Chapter: Basic Concept of Biotechnology : Macromolecules and Analytical Techniques
Macromolecules
Macromolecules
Macromolecules are composed of monomeric subunits and these subunits are made up of simple structure. Macromolecules are organic solid matter of the cells and of four types viz: carbohydrates, proteins, lipids and nucleic acids. However the inorganic salts and minerals also constitute a small fraction of the dry weight of the cell.
1. Carbohydrates.
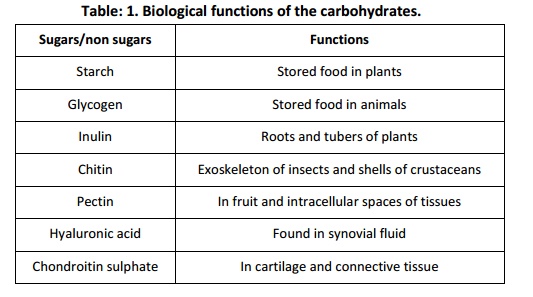
Carbohydrates are polyhydroxy aldehydes or ketones or substances that yield one of these compounds on hydrolysis. They contain hydrogen and oxygen in 2:1 ratio. In plants they will be present in the form of starch and in animals as glycogen. Carbohydrates can be divided into sugars and non sugars. Sugars are crystalline, soluble and most have a sweet taste. Further sugars are divided into mono saccharides and oligosaccharides.
Monosaccharide’s are polyhydroxy aldehydes or ketones which cannot be further hydrolysed to yield simpler sugars e.g., glucose, fructose and galactose. Monosaccharides are further classified into triose (3C), tetroses (4C), pentoses (5C) and hexoses (6C) depending on their number of carbon atom present. Oligosaccharides are polyhydroxy aldehydes or ketones which yield monosaccharides upon hydrolysis and are classified as Disaccharides (e.g., sucrose andmaltose) and trisaccharides (e.g., raffinose and stachyose). The monomeric units in these saccharides are held by glycosidic bonds. The monosaccharides are also called as reducing sugars since they have free aldehydic or ketonic carbon atom and can reduce Feheling’s and Benedict’s solution. The Di and tri sugars are non reducing sugars. In open chain form of monosaccharide’s one of the carbon atoms is double bonded with an oxygen atom to form a carbonyl group. If the carbonyl group is present at the end of the carbon chain the monosaccharide is an aldose. If the carbonyl group is in any other position then the monosaccharide is a ketose. The non sugars are amorphous, tasteless and less insoluble in water. The non sugars are further divided into homopoly saccharides and heteropoly saccharides. The homo polysaccharides (e.g., starch and inulin) are made of same repetitive monosaccharide where as oligo polysaccharides (e.g., heparin and agar-agar) are made up of two or three different types of monosaccharide units. The sugars combine with other elements or functional groups to perform various functions in the biological systems. The presence and function of the above sugars and non sugars in biological system is depicted in the table 1.
2. Lipids
Lipids are water insoluble organic substances which are formed by condensation reactions between fatty acids and alchohol. They have a general formula R.COOH where R is hydrogen or groups such as –CH3,-C2H5 etc. Fatty acids are aliphatic carboxylic acids and have ester or amide linkage. Most naturally occurring fatty acids have even number of carbon atoms between 14 and 22. Fatty acids with more carbon atoms are less soluble. The carbon and hydrogen atoms form a hydrocarbon tail which is hydrophobic in nature or water hating. As the hydrocarbon chain length increases the boiling and melting point of the fatty acids will be increased. If fatty acids contain one or more double bond then they are called as unsaturated. Fatty acid or lipids lacking these double bonds are called as saturated fatty acids. Saturated fatty acids with less than 10 carbon atoms are liquid at room temperature. Unsaturated fatty acids have low melting temperature than the saturated fatty acids. In case of alcohols moiety, most of the lipids are made up of alchohol glycerol. Glycerol has three hydroxyl groups which condense with fatty acids to form triglyceride. Classification of the lipids was done by Bloor in 1925, and can be classified into simple, compound and derived lipids. Simple lipids upon hydrolysis yield one or more type of fatty acid and alcohols for e.g., fats and wax. Compound lipids upon hydrolysis yield fatty acid, glycerol and sugars or phosphoric acid for e.g., spingolipids. Derived lipids are obtained by hydrolysis of simpleor compound lipids and they do not contain the ester linkage for e.g., sterols and prostaglandins. Fatty acids can be classified into three groups viz: depending on number of carbon atom, based on length of hydrocarbon chain and based on nature of fatty acids. Depending on number of cabon atoms, fatty acids can be divided into even chain fatty acids (Having even chain of 2, 4, 6 for e.g., acetic acid and butyric acid) and odd chain fatty acids (having odd chain of 3, 5, 7 for e.g., propionoic acid and valvic acid). Based on length of hydrocarbon chain fatty acids can be divided into short chain (having 2 to 6 carbon atoms), medium chain (having 8 to 14 carbon atoms) and long chain (having 16 to 24 carbon atoms) fatty acids. Based on the nature of fatty acids they can be divided into saturated (e.g., butyric and caproic acid) and unsaturated (e.g., PUFA such as linoic acid, linolenic acid and arachidonic acid) fatty acids. Fatty acids and lipids have many important biological functions in the living organisms. They are stored form of energy. They are present in cell membrane. The vitamins such as A, D, E and K are soluble in fat only. Fatty acids are present in mylin sheath of neurons. They are involved in the synthesis of steroid harmones and they also acts as cushioning to many vital organs. Fatty acids are building blocks of phospholipids and glycolipids which are fuel molecules in the form of tri acyl glycerols present in fat or adipose tissue. Phosphoglycerides are found in membrane and differs from triacyl glycerols in that one of the OH groups of glycerol is esterified to phosphoric acid. Lipids with protein are called as apo lipoproteins and with sugars are called as glycolipids. These are involved in many of the cellular reaction, signalling pathways, sites of biological recognition and as transport system at the cell membrane levels. Lipids act as signals in the form of harmones and cofactors and pigments.
3.Proteins.
Proteins are most abundant macromolecules in the biological system and they exist in various forms specific for carrying out particular biological functions. The first person to work out thecomplete amino acid sequence of insulin a protein was Fred Sanger in 1953. Proteins are polymers and amino acids are their monomers. In other words, they are made up of amino acids. Naturally occurring proteins are made up of 20 standard amino acids. Standard amino acids are those for which at least one code will exist in DNA. Besides this non protein amino acids (about 150) also exist in biological system, these are produced as metabolic intermediates which are derived from alpha amino acids (e.g., Dopain and GABA which are derived from tyrosin and glutamine respectively). Some of the rare amino acids are also present in proteins which do not have any codes in DNA but they are formed from some of the common amino acids. For e.g., Hydroxyproline is formed from proline and is present in collagen. Similarly hydroxyllysine is made from lysine and is also present in collagen. Amino acids are classified based on polarity viz: non polar, neutral, positively charged and negatively charged amino acids. Plants are able to synthesize the required amino acids from simpler substances whereas animals cannot synthesize some of the required amino acids which are termed as essential amino acids and these essential amino acids has to be supplemented through their diet to meet the requirement. Based on this amino acids can be classified into three types viz: essential (e.g. methionin, threonin, lysine, argenin, trypsin, valin and leucin), non essential (e.g., cystin, serin, aspartic acid, alanin, glutanin and tyrosin) and semi essential (e.g., histidin and arginin). The amino acids in the protein are held together by a peptide bond. Further the protein undergoes typical folding to form a particular shape as a result of ionic bond, disulphide bond, hydrogen bond and hydrophobic interactions. These bonds play essential roles in the primary, secondary, tertiary and quaternary structures of the protein. The peptide bond is formed by linking amino acid through amide bond. The alpha carboxyl group of one amino acid reacts with alpha amino group of another amino acid to form bond with elimination of water molecule to from peptide. Simple peptides containing two, three or four amino acid residuesare called di, tri and tetra peptides respectively. The peptide possesses free amino and carboxyl groups to which other amino acids can be joined to form a polypeptide. A protein may contain several polypeptide chains. Proteins are meant to perform various roles in biological systems. Based on this they can be classified into catalytic (ribinuclease), transport (haemoglobin and myoglobin), nutrient (egg, ovalbumin and casein), contractile and motile (actin and myosin), structural (collagen, alpha keratin and elastin), defence (immunoglobin, thrombin, venom and bacterial toxins) and regulatory (enzymes and membrane transport) proteins. Based on shape, proteins can be classified into two type’s globular and fibrous type. Globular proteins are water soluble and most of them have tertiary structure of proteins for e.g., storage and defence proteins. The fibrous proteins are water insoluble and are of secondary structure in nature for e.g., elastin, alpha keratin etc. Three types of proteins are there based upon their solubility viz; simple, conjugated and derived protein. Among these proteins conjugated proteins are associated with some of the chemical component along with the amino acids. The non amino acid part of conjugated protein is called as prosthetic group. Conjugated proteins are classified based on the chemical nature of their prosthetic group. For e.g., lipoprotein contain lipids as their prosthetic part (e.g., beta lipoprotein of blood), similarly glycoprotein (e.g., immunoglobulin G) contain carbohydrates, phosphoprotein (casein of milk) contain phosphate group, metalloprotein contain metal ions such as iron (e.g., ferretin), zinc (e.g., alcohol dehydrogenase), copper (e.g., plastocyanin) etc, as their prosthetic group. Protein exist in several types of structures viz; primary, secondary, tertiary and quaternary structures. In primary structure of proteins the amino acids are sequentially arranged in a polypeptide chain. The secondary structure is stable arrangements of amino acids giving rise to recurring structural patterns or it is local special arrangements of polypeptide back bone atoms, it excludes confirmation of side chains. Tertiary structure is three dimensional folding of polypeptide chain. Quaternary structure of protein is special arrangements of subunits present in the protein. Heat, radiation, strong acids and alkalis, heavy metals, organic solvents and detergents can cause temporary or permanent damage to the structures of protein as a result, protein will no longer perform its biological function this is called denaturation. Sometimes proteins fold back to from its original structure after its denaturation and are able to perform its function this is called as renaturation.
4. Nucleic acids
Nucleic acids are biopolymers of high molecular weight with mononuceotides as their repeating units. These units are arranged to form extremely long molecules known as polynuceotides. They form the genetic material for all living organisms. There are two units of nucleic acids they are Deoxy Ribose Nucleic Acids (DNA) and Ribose Nucleic Acids (RNA).Upon hydrolysis they yield phosphoric acid, pentose sugar and a nitrogenous base. In both DNA and RNA, sugar is in furanose form and is of beta configuration. The 5 carbon sugar is present and generally called as pentose sugar. In DNA it is deoxy ribose where an oxygen atom is removed from the carbon atom 2. These sugars form esters with H3PO4 forming a 31 51phosphodiester bond between adjacent sugars. The nitrogenous base is of four types, among which two are derived from Purine and two from pyrimidine. The Purine bases are adenine (A) and guanine (G). They contain 6 member pyramidin ring fused to a 5 member imidazole ring. The two pyrimidine are thymine (T) and cytosine(C) in DNA, whereas uracil (U) will be present in RNA in place of thymine. The phosphoric acid gives acidic nature to the nucleic acids. Al together phosphate group and sugars perform structural role in nucleic acids. The nitrogenous bases are conjugated with pentose sugars by beta glycosidic linkage without any phosphate group forming nucleosides. Nucleosides further undergo condensation with phosphoric acid to form nucleotides or in other words nucleotides are phosphoric esters of nucleosides. These nucleotides are not only the building blocks ofnucleic acid they also function as carriers of chemical energy, as components of enzyme factors (coenzyme A, NAD and NADP),as chemical messengers (e.g., c amp). The base composition of the DNA was proposed by Erwin Chargaff in 1940.The ratio of A: T and G:C is 1. When Adenine and Thymine is more in DNA then it is called as AT type. If A: T value is less than 1 then DNA is designated as GC type. The features of DNA were well explained by Watson and Crick in 1953. DNA consists of two polynucleotide chains and the two chains coil around each other (in anti parallel direction) to form a right handed double helical structure. Each chain has a sugar –phosphate backbone with bases which projects at right angles and hydrogen bond with bases of opposite chain across the double helix. The Purine and pyrymidine bases of both the strands are stacked inside the double helix. The offset pairing of the two strands create a major groove measuring 12A0 and minor groove measuring 6A0 on the surface of duplex. Along the axis of the molecules the base pairs are 0.34nm apart hence a complete turn of the double helix contain 10 base pairs or measures 3.4nm. The double helical of DNA are complimentary to each other. Hence adenine is bonded with thymine and guanine with cytosine. Base tilt normal to the helix axis is 60. The double helical structure is held together by two forces one is hydrogen bond between complimentary bases and second is base stacking interactions. The DNA structures are wrapped around the nucleoproteins which consist of protomines and histones, which are basic in nature. These two bind by electrostatic force. Histones and DNA in water forms nucleosomes. The Watson and Crick DNA structure is also called as B form DNA; it is the most stable structural form of the DNA. Other forms of DNA are A and Z form. The A form is relatively divide of water, helix is wider and has more base pairs (11) than that of B DNA. Base tilt normal to the helix axis is 200. Whereas; Z DNA is having the left handed helical rotation. Base tilt normal to the helix axis is 70. There are 12 base pairs per helical turn and the structure appears more slender and elongated.
The second form of nucleic acid is RNA. It involves in the expression of the genetic information from the DNA. In gene expression RNA acts as an intermediary by using the information encoded in DNA to specify the amino acid sequence of a functional protein. RNA is alkali labile and native RNA is single stranded. There are three important types of RNA viz: rRNA, tRNA and mRNA. rRNA is insoluble and found in ribosomes. It can be sedimented at 100000g for 120 minutes. It makes up 80% of total RNA of cell and represents 40-60% of total weight of RNA. It is involved in the synthesis of protein. mRNA are synthesized on the surface of the DNA by DNA dependent RNA polymerase and it exist only for short period. Average size of m RNA is 900-1500 nucleotide unit. If mRNA codes for a single protein then it is called as monocistronic. If it codes for more than two proteins then it is called as polycistronic. In eukaryotes most of the m RNA are monocistronics. Another form of RNA is t RNA or transfer RNA. It is involved in the transfer of amino acids to the r RNA site for protein synthesis. It reads the information encoded in the m RNA and transfers the amino acid to a growing polypeptide chain during protein synthesis. A typical t RNA has 51 phosphorylated terminus and a 31 terminus for amino acid attachment. It has a T psi C loop of 5 base pairs which help in binding tRNA to ribosome. Also it has DHU loop of 3-4 base pairs which acts as recognition site for enzymes. A variable arm and an activation loop of 7 base pairs were also present.
Related Topics