Chapter: An Introduction to Parallel Programming : Shared-Memory Programming with Pthreads
Matrix-Vector Multiplication
MATRIX-VECTOR MULTIPLICATION
Let’s take a look at writing a Pthreads
matrix-vector multiplication program. Recall that if A = (aij) is an mx n matrix and x = (x0, x1, ...., xn-1)T is an n-dimensional column vector, then the
matrix-vector product Ax = y is an m-dimensional column vector, y = (y0, y1, …., ym-1)T in
which the ith component yi is obtained by finding
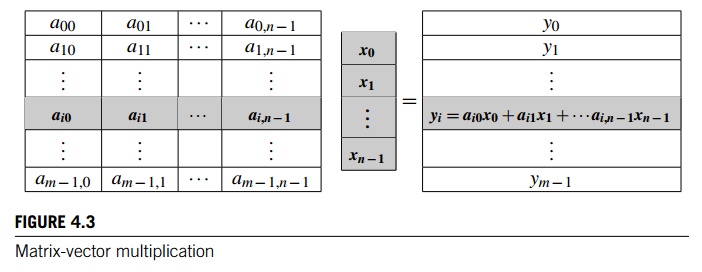

We want to parallelize this by dividing the
work among the threads. One pos-sibility is to divide the iterations of the
outer loop among the threads. If we do this, each thread will compute some of
the components of y. For example, suppose that m = n = 6 and the number of threads, thread
count or t, is three. Then the computation could be divided among the threads
as follows:

To compute y[0], thread 0 will need to execute the code
y[0] = 0.0;
for (j = 0; j < n; j++)
y[0] += A[0][j] *x[j];
Thread 0 will therefore need to access every
element of row 0 of A and every element of x. More generally, the thread that has been assigned y[i] will need to execute the code
y[i] = 0.0;
for (j = 0; j < n; j++) y[i] += A[i][j]* x[j];
Thus, this thread will need to access every
element of row i of A and every element of x. We see that each thread needs to access every component of x, while each thread only needs to access its assigned rows of A and assigned components of y. This suggests that, at a minimum, x should be shared. Let’s also make A and y shared. This might seem to violate our
principle that we should only make variables global that need to be global.
However, in the exercises, we’ll take a closer look at some of the issues
involved in making the A and y variables local to the thread function, and
we’ll see that making them global can make good sense. At this point, we’ll
just observe that if they are global, the main thread can easily initialize all
of A by just reading its entries from stdin, and the product vector y can be easily printed by the main thread.
Having made these decisions, we only need to
write the code that each thread will use for deciding which components of y it will compute. In order to simplify the code, let’s assume that
both m and n are evenly divisible by t. Our example with m = 6 and t =
3 suggests that each thread gets m/t components. Furthermore, thread 0 gets the first m/t, thread 1 gets the next m/t, and so on. Thus, the formulas for the components assigned to
thread q might be

With these formulas, we can write the thread
function that carries out matrix-vector multiplication. See Program 4.2. Note
that in this code, we’re assuming that A, x, y, m, and n are all global and shared.
Program 4.2: Pthreads matrix-vector multiplication
void Pth_mat_vect(void* rank) { long my_rank =
(long) rank; int i, j;
int local_m = m/thread_count;
int my_first_row = my_rank *local_m;
int my_last_row = (my_rank+1)*local_m-1;
for (i = my_first_row; i <= my last_row;
i++) {
y[i] = 0.0;
for (j = 0; j < n; j++)
y[i] += A[i][j]*x[j];
}
return NULL;
} /* Pth_mat_vect */
If you have already read the MPI chapter, you
may recall that it took more work to write a matrix-vector multiplication
program using MPI. This was because of the fact that the data structures were
necessarily distributed, that is, each MPI process only has direct access to
its own local memory. Thus, for the MPI code, we need to explicitly gather all of x into each process’ memory. We see from this
example that there are instances in which writing shared-memory programs is
easier than writing distributed-memory programs. However, we’ll shortly see
that there are situations in which shared-memory programs can be more complex.
Related Topics