the file, which is offset
zero. Each read and write operation advances the file pointer by the number of
bytes being read and written. For example, if the file pointer is at the
beginning of the file and a read operation of 5 bytes is requested, the file
pointer will be located at offset 5 immediately after the read operation. As
each byte is read or written, the system advances the file pointer. The file
pointer can also be repositioned by calling the SetFilePointer function.
When the file pointer
reaches the end of a file and the application attempts to read from the file,
no error occurs, but no bytes are read. Therefore, reading zero bytes without
an error means the application has reached the end of the file. Writing zero
bytes does nothing.
An application can
truncate or extend a file by using the SetEndOfFile function. This
function sets the end of file to the current position of the file pointer.
Indexed allocation
– Each file has its own index block(s) of pointers
to its data blocks
•
Logical view
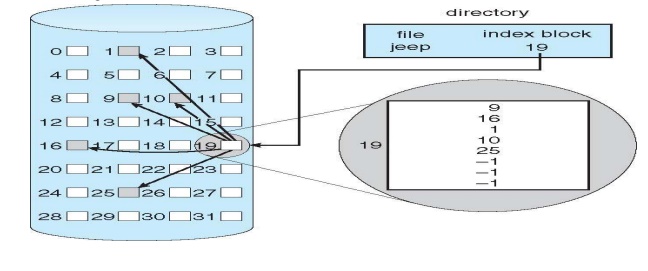
Need index table
Dynamic access without external fragmentation, but
have overhead of index block
Mapping from logical to physical in a file of
maximum size of 256K bytes and block size of 512 bytes. We need only 1 block
for index table
Q
• LA Q512
R
Q = displacement into index table
R = displacement into block
Mapping from logical to
physical in a file of unbounded length (block size of 512 words) Linked scheme
–Link blocks of index table (no limit on size
Q1
• LA Q512 ×511
R1
Q1 =
block of index table R1 is
used as follows:
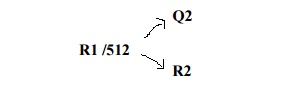
Q2
• R1 /512
R2
Q2
=
displacement into block of index table
R2
displacement
into block of file:
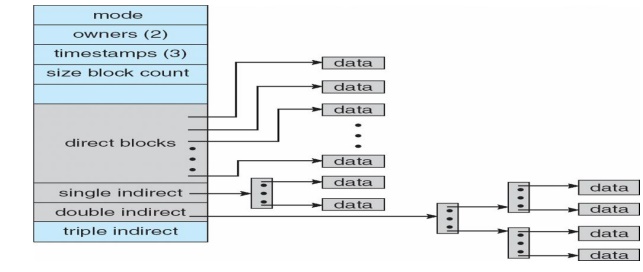
Two-level index (4K
blocks could store 1,024 four-byte pointers in outer index -> 1,048,567 data
blocks and file size of up to 4GB)
-- > Q1
LA
512 / 512
-- > R1
Q1 = displacement into outer-index
R1 is used as follows:
-- >Q2
R1
/512
-- >R2
Q2
=
displacement into block of index table
R2
displacement
into block of file
Best method depends on file access type
– Contiguous
great for sequential and random
•
Linked good for sequential, not
random
•
Declare access type at creation
-> select either contiguous or linked
•
Indexed more
complex
– Single
block access could require 2 index block reads then data block read
– Clustering
can help improve throughput, reduce CPU overhead
•
Adding instructions to the execution
path to save one disk I/O is reasonable
– Intel Core
i7 Extreme Edition 990x (2011) at 3.46Ghz = 159,000 MIPS
•
http://en.wikipedia.org/wiki/Instructions_per_second
– Typical
disk drive at 250 I/Os per second
•
159,000 MIPS / 250 = 630 million
instructions during one disk I/O
– Fast SSD
drives provide 60,000 IOPS
•
159,000 MIPS / 60,000 = 2.65 millions
instructions during one disk I/O
DIRECT ACCESS
Method
useful for disks.
•
The file is viewed as a numbered
sequence of blocks or records.
•
There are no restrictions on which
blocks are read/written in any order
•
User now says "read n" rather
than "read next".
•
"n" is a number relative to
the beginning of file, not relative to an absolute physical disk location.
purpose
of database system
Database management systems were developed to handle
the following difficulties of typical file-processing systems supported by
conventional operating systems:
•
Data redundancy and inconsistency
•
Difficulty in accessing data
•
Data isolation –multiple files and
formats
•
Integrity problems
•
Atomicity of updates
•
Concurrent access by multiple users
•
Security problems
Related Topics