Chapter: An Introduction to Parallel Programming : Shared-Memory Programming with Pthreads
Mutexes
MUTEXES
Since a thread that is busy-waiting may
continually use the CPU, busy-waiting is generally not an ideal solution to
the problem of limiting access to a critical section. Two better solutions are
mutexes and semaphores. Mutex is an abbreviation of mutual exclusion, and a mutex is a special type of variable that, together with a
couple of special functions, can be used to restrict
access to a critical section to a single thread at a time. Thus, a mutex can be
used to guarantee that one thread “excludes” all other threads while it
executes the critical section. Hence, the mutex guarantees mutually exclusive
access to the critical section.
The Pthreads standard includes a special type
for mutexes: pthread mutex t. A variable of type pthread
mutex t needs to be initialized by the system before
it’s used. This can be done with a call to
int pthread_mutex_init(
pthread_mutex_t mutex_p /*out */,
const pthread_mutexattr_t attr_p /* in */);
We won’t make use of the second argument, so we’ll
just pass in NULL. When a Pthreads program finishes using a mutex, it should
call
int pthread_mutex_destroy(pthread_mutex_t* mutex_p /* in/out */);
To gain access to a critical section, a thread
calls
int pthread_mutex_lock(pthread_mutex_t* mutex_p /* in/out */);
When a thread is finished executing the code in
a critical section, it should call
int pthread mutex unlock(pthread_mutex_t* mutex_p
/* in/out */);
The call to pthread
mutex lock will cause the thread to
wait until no other thread is in the critical section, and the call to pthread mutex unlock notifies the system that the calling thread
has completed execution of the code in the critical section.
We can use mutexes instead of busy-waiting in
our global sum program by declar-ing a global mutex variable, having the main
thread initialize it, and then, instead of busy-waiting and incrementing a
flag, the threads call pthread mutex lock before entering the critical section, and they
call pthread mutex unlock when they’re done with the critical section.
See Program 4.6. The first thread to call pthread
mutex lock will, effectively, “lock the
door” to the critical section. Any other thread that attempts to execute the
critical section code must first also call pthread
mutex lock, and until the first thread
calls pthread mutex unlock, all the threads that have called pthread mutex lock will block in their calls—they’ll just wait until the first thread is done.
After the first thread calls pthread mutex unlock, the system will choose one of the blocked
threads and allow it to execute the code in the critical section. This process
will be repeated until all the threads have completed executing the critical
section.
“Locking” and “unlocking” the door to the
critical section isn’t the only metaphor that’s used in connection with
mutexes. Programmers often say that the thread that has returned from a call to
pthread mutex lock has “obtained the mutex” or “obtained the
lock.” When this terminology is used, a thread that calls pthread mutex unlock “relinquishes” the mutex or lock.
Program 4.6: Global sum function that uses a mutex
void Thread_sum(void rank) {
long
my_rank = (long) rank;
double
factor;
long
long i;
long
long_my_n = n/thread_count;
long long my_first_i
= my_n*my_rank;
long long my_last_i
= my_first_i + my_n;
double
my_sum = 0.0;
if
(my_first_i % 2 == 0)
factor
= 1.0;
else
factor
= -1.0;
for
(i = my_first_i; i < my_last_i; i++, factor = -factor) {
my_sum
+= factor/(2*i+1);
}
pthread_mutex_lock(&mutex);
sum
+= my_sum;
pthread_mutex_unlock(&mutex);
return
NULL;
} /*
Thread sum */
Notice that with mutexes (unlike our
busy-waiting solution), the order in which the threads execute the code in the
critical section is more or less random: the first thread to call pthread_mutex_lock will be the first to execute the code in the critical section.
Subsequent accesses will be scheduled by the system. Pthreads doesn’t
guar-antee (for example) that the threads will obtain the lock in the order in
which they called Pthread_mutex_lock. However, in our setting, only finitely many
threads will try to acquire the lock. Eventually each thread will obtain the
lock.
If we look at the (unoptimized) performance of
the busy-wait program (with the critical section after the loop) and the mutex
program, we see that for both ver-sions the ratio of the run-time of the
single-threaded program with the multithreaded program is equal to the number
of threads, as long as the number of threads is no greater than the number of
cores. (See Table 4.1.) That is,

provided thread_count is less than or equal to the number of cores.
Recall that Tserial=Tparallel is called the speedup, and when the speedup is equal to the number of threads, we have achieved more or less “ideal”
performance or linear speedup.
If we compare the performance of the version
that uses busy-waiting with the version that uses mutexes, we don’t see much
difference in the overall run-time when the programs are run with fewer threads
than cores. This shouldn’t be surprising,
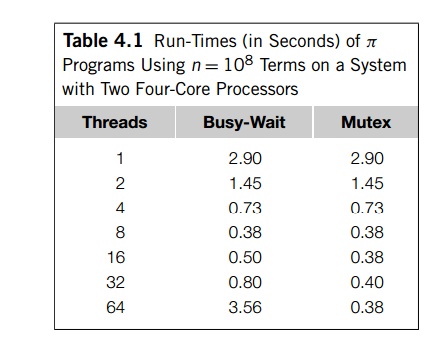
as each thread only enters the critical section
once; so unless the critical section is very long, or the Pthreads functions
are very slow, we wouldn’t expect the threads to be delayed very much by
waiting to enter the critical section. However, if we start increasing the
number of threads beyond the number of cores, the performance of the version
that uses mutexes remains pretty much unchanged, while the performance of the
busy-wait version degrades.
We see that when we use busy-waiting,
performance can degrade if there are more threads than cores.4 This
should make sense. For example, suppose we have two cores and five threads.
Also suppose that thread 0 is in the critical section, thread 1 is in the
busy-wait loop, and threads 2, 3, and 4 have been descheduled by the operating
system. After thread 0 completes the critical section and sets flag = 1, it will be terminated, and thread 1 can enter the critical
section so the operating system can schedule thread 2, thread 3, or thread 4.
Suppose it schedules thread 3, which will spin in the while loop. When thread 1 finishes the critical
section and sets flag = 2, the operating system can schedule thread 2 or
thread 4. If it schedules thread 4, then both thread 3 and thread 4, will be busily
spinning in the busy-wait loop until the operating system deschedules one of
them and schedules thread 2. See Table 4.2.
Related Topics