Chapter: Fundamentals of Database Systems : File Structures, Indexing, and Hashing : Disk Storage, Basic File Structures, and Hashing
External Hashing for Disk Files
External Hashing for Disk
Files
Hashing
for disk files is called external
hashing. To suit the characteristics of disk storage, the target address
space is made of buckets, each of
which holds multiple records. A bucket is either one disk block or a cluster of
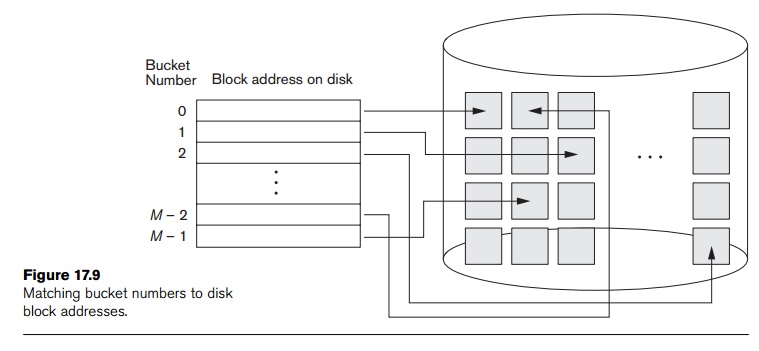
contiguous disk blocks. The hashing function maps a key into a relative bucket
number, rather than assigning an absolute block address to the bucket. A table
maintained in the file header converts the bucket number into the corresponding
disk block address, as illustrated in Figure 17.9.
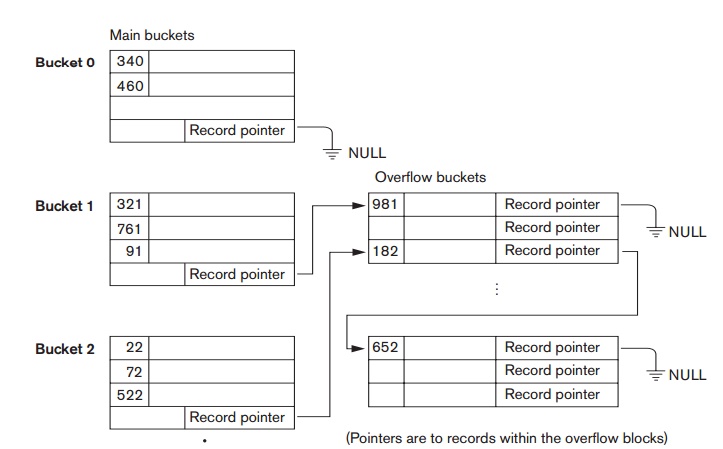
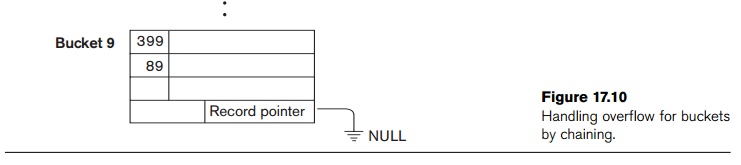
The collision
problem is less severe with buckets, because as many records as will fit in a
bucket can hash to the same bucket without causing problems. However, we must
make provisions for the case where a bucket is filled to capacity and a new
record being inserted hashes to that bucket. We can use a variation of chaining
in which a pointer is maintained in each bucket to a linked list of overflow
records for the bucket, as shown in Figure 17.10. The pointers in the linked
list should be record pointers,
which include both a block address and a relative record position within the block.
Hashing
provides the fastest possible access for retrieving an arbitrary record given
the value of its hash field. Although most good hash functions do not maintain
records in order of hash field values, some functions—called order preserving— do. A simple example
of an order preserving hash function is to take the leftmost three digits of an
invoice number field that yields a bucket address as the hash address and keep
the records sorted by invoice number within each bucket. Another
example
is to use an integer hash key directly as an index to a relative file, if the
hash key values fill up a particular interval; for example, if employee numbers
in a company are assigned as 1, 2, 3, ... up to the total number of employees,
we can use the identity hash function that maintains order. Unfortunately, this
only works if keys are generated in order by some application.
The
hashing scheme described so far is called static
hashing because a fixed number of buckets M is allocated. This can be a serious drawback for dynamic files.
Suppose that we allocate M buckets
for the address space and let m be
the maximum number of records that can fit in one bucket; then at most (m * M) records will fit in the allocated space. If the number of
records turns out to be substantially fewer than (m * M), we are
left with a lot of unused space. On the other hand, if the number of records
increases to substantially more than (m
* M), numerous collisions
will result and retrieval will be slowed down because of the long lists of
overflow records. In either case, we may have to change the number of blocks M allocated and then use a new hashing
function (based on the new value of M)
to redistribute the records. These reorganizations can be quite time-consuming
for large files. Newer dynamic file organizations based on hashing allow the
number of buckets to vary dynamically with only localized reorganization (see
Section 17.8.3).
When using
external hashing, searching for a record given a value of some field other than
the hash field is as expensive as in the case of an unordered file. Record
deletion can be implemented by removing the record from its bucket. If the
bucket has an overflow chain, we can move one of the overflow records into the
bucket to replace the deleted record. If the record to be deleted is already in
overflow, we sim-ply remove it from the linked list. Notice that removing an
overflow record implies that we should keep track of empty positions in
overflow. This is done easily by maintaining a linked list of unused overflow
locations.
Modifying
a specific record’s field value depends on two factors: the search condition
to locate that specific record and the field to be modified. If the search
condition is an equality comparison on the hash field, we can locate the
record efficiently by using the hashing function; otherwise, we must do a
linear search. A nonhash field can be modified by changing the record and
rewriting it in the same bucket. Modifying the hash field means that the record
can move to another bucket, which requires deletion of the old record followed
by insertion of the modified record.
Related Topics