Chapter: Fundamentals of Database Systems : File Structures, Indexing, and Hashing : Disk Storage, Basic File Structures, and Hashing
Files of Ordered Records (Sorted Files)
Files of Ordered Records (Sorted Files)
We can physically order the records of a file on disk based on the
values of one of their fields—called the ordering
field. This leads to an ordered
or sequential file. If the ordering field is also a key field of the file—a field
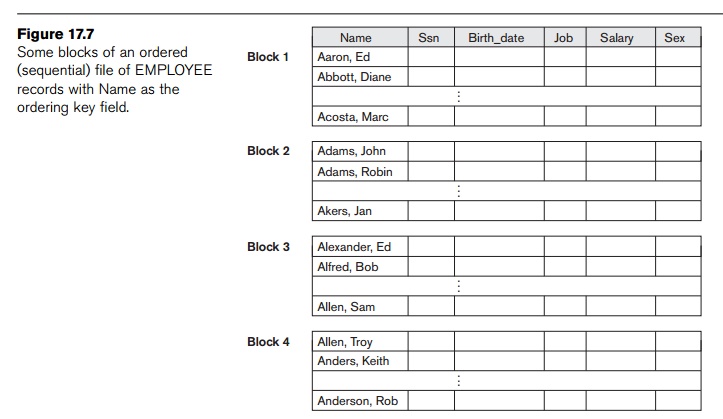
guaranteed to have a unique value in each record—then the field is called the ordering key for the file. Figure 17.7
shows an ordered file with Name as the ordering key field
(assuming that employees have distinct names).
Ordered records have some advantages over unordered files. First,
reading the records in order of the ordering key values becomes extremely
efficient because no sorting is required. Second, finding the next record from
the current one in order of the order-ing key usually requires no additional
block accesses because the next record is in the same block as the current one
(unless the current record is the last one in the block). Third, using a search
condition based on the value of an ordering key field results in faster access
when the binary search technique is used, which constitutes an improve-ment
over linear searches, although it is not often used for disk files. Ordered
files are blocked and stored on contiguous cylinders to minimize the seek time.
A binary search for disk
files can be done on the blocks rather than on the records. Suppose that the
file has b blocks numbered 1, 2, ...,
b; the records are ordered by
ascending value of their ordering key field; and we are searching for a record
whose ordering key field value is K.
Assuming that disk addresses of the file blocks are avail-able in the file
header, the binary search can be described by Algorithm 17.1. A binary search
usually accesses log2(b) blocks, whether the record
is found or not—an improvement over linear searches, where, on the average, (b/2) blocks are accessed when the record
is found and b blocks are accessed
when the record is not found.
Algorithm 17.1. Binary Search on an Ordering Key of a Disk File
l ← 1; u ← b; (* b is the number of file blocks *) while (u ≥ l ) do
begin i ← (l + u) div 2;
read block i of the file into
the buffer;
if K < (ordering key field
value of the first record in block i ) then u ← i – 1
else if K > (ordering key
field value of the last record in
block i ) then l ← i + 1
else if the record with ordering key field value = K is in the buffer then goto found
else goto notfound; end;
goto notfound;
A search criterion involving the conditions >, <, ≥, and ≤ on the ordering field is quite efficient, since the physical ordering
of records means that all records satisfying the condition are contiguous in
the file. For example, referring to Figure 17.7, if the search criterion is (Name < ‘G’)—where < means alphabetically
before— the records satisfying the search criterion are those from the
beginning of the file up to the first record that has a Name value starting with the letter ‘G’.
Ordering does not provide any advantages for random or ordered access of
the records based on values of the other nonordering
fields of the file. In these cases, we do a linear search for random
access. To access the records in order based on a nonordering field, it is
necessary to create another sorted copy—in a different order—of the file.
Inserting and deleting records are expensive operations for an ordered
file because the records must remain physically ordered. To insert a record, we
must find its cor-rect position in the file, based on its ordering field value,
and then make space in the file to insert the record in that position. For a
large file this can be very time-consuming because, on the average, half the
records of the file must be moved to make space for the new record. This means
that half the file blocks must be read and rewritten after records are moved
among them. For record deletion, the problem is less severe if deletion markers
and periodic reorganization are used.
One option for making insertion more efficient is to keep some unused
space in each block for new records. However, once this space is used up, the
original problem resurfaces. Another frequently used method is to create a
temporary unordered file called an overflow or transaction file. With this technique, the actual ordered file is
called the main or master file. New records are inserted
at the end of the overflow file rather than in their correct position in the
main file. Periodically, the overflow file is sorted and merged with the master
file during file reorganization. Insertion becomes very efficient, but at the
cost of increased complexity in the search algorithm. The overflow file must be
searched using a linear search if, after the binary search, the record is not
found in the main file. For applications that do not require the most
up-to-date information, overflow records can be ignored during a search.
Modifying a field value of a record depends on two factors: the search
condition to locate the record and the field to be modified. If the search
condition involves the ordering key field, we can locate the record using a
binary search; otherwise we must do a linear search. A nonordering field can be
modified by changing the record and rewriting it in the same physical location
on disk—assuming fixed-length records. Modifying the ordering field means that
the record can change its position in the file. This requires deletion of the
old record followed by insertion of the modified record.
Reading the file records in order of the ordering field is quite
efficient if we ignore the records in overflow, since the blocks can be read
consecutively using double buffering. To include the records in overflow, we
must merge them in their correct positions; in this case, first we can
reorganize the file, and then read its blocks sequentially. To reorganize the file,
first we sort the records in the overflow file, and then merge them with the
master file. The records marked for deletion are removed during the
reorganization.
Table 17.2 summarizes the average access time in block accesses to find
a specific record in a file with b
blocks.
Ordered files are rarely used in database applications unless an
additional access path, called a primary
index, is used; this results in an indexed-sequential
file. This

further improves the random access time on the ordering key field. (We
discuss indexes in Chapter 18.) If the ordering attribute is not a key, the
file is called a clustered file.
Related Topics