Chapter: Fundamentals of Database Systems : File Structures, Indexing, and Hashing : Disk Storage, Basic File Structures, and Hashing
Parallelizing Disk Access Using RAID Technology
Parallelizing Disk Access Using RAID Technology
With the exponential growth in the performance and capacity of
semiconductor devices and memories, faster microprocessors with larger and
larger primary memories are continually becoming available. To match this
growth, it is natural to expect that secondary storage technology must also
take steps to keep up with processor technology in performance and reliability.
A major advance in secondary storage technology is represented by the
development of RAID, which
originally stood for Redundant Arrays of
Inexpensive Disks. More recently, the I
in RAID is said to stand for Independent. The RAID idea received a very
positive industry endorsement and has been developed into an elab-orate set of
alternative RAID architectures (RAID levels 0 through 6). We highlight the main
features of the technology in this section.
The main goal of RAID is to even out the widely different rates of
performance improvement of disks against those in memory and microprocessors. While RAM capacities have
quadrupled every two to three years, disk access
times are improving at less than 10 percent per year, and disk transfer rates are improving at roughly
20 percent per year. Disk capacities
are indeed improving at more than 50 percent per year, but the speed and access
time improvements are of a much smaller magnitude.
A second qualitative disparity exists between the ability of special
microprocessors that cater to new applications involving video, audio, image,
and spatial data processing (see Chapters 26 and 30 for details of these
applications), with corresponding lack of fast access to large, shared data
sets.
The natural solution is a large array of small independent disks acting
as a single higher-performance logical disk. A concept called data striping is used, which utilizes parallelism to improve disk performance.
Data striping distributes data transparently over multiple disks to make them
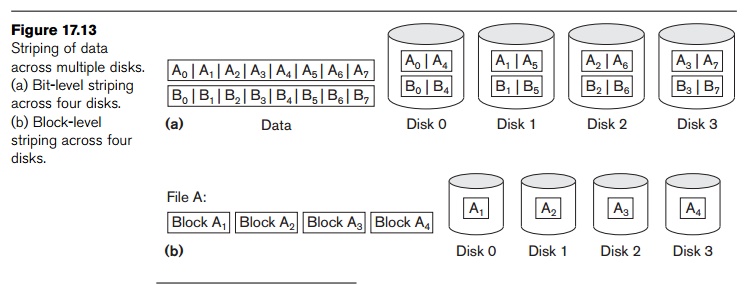
appear as a single large, fast disk. Figure 17.13 shows a file distributed or striped over four disks. Striping
improves overall I/O performance by allowing multiple I/Os to be serviced in
parallel, thus providing high overall transfer rates. Data striping also
accomplishes load balancing among disks. Moreover, by storing redundant
information on disks using parity or some other error-correction code,
reliability can be improved. In Sections 17.10.1 and
17.10.2, we discuss how RAID achieves the two important objectives of
improved reliability and higher performance. Section 17.10.3 discusses RAID
organizations and levels.
1. Improving
Reliability with RAID
For an array of n disks, the
likelihood of failure is n times as
much as that for one disk. Hence, if the MTBF (Mean Time Between Failures) of a
disk drive is assumed to be 200,000 hours or about 22.8 years (for the disk
drive in Table 17.1 called Cheetah NS, it is 1.4 million hours), the MTBF for a
bank of 100 disk drives becomes only 2,000 hours or 83.3 days (for 1,000
Cheetah NS disks it would be 1,400 hours or 58.33 days). Keeping a single copy
of data in such an array of disks will cause a significant loss of
reliability. An obvious solution is to employ redundancy of data so that disk
failures can be tolerated. The disadvantages are many: additional I/O
operations for write, extra computation to maintain redundancy and to do
recovery from errors, and additional disk capacity to store redundant
information.
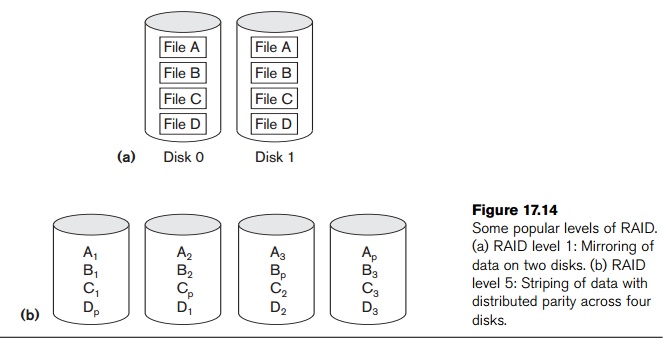
One technique for introducing redundancy is called mirroring or shadowing.
Data is written redundantly to two identical physical disks that are treated as
one logical disk. When data is read, it can be retrieved from the disk with
shorter queuing, seek, and rotational delays. If a disk fails, the other disk
is used until the first is repaired. Suppose the mean time to repair is 24
hours, then the mean time to data loss of a mirrored disk system using 100
disks with MTBF of 200,000 hours each is (200,000)2/(2 * 24) = 8.33 * 108 hours, which is 95,028 years.13 Disk mirroring also doubles the
rate at which read requests are handled, since a read can go to either disk.
The transfer rate of each read, however, remains the same as that for a single
disk.
Another solution to the problem of reliability is to store extra
information that is not normally needed but that can be used to reconstruct the
lost information in case of disk failure. The incorporation of redundancy must
consider two problems: selecting a technique for computing the redundant
information, and selecting a method of distributing the redundant information
across the disk array. The first problem is addressed by using error-correcting
codes involving parity bits, or specialized codes such as Hamming codes. Under
the parity scheme, a redundant disk may be considered as having the sum of all
the data in the other disks. When a disk fails, the missing information can be
constructed by a process similar to subtraction.
For the second problem, the two major approaches are either to store the
redundant information on a small number of disks or to distribute it uniformly
across all disks. The latter results in better load balancing. The different
levels of RAID choose a combination of these options to implement redundancy
and improve reliability.
2. Improving
Performance with RAID
The disk arrays employ the technique of data striping to achieve higher
transfer rates. Note that data can be read or written only one block at a time,
so a typical transfer contains 512 to 8192 bytes. Disk striping may be applied
at a finer granularity by breaking up a byte of data into bits and spreading
the bits to different disks. Thus, bit-level
data striping consists of splitting a byte of data and writing bit j to the jth disk. With 8-bit bytes, eight physical disks may be considered as
one logical disk with an eightfold increase in the data transfer rate. Each
disk participates in each I/O request and the total amount of data read per
request is eight times as much. Bit-level striping can be generalized to a
number of disks that is either a multiple or a factor of eight. Thus, in a
four-disk array, bit n goes to the
disk which is (n mod 4). Figure
17.13(a) shows bit-level striping of data.
The granularity of data interleaving can be higher than a bit; for
example, blocks of a file can be striped across disks, giving rise to block-level striping. Figure 17.13(b)
shows block-level data striping assuming the data file contains four blocks.
With block-level striping, multiple independent requests that access single
blocks (small requests) can be serviced in parallel by separate disks, thus
decreasing the queuing time of I/O requests. Requests that access multiple
blocks (large requests) can be parallelized, thus reducing their response time.
In general, the more the number of disks in an array, the larger the potential
performance benefit. However, assuming independent failures, the disk array of
100 disks collectively has 1/100th the reliability of a single disk. Thus,
redundancy via error-correcting codes and disk mirroring is necessary to
provide reliability along with high performance.
3. RAID Organizations
and Levels
Different RAID organizations were defined based on different
combinations of the two factors of granularity of data interleaving (striping)
and pattern used to compute redundant information. In the initial proposal,
levels 1 through 5 of RAID were proposed, and two additional levels—0 and
6—were added later.
RAID level 0 uses data striping, has no redundant data, and hence has
the best write performance since updates do not have to be duplicated. It
splits data evenly across two or more disks. However, its read performance is
not as good as RAID level 1, which uses mirrored disks. In the latter,
performance improvement is possible by scheduling a read request to the disk
with shortest expected seek and rotational delay. RAID level 2 uses
memory-style redundancy by using Hamming codes, which contain parity bits for
distinct overlapping subsets of components. Thus, in one particular version of
this level, three redundant disks suffice for four original disks, whereas with
mirroring—as in level 1—four would be required. Level 2 includes both error
detection and correction, although detection is generally not required because
broken disks identify themselves.
RAID level 3 uses a single parity disk relying on the disk controller to
figure out which disk has failed. Levels 4 and 5 use block-level data striping,
with level 5 distributing data and parity information across all disks. Figure
17.14(b) shows an illustration of RAID level 5, where parity is shown with
subscript p. If one disk fails, the missing data is calculated based on the
parity available from the remaining disks. Finally, RAID level 6 applies the
so-called P + Q redundancy scheme using Reed-Soloman codes to protect against up
to two disk failures by using just two redundant disks.
Rebuilding in case of disk failure is easiest for RAID level 1. Other
levels require the reconstruction of a failed disk by reading multiple disks.
Level 1 is used for critical applications such as storing logs of transactions.
Levels 3 and 5 are preferred for large volume storage, with level 3 providing
higher transfer rates. Most popular use of RAID technology currently uses level
0 (with striping), level 1 (with mirroring), and level 5 with an extra drive
for parity. A combination of multiple RAID levels are also used – for example,
0+1 combines striping and mirroring using a minimum of four disks. Other
nonstandard RAID levels include: RAID 1.5, RAID 7, RAID-DP, RAID S or Parity
RAID, Matrix RAID, RAID-K, RAID-Z, RAIDn, Linux MD RAID 10, IBM ServeRAID 1E,
and unRAID. A discussion of these nonstandard levels is beyond the scope of
this book. Designers of a RAID setup for a given application mix have to
confront many design decisions such as the level of RAID, the number of disks,
the choice of parity schemes, and grouping of disks for block-level striping.
Detailed performance studies on small reads and writes (referring to I/O
requests for one striping unit) and large reads and writes (referring to I/O
requests for one stripe unit from each disk in an error-correction group) have
been performed.
Related Topics