Chapter: An Introduction to Parallel Programming : Shared-Memory Programming with Pthreads
Read-Write Locks
READ-WRITE LOCKS
Let’s take a look at the
problem of controlling access to a large, shared data struc-ture, which can be
either simply searched or updated by the threads. For the sake of explicitness,
let’s suppose the shared data structure is a sorted linked list of ints, and the operations of
interest are Member, Insert, and Delete.
1. Linked list functions
The list itself is composed of a collection of
list nodes, each of which is a struct with two members:
an int and a pointer to the next node. We can define
such a struct with the definition
struct list_node s
{ int data;
struct list_node_s* next;
}
Program 4.9: The Member function
int
Member(int value, struct list_node_s*
head_p) {
struct
list_node_s* curr_p = head_p;
while
(curr_p != NULL && curr_p ->data < value)
curr_p
= curr_p ->next;
if
(curr_p == NULL j j curr_p ->data > value) {
return
0;
}
else {
return
1;
}
} /*
Member */
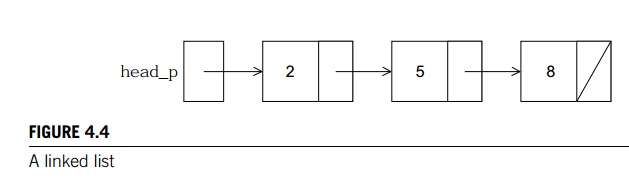
A typical list is shown in Figure 4.4. A
pointer, head_p, with type struct list_node_s* refers to the first node in the list. The next member of the last node is NULL (which is indicated by a slash (/ ) in the next member).
The Member function (Program 4.9) uses a pointer to
traverse the list until it either finds the desired value or determines that
the desired value cannot be in the list. Since the list is sorted, the latter
condition occurs when the curr p pointer is NULL or when the data member of the current node is
larger than the desired value.
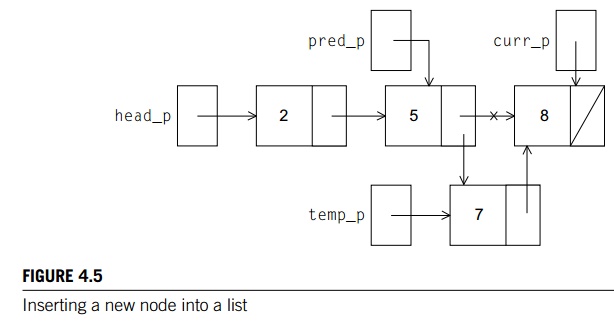
The Insert function (Program 4.10) begins by searching
for the correct position in which to insert the new node. Since the list is
sorted, it must search until it finds a node whose data member is greater than the value to be inserted. When it finds this node, it
needs to insert the new node in the position preceding the node that’s been found. Since the list is singly-linked, we
can’t “back up” to this position without traversing the list a second time.
There are several approaches to dealing with this: the approach we use is to
define a second pointer pred p, which, in general, refers to the predecessor
of the current node. When we exit the loop that searches for the position to
insert, the next member of the node referred to by pred
p can be updated so that it refers to the new
node. See Figure 4.5.
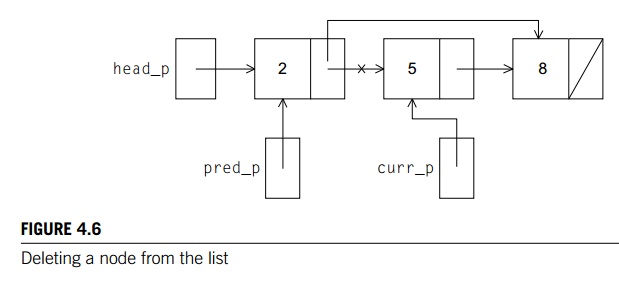
The Delete function (Program 4.11) is similar to the Insert function in that it also needs to keep track of the predecessor of
the current node while it’s searching for the node to be deleted. The
predecessor node’s next member can then be updated after the search is
completed. See Figure 4.6.
Program 4.10: The Insert function
int
Insert(int value, struct list_node_s**
head_p) {
struct list_node_s* curr_p = head
p;
struct list_node_s* pred_p = NULL;
struct
list_node_s* temp_p;
while
(curr_p != NULL && curr_p ->data < value) {
pred_p
= curr_p;
curr_p
= curr_p ->next;
}
if
(curr_p == NULL || curr p ->data >
value) {
temp_p
= malloc(sizeof(struct list_node_s));
temp_p
>data = value;
temp_p
>next = curr p;
if
(pred_p == NULL) /* New first node */
head_p
= temp_p;
else
pred_p
>next = temp_p;
return
1;
}
else { /* Value already in list */
return
0;
}
} /*
Insert */
2. A multithreaded linked list
Now let’s try to use these functions in a
Pthreads program. In order to share access to the list, we can define head p to be a global variable. This will simplify the function headers
for Member, Insert, and Delete, since we won’t need to pass in either head p or a pointer to head p, we’ll only need to pass in the value of
interest.
int
Delete(int value, struct list_node_s**
head p) {
struct
list_node_s* curr_p =
head_p;
struct
list node s * pred_p = NULL;
while
(curr_p != NULL && curr_p ->data < value) {
pred_p
= curr_p;
curr_p
= curr_p ->next;
}
if
(curr_p != NULL && curr_ p ->data == value) {
if
(pred_p == NULL) { /* Deleting first
node in list */
head_p
= curr_p ->next;
free(curr_p);
g
else f
pred_p
->next = curr_p ->next;
free(curr_p);
}
return
1;
}
else { /* Value isn’t in list */
return
0;
}
} /*
Delete */
What now are the consequences of having multiple
threads simultaneously execute the three functions?
Since multiple threads can simultaneously read a memory location without con-flict, it should
be clear that multiple threads can simultaneously execute Member. On the other hand, Delete and Insert also write to memory locations, so there may be problems if we try to execute
either of these operations at the same time as another operation. As an
example, suppose that thread 0 is executing Member (5) at the same time that thread 1 is
executing Delete (5). The current state of the list is shown in Figure 4.7. An
obvious problem is that if thread 0 is executing Member (5), it is going to report that 5 is in the
list, when, in fact, it may be deleted even before thread 0
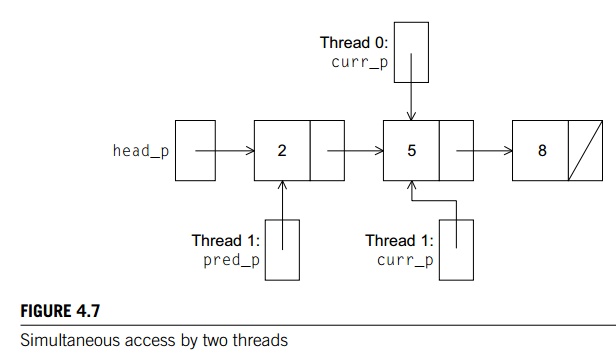
returns. A second obvious problem is if thread
0 is executing Member (8), thread 1 may free the memory used for the
node storing 5 before thread 0 can advance to the node storing 8. Although
typical implementations of free don’t overwrite the freed memory, if the memory
is reallocated before thread 0 advances, there can be serious problems. For
example, if the memory is reallocated for use in something other than a list
node, what thread 0 “thinks” is the next member may be set to utter garbage, and after
it executes
curr_p = curr_p >next;
dereferencing curr_p may result in a segmentation violation.
More generally, we can run into problems if we
try to simultaneously execute another operation while we’re executing an Insert or a Delete. It’s OK for multi-ple threads to
simultaneously execute Member—that is, read the list nodes—but it’s unsafe for multiple threads to access the
list if at least one of the threads is executing an Insert or a Delete—that is, is writing to the list nodes (see Exercise 4.11).
How can we deal with this problem? An obvious
solution is to simply lock the list any time that a thread attempts to access
it. For example, a call to each of the three functions can be protected by a
mutex, so we might execute
Pthread_mutex_lock(&list_mutex);
Member(value);
Pthread_mutex_unlock(&list_mutex);
instead of simply calling Member(value).
An equally obvious problem with this solution
is that we are serializing access to the list, and if the vast majority of our
operations are calls to Member, we’ll fail to exploit this opportunity for
parallelism. On the other hand, if most of our operations are calls to Insert and Delete, then this may be the best solution, since
we’ll need to serialize access to the list for most of the operations, and this
solution will certainly be easy to implement.
An alternative to this approach involves
“finer-grained” locking. Instead of lock-ing the entire list, we could try to
lock individual nodes. We would add, for example, a mutex to the list node
struct:
struct list_node_s
{ int data;
struct list_node_s* next;
pthread_mutex_t mutex;
}
Now each time we try to access a node we must
first lock the mutex associated with the node. Note that this will also require
that we have a mutex associated with the head p pointer. So, for example, we might implement Member as shown in Program 4.12. Admittedly this implementation is much more complex than the original Member function. It is also much slower, since, in general, each time a
node is accessed, a mutex must be locked and unlocked. At a minimum it will add
two function calls to the node access, but it can also add a substantial delay
if a thread has to wait for a lock. A further problem is that the addition of a
mutex field to each node will substantially increase the amount of storage
needed for the list. On the other hand, the finer-grained locking might be a
closer approximation to what we want. Since we’re only locking the nodes of
current interest, multiple threads can simul-taneously access different parts
of the list, regardless of which operations they’re executing.
Program 4.12: Implementation of Member with one mutex per list node

3. Pthreads read-write locks
Neither of our multithreaded linked lists
exploits the potential for simultaneous access to any node by threads that are executing Member. The first solution only allows one thread to
access the entire list at any instant, and the second only allows one thread to
access any given node at any instant. An alternative is provided by Pthreads’ read-write locks. A read-write lock is somewhat like a mutex
except that it provides two lock functions. The first lock function locks the
read-write lock for reading, while the second locks it for writing. Multiple threads can thereby simul-taneously obtain the lock by calling
the read-lock function, while only one thread can obtain the lock by calling
the write-lock function. Thus, if any threads own the lock for reading, any
threads that want to obtain the lock for writing will block in the call to the
write-lock function. Furthermore, if any thread owns the lock for writ-ing, any
threads that want to obtain the lock for reading or writing will block in their
respective locking functions.
Using Pthreads read-write locks, we can protect
our linked list functions with the following code (we’re ignoring function
return values):
pthread_rwlock_rdlock(&rwlock);
Member(value);
pthread_rwlock_unlock(&rwlock);
. . .
pthread_rwlock_wrlock(&rwlock);
Insert(value);
pthread_rwlock_unlock(&rwlock);
. . .
pthread_rwlock_wrlock(&rwlock);
Delete(value);
pthread_rwlock_unlock(&rwlock);
The syntax for the new Pthreads functions is
int pthread_rwlock_rdlock(pthread_rwlock_t∗ rwlock_p /∗ in/out ∗/);
int pthread_rwlock_wrlock(pthread_rwlock_t∗ rwlock_p /∗ in/out ∗/);
int pthread_rwlock_wrlock(pthread_rwlock_t∗ rwlock_p /∗ in/out ∗/);
As their names suggest, the first function
locks the read-write lock for reading, the second locks it for writing, and the
last unlocks it.
As with mutexes, read-write locks should be
initialized before use and destroyed after use. The following function can be
used for initialization:
int pthread_rwlock_init(
pthread_rwlock_t rwlock_p /*out */,
const pthread_rwlockattr_t attr_p /* in */);
Also as with mutexes, we’ll not use the second
argument, so we’ll just pass NULL. The following function can be used for
destruction of a read-write lock:
int pthread_rwlock_destroy(pthread_rwlock_t* rwlock_p /* in/out */);
4. Performance of the various
implementations
Of course, we really want to know which of the
three implementations is “best,” so we included our implementations in a small
program in which the main thread first inserts a user-specified number of
randomly generated keys into an empty list. After being started by the main
thread, each thread carries out a user-specified number of operations on the
list. The user also specifies the percentages of each type of oper-ation (Member, Insert, Delete). However, which operation occurs when and on which key is
determined by a random number generator. Thus, for example, the user might
specify that 1000 keys should be inserted into an initially empty list and a
total of 100,000 operations are to be carried out by the threads. Further, she
might specify that 80% of the operations should be Member, 15% should be Insert, and the remaining 5% should be Delete. However, since the operations are randomly generated, it might
happen that the threads execute a total of, say, 79,000 calls to Member, 15,500 calls to Insert, and 5500 calls to Delete.
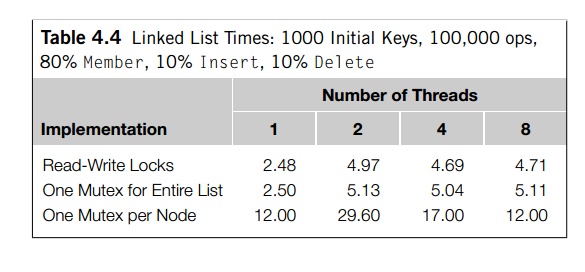
Tables 4.3 and 4.4 show the times (in seconds)
that it took for 100,000 operations on a list that was initialized to contain
1000 keys. Both sets of data were taken on a system containing four dual-core
processors.
Table 4.3 shows the times when 99.9% of the
operations are Member and the remaining 0.1% are divided equally
between Insert and Delete. Table 4.4 shows the times when 80% of the
operations are Member, 10% are Insert, and 10% are Delete. Note that in both tables when one thread is
used, the run-times for the
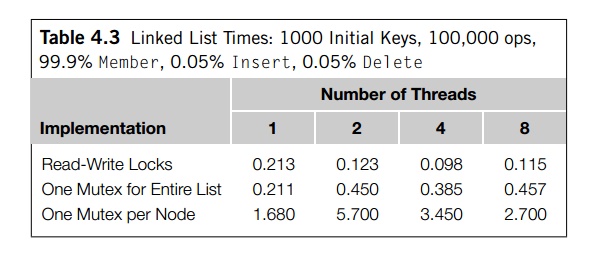
read-write locks and the single-mutex
implementations are about the same. This makes sense: the operations are
serialized, and since there is no contention for the read-write lock or the
mutex, the overhead associated with both implementations should consist of a
function call before the list operation and a function call after the
operation. On the other hand, the implementation that uses one mutex per node
is much slower. This also makes sense, since each time
a single node is accessed there will be two function calls—one to lock the node mutex and one to
unlock it. Thus, there’s considerably more overhead for this implementation.
The inferiority of the implementation that uses
one mutex per node persists when we use multiple threads. There is far too much
overhead associated with all the locking and unlocking to make this
implementation competitive with the other two implementations.
Perhaps the most striking difference between
the two tables is the relative perfor-mance of the read-write lock
implementation and the single-mutex implementation when multiple threads are
used. When there are very few Inserts and Deletes, the read-write lock implementation is far
better than the single-mutex implementation. Since the single-mutex
implementation will serialize all the operations, this suggests that if there
are very few Inserts and Deletes, the read-write locks do a very good job of
allowing concurrent access to the list. On the other hand, if there are a
relatively large number of Inserts and Deletes (for example, 10% each), there’s very little
difference between the performance of the read-write lock implementation and
the single-mutex implementation. Thus, for linked list operations, read-write
locks can provide a considerable increase in performance,
but only if the number of Inserts and Deletes is quite small.
Also notice that if we use one mutex or one
mutex per node, the program is always as fast or faster when it’s run with one thread. Furthermore, when
the number of inserts and deletes is relatively large, the read-write lock
program is also faster with one thread. This isn’t surprising for the one mutex
implemen-tation, since effectively accesses to the list are serialized. For the
read-write lock implementation, it appears that when there are a substantial
number of write-locks, there is too much contention for the locks and overall
performance deteriorates significantly.
In summary, the read-write lock implementation
is superior to the one mutex and the one mutex per node implementations. However,
unless the number of inserts and deletes is small, a serial implementation will be
superior.
5. Implementing read-write locks
The original Pthreads specification didn’t
include read-write locks, so some of the early texts describing Pthreads include
implementations of read-write locks (see, for example, [6]). A typical
implementation6 defines a data structure that uses two condi-tion
variables—one for “readers” and one for “writers”—and a mutex. The structure
also contains members that indicate
how many
readers own the lock, that is, are currently reading,
how many
readers are waiting to obtain the lock,
whether
a writer owns the lock, and
how many
writers are waiting to obtain the lock.
The mutex protects the read-write lock data
structure: whenever a thread calls one of the functions (read-lock, write-lock,
unlock), it first locks the mutex, and whenever a thread completes one of these
calls, it unlocks the mutex. After acquiring the mutex, the thread checks the
appropriate data members to determine how to proceed. As an example, if it
wants read-access, it can check to see if there’s a writer that currently owns
the lock. If not, it increments the number of active readers and proceeds. If a
writer is active, it increments the number of readers waiting and starts a
condition wait on the reader condition variable. When it’s awakened, it
decrements the number of readers waiting, increments the number of active
readers, and proceeds. The write-lock function has an implementation that’s
similar to the read-lock function.
The action taken in the unlock function depends
on whether the thread was a reader or a writer. If the thread was a reader,
there are no currently active readers, and there’s a writer waiting, then it can signal a writer to proceed
before returning. If, on the other hand, the thread was a writer, there can be both
readers and writers waiting, so the thread needs to decide whether it will give
preference to readers or writers. Since writers must have exclusive access, it
is likely that it is much more difficult for a writer to obtain the lock. Many
implementations therefore give writers preference. Programming Assignment 4.6
explores this further.
Related Topics