Chapter: Principles of Compiler Design : Lexical Analysis
Lexical Analysis
LEXICAL ANALYSIS
A simple way to build
lexical analyzer is to construct a diagram that illustrates the structure of
the tokens of the source language, and then to hand-translate the diagram into
a program for finding tokens. Efficient lexical analysers can be produced in
this manner.
Role of Lexical Analyser
The lexical analyzer is the first phase of compiler.
Its main task is to read the input characters and produces output a sequence of
tokens that the parser uses for syntax analysis. As in the figure, upon
receiving a “get next token” command from the parser the lexical analyzer reads
input characters until it can identify the next token.
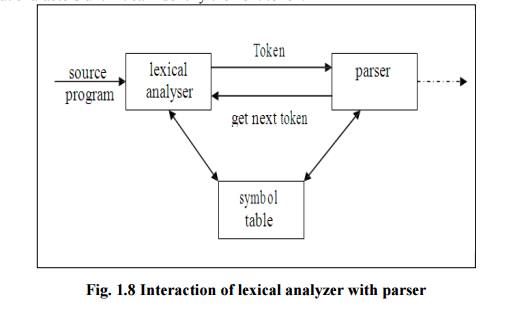
Fig.
1.8 Interaction of lexical analyzer with parser
Since the lexical
analyzer is the part of the compiler that reads the source text, it may also
perform certain secondary tasks at the user interface. One such task is stripping
out from the source program comments and white space in the form of blank, tab,
and new line character. Another is correlating error messages from the compiler
with the source program.
Issues in Lexical Analysis
There are several
reasons for separating the analysis phase of compiling into lexical analysis
and parsing
1) Simpler
design is the most important consideration. The separation of lexical analysis
from syntax analysis often allows us to simplify one or the other of these
phases.
2) Compiler
efficiency is improved.
3) Compiler
portability is enhanced.
Tokens Patterns and Lexemes.
![]()
There is a set of
strings in the input for which the same token is produced as output. This set
of strings is described by a rule called a pattern associated with the token.
The pattern is set to match each string in the set.
In most programming
languages, the following constructs are treated as tokens: keywords, operators,
identifiers, constants, literal strings, and punctuation symbols such as
parentheses, commas, and semicolons.
Lexeme
Collection or group of
characters forming tokens is called Lexeme. A lexeme is a sequence of
characters in the source program that is matched by the pattern for the token.
For example in the Pascal’s statement const pi = 3.1416; the substring pi is a
lexeme for the token identifier.
Patterns
A pattern is a rule
describing a set of lexemes that can represent a particular token in source
program. The pattern for the token const in the above table is just the single
string const that spells out the keyword.

Certain language
conventions impact the difficulty of lexical analysis. Languages such as
FORTRAN require a certain constructs in fixed positions on the input line. Thus
the alignment of a lexeme may be important in determining the correctness of a
source program.
Attributes of Token
The lexical analyzer
returns to the parser a representation for the token it has found. The
representation is an integer code if the token is a simple construct such as a
left parenthesis, comma, or colon. The representation is a pair consisting of
an integer code and a pointer to a table if the token is a more complex element
such as an identifier or constant.
The integer code gives
the token type, the pointer points to the value of that token. Pairs are also
retuned whenever we wish to distinguish between instances of a token.
The attributes influence the translation of tokens.
i)
Constant : value of the constant
ii)
Identifiers: pointer to the
corresponding symbol table entry.
Error Recovery Strategies In Lexical
Analysis
The following are the error-recovery actions in
lexical analysis:
1) Deleting
an extraneous character.
2) Inserting
a missing character.
3)Replacing an incorrect
character by a correct character.
4)Transforming two
adjacent characters.
5) Panic
mode recovery: Deletion of successive characters from
the token until error is resolved.
Related Topics