Chapter: Fundamentals of Database Systems : File Structures, Indexing, and Hashing : Disk Storage, Basic File Structures, and Hashing
Placing File Records on Disk
Placing File Records on Disk
In this section, we define the concepts of records, record types, and
files. Then we discuss techniques for placing file records on disk.
1. Records and Record
Types
Data is usually stored in the form of records. Each record consists of a collection of related data values or items, where each value is formed of one or more bytes and
corresponds to a particular field of
the record. Records usually describe entities and their attributes. For
example, an EMPLOYEE record represents an employee entity, and each field value in the
record specifies some attribute of that employee, such as Name,
Birth_date, Salary, or Supervisor. A collection of field names and their corresponding data types
constitutes a record type or record format definition. A data type, associated with each field, specifies the types of values a
field can take.
The data type of a field is usually one of the standard data types used
in programming. These include numeric (integer, long integer, or floating
point), string of characters (fixed-length or varying), Boolean (having 0 and 1
or TRUE and FALSE values only), and sometimes specially coded date and time data
types. The number of bytes required for each data type is fixed for a given
computer system. An integer may require 4 bytes, a long integer 8 bytes, a real
number 4 bytes, a Boolean 1 byte, a date 10 bytes (assuming a format of
YYYY-MM-DD), and a fixed-length string of k
characters k bytes.
Variable-length strings may require as many bytes as there are characters in each field value. For
example, an EMPLOYEE record type may be defined—using the C programming language notation—as
the following structure:
struct
employee{
char
name[30];
char
ssn[9];
int
salary;
int
job_code;
char
department[20];
}
;
In some database applications, the need may arise for storing data items
that consist of large unstructured objects, which represent images, digitized
video or audio streams, or free text. These are referred to as BLOBs (binary large objects). A BLOB
data item is typically stored separately from its record in a pool of disk
blocks, and a pointer to the BLOB is included in the record.
2. Files, Fixed-Length Records, and Variable-Length Records
A file is a sequence of records. In many cases, all
records in a file are of the same record type. If every record in the file has
exactly the same size (in bytes), the file is said to be made up of fixed-length records. If different
records in the file have different sizes, the file is said to be made up of variable-length records. A file may
have variable-length records for several reasons:
The file records are of the same
record type, but one or more of the fields are of varying size (variable-length fields). For example,
the Name field of EMPLOYEE
can be a variable-length field.
The file records are of the same
record type, but one or more of the fields
may have multiple values for individual records; such a field is called
a repeating field and a group of
values for the field is often called a
repeating group.
The file records are of the same record type, but one or more of the
fields are optional; that is, they
may have values for some but not all of the file records (optional fields).
The file contains records of different record types and hence of
varying size (mixed file). This
would occur if related records of different types were clustered (placed together) on disk blocks; for example, the GRADE_REPORT records
of a particular student may be placed following that STUDENT’s record.
The fixed-length EMPLOYEE records in Figure 17.5(a) have a
record size of 71 bytes. Every record has the same fields, and field lengths
are fixed, so the system can identify the starting byte position of each field
relative to the starting position of the record. This facilitates locating
field values by programs that access such files. Notice that it is possible to
represent a file that logically should have variable-length records as a
fixed-length records file. For example, in the case of optional fields, we
could have every field included in every file record but store a special NULL value if no value exists for that field. For a repeating field, we
could allocate as many spaces in each record as the maximum possible number of occurrences of the field. In either
case, space is wasted when certain records do not have values for all the
physical spaces provided in each record. Now we consider other options for
formatting records of a file of variable-length records.
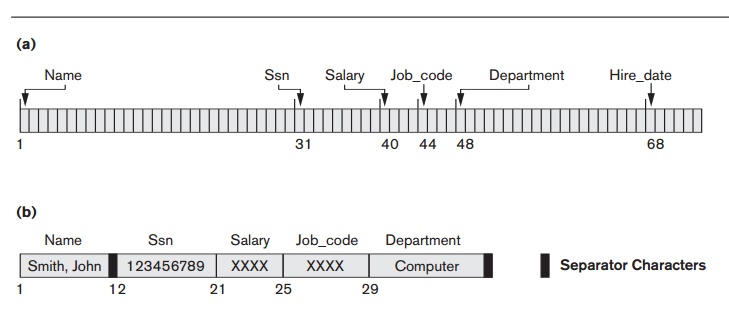

For variable-length fields,
each record has a value for each field, but we do not know the exact length of
some field values. To determine the bytes within a particular record that
represent each field, we can use special separator
characters (such as ? or % or $)—which do not appear in any field value—to
terminate variable-length fields, as shown in Figure 17.5(b), or we can store
the length in bytes of the field in the record, preceding the field value.
A file of records with optional
fields can be formatted in different ways. If the total number of fields
for the record type is large, but the number of fields that actually appear in
a typical record is small, we can include in each record a sequence of
<field-name, field-value> pairs rather than just the field values. Three
types of separator characters are used in Figure 17.5(c), although we could
use the same separator character for the first two purposes—separating the
field name from the field value and separating one field from the next field. A
more practical option is to assign a short field
type code—say, an integer number—to each field and include in each record a
sequence of <field-type, field-value> pairs rather than <field-name,
field-value> pairs.
A repeating field needs one separator character to separate the repeating values of the field and another separator character to indicate termination of the field. Finally, for a file that includes records of different types, each record is preceded by a record type indicator. Understandably, programs that process files of variable-length records—which are usually part of the file system and hence hidden from the typical programmers—need to be more complex than those for fixed-length records, where the starting position and size of each field are known and fixed.
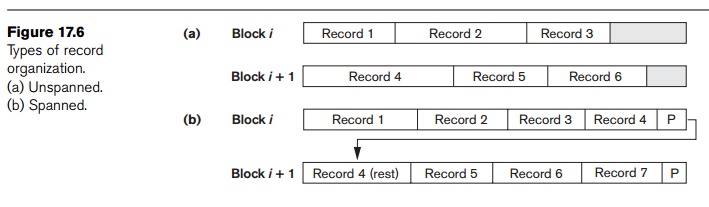
3. Record Blocking and Spanned versus Unspanned Records
The records of a file must be allocated to disk blocks because a block
is the unit of data transfer between disk and memory. When the block size is
larger than the record size, each
block will contain numerous records, although some files may have unusually
large records that cannot fit in one block. Suppose that the block size is B bytes. For a file of fixed-length
records of size R bytes, with B ≥ R, we can fit bfr = B/R records per block, where the (x) (floor
function) rounds down the number x to an integer. The value bfr is called the blocking factor for the file. In general, R may not divide B
exactly, so we have some unused space in each block equal to
B − (bfr * R) bytes
To utilize this unused space, we can store part of a record on one block
and the rest on another. A pointer
at the end of the first block points to the block containing the remainder of
the record in case it is not the next consecutive block on disk. This
organization is called spanned
because records can span more than one block. Whenever a record is larger than
a block, we must use a spanned
organization. If records are not allowed to cross block boundaries, the
organization is called unspanned.
This is used with fixed-length records having B > R
because it makes each record start at a known location in the block,
simplifying record processing. For variable-length records, either a spanned or
an unspanned organization can be used. If the average record is large, it is
advantageous to use spanning to reduce the lost space in each block. Figure
17.6 illustrates spanned versus unspanned organization.
For variable-length records using spanned organization, each block may
store a different number of records. In this case, the blocking factor bfr represents the average number of records per block for the file. We can use bfr to calculate the number of blocks b needed for a file of r records:
b = (r/bfr) blocks
where the (x) (ceiling function) rounds the value x up to the next integer.
4. Allocating File Blocks
on Disk
There are several standard techniques for allocating the blocks of a
file on disk. In contiguous allocation,
the file blocks are allocated to consecutive disk blocks. This makes reading the whole file very fast
using double buffering, but it makes expanding the file difficult. In linked allocation, each file block
contains a pointer to the next file block. This makes it easy to expand the
file but makes it slow to read the whole file. A combination of the two
allocates clusters of consecutive
disk blocks, and the clusters are linked. Clusters are sometimes called file segments or extents. Another possibility is to use indexed allocation, where one or more index blocks contain pointers to the actual file blocks. It is also
common to use combinations of these techniques.
5. File Headers
A file header or file descriptor contains information
about a file that is needed by the system programs that access the file
records. The header includes information to determine the disk addresses of the
file blocks as well as to record format descriptions, which may include field
lengths and the order of fields within a record for fixed-length unspanned
records and field type codes, separator characters, and record type codes for
variable-length records.
To search for a record on disk, one or more blocks are copied into main
memory buffers. Programs then search for the desired record or records within
the buffers, using the information in the file header. If the address of the
block that contains the desired record is not known, the search programs must
do a linear search through
the file blocks. Each file block is copied into a buffer and searched
until the record is located or all the file blocks have been searched
unsuccessfully. This can be very time-consuming for a large file. The goal of a
good file organization is to locate the block that contains a desired record
with a minimal number of block transfers.
Related Topics