Chapter: Principles of Compiler Design : Syntax Analysis and Run-Time Environments
Important Short Questions and Answers: Syntax Analysis and Run-Time Environments
1.
What is the output of syntax
analysis phase? What are the three general types of parsers for grammars?
Parser (or) parse tree is the output of syntax
analysis phase. General types of parsers:
1)
Universal parsing
2)
Top-down
3)
Bottom-up
2.
What are the different strategies
that a parser can employ to recover from a syntactic error?
Panic mode
Phrase level
Error productions
Global correction
3.
What are the goals of error handler
in a parser?
The error handler in a parser has simple-to-state
goals:
·
It should report the presence of errors
clearly and accurately
·
It should recover from each error
quickly enough to be able to detect subsequent errors.
·
It should not significantly slow down
the processing of correct programs
4.
What is phrase level error recovery?
On discovering an error, a parser may
perform local correction on the remaining input; that is, it may replace a
prefix of the remaining input by some string that allows the parser to
continue. This is known as phrase level error recovery.
5.
How will you define a context free
grammar?
A context free grammar consists of terminals,
non-terminals, a start symbol, and productions.
i.
Terminals are the basic symbols from
which strings are formed. “Token” is a synonym for terminal. Ex: if,
then, else.
ii.
Nonterminals are syntactic variables
that denote sets of strings, which help define the language generated by the
grammar. Ex: stmt, expr.
iii.
Start symbol is one of the nonterminals
in a grammar and the set of strings it denotes is the language defined by the
grammar. Ex: S.
iv.
The productions of a grammar specify the
manner in which the terminals and
nonterminals
can be combined to form strings Ex: expr
6.
Define context free language. When
will you say that two CFGs are equal?
·
A language that can be generated by a
grammar is said to be a context free language.
·
If two grammars generate the same
language, the grammars are said to be equivalent.
7.
Differentiate sentence and
sentential form.
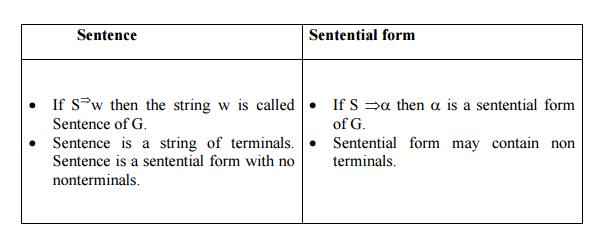
8. Give the definition for leftmost and
canonical derivations.
·
Derivations in which only the leftmost
nonterminal in any sentential form is replaced at each step are termed leftmost
derivations
·
Derivations in which the rightmost
nonterminal is replaced at each step are termed canonical derivations.
9.
What is a parse tree?
A parse tree may be viewed as a
graphical representation for a derivation that filters out the choice regarding
replacement order. Each interior node of a parse tree is labeled by some
nonterminal A and that the children of the node are labeled from left to
right by symbols in the right side of the production
by which this A was replaced in the derivation. The leaves of the parse tree
are terminal symbols.
10.
What is an ambiguous grammar? Give
an example.
·
A grammar that produces more than one
parse tree for some sentence is said to be ambiguous
·
An ambiguous grammar is one that
produces more than one leftmost or rightmost derivation for the same sentence.
Ex:
E-> E+E / E*E / id
11.
Why do we use regular expressions
to define the lexical syntax of a language?
i.
The lexical rules of a language are
frequently quite simple, and to describe them we do not need a notation as
powerful as grammars.
ii.
Regular expressions generally provide a
more concise and easier to understand notation for tokens than grammars.
iii.
More efficient lexical analyzers can be
constructed automatically from regular expressions than from arbitrary
grammars.
iv.
Separating the syntactic structure of a
language into lexical and non lexical parts provides a convenient way of
modularizing the front end of a compiler into two manageable-sized components.
12.
When will you call a grammar as the
left recursive one?
A grammar is a left recursive if it has a
nonterminal A such that there is a derivation
A->Aα for some string α.
13.
Define left factoring.
Left factoring is a grammar transformation that is
useful for producing a grammar suitable for predictive parsing. The basic idea
is that when it is not clear which of two alternative productions to use to expand
a nonterminal “A”, we may be able to rewrite the “A” productions
to refer the decision until we have seen enough of the input to make the right
choice.
14. Left factor the following grammar:
S
→ iEtS | iEtSeS |a
E
→ b.
Ans:
The left factored grammar is,
S
→ iEtSS′ | a
S′
→ eS | ε
E
→ b
15. What is parsing?
Parsing
is the process of determining if a string of tokens can be generated by a
grammar.
16. What is Top Down parsing?
Starting with the root, labeled, does
the top-down construction of a parse tree with the starting nonterminal,
repeatedly performing the following steps.
i.
At node n, labeled with non terminal “A”,
select one of the productions for “A” and construct children at n for
the symbols on the right side of the production.
ii.
Find the next node at which a sub tree
is to be constructed.
17.
What do you mean by Recursive
Descent Parsing?
Recursive Descent Parsing is top down
method of syntax analysis in which we execute a set of recursive procedures to
process the input. A procedure is associated with each nonterminal of a
grammar.
18. What is meant by Predictive parsing?
A special form of Recursive Descent
parsing, in which the look-ahead symbol unambiguously determines the procedure
selected for each nonterminal, where no backtracking is required.
19. Define Bottom Up Parsing.
Parsing method in which construction
starts at the leaves and proceeds towards the root is called as Bottom Up
Parsing.
20. What is Shift-Reduce parsing?
A general style of bottom-up syntax
analysis, which attempts to construct a parse tree for an input string
beginning at the leaves and working up towards the root.
21.
Define handle. What do you mean by
handle pruning?
·
An Handle of a string is a sub string
that matches the right side of production and whose reduction to the
nonterminal on the left side of the production represents one step along the
reverse of a rightmost derivation.
·
The process of obtaining rightmost
derivation in reverse is known as Handle Pruning.
22.
Define LR (0) items.
An LR (0) item of a grammar G is a production of G
with a dot at some position of the right side. Thus the production A → XYZ
yields the following four items,
A
→ .XYZ
A
→ X.YZ
A
→ XY.Z
A
→ XYZ.
23.
What do you mean by viable
prefixes?
·
The set of prefixes of right sentential
forms that can appear on the stack of a shift-reduce parser are called viable
prefixes.
·
A viable prefix is that it is a prefix
of a right sentential form that does not continue the past the right end of the
rightmost handle of that sentential form.
24.
What is meant by an operator
grammar? Give an example.
A
grammar is operator grammar if,
i.
No production rule involves “a”
on the right side.
ii.
No production has two adjacent
nonterminals on the right side..
Ex:
E
→ E+E | E-E | E*E | E/E | EE | (E) | -E | id
25.
What are the disadvantages of
operator precedence parsing? May/June 2007
i.
It is hard to handle tokens like the
minus sign, which has two different precedences.
ii.
Since the relationship between a grammar
for the language being parsed and the operator – precedence parser itself is
tenuous, one cannot always be sure the parser accepts exactly the desired
language.
iii.
Only a small class of grammars can be
parsed using operator precedence techniques.
26.
State error recovery in
operator-Precedence Parsing.
There are two points in the parsing
process at which an operator-precedence parser can discover the syntactic
errors:
i.
If no precedence relation holds between
the terminal on top of the stack and the current input.
ii.
If a handle has been found, but there is
no production with this handle as a right side.
27.
LR (k) parsing stands for what?
The “L” is for left-to-right scanning of
the input, the “R” for constructing a rightmost derivation in reverse, and the
k for the number of input symbols of lookahead that are used in making parsing
decisions.
28.
Why LR parsing is attractive one?
·
LR parsers can be constructed to
recognize virtually all programming language constructs for which context free
grammars can be written.
·
The LR parsing method is the, most
general nonbacktracking shift-reduce parsing method known, yet it can be
implemented as efficiently as other shift reduce methods.
·
The class of grammars that can be parsed
using LR methods is a proper superset of the class of grammars that can be
parsed with predictive parsers.
· An
LR parser can detect a syntactic error as soon as it is possible to do so on a
left-to-right scan of the input.
29.What is meant by goto
function in LR parser? Give an example.
·
The function goto takes a state
and grammar symbol as arguments and produces a state.
·
The goto function of a parsing
table constructed from a grammar G is the transition function of a DFA that
recognizes the viable prefixes of G.
Ex:
goto(I,X)
Where I is a set of items and X is a grammar symbol
to be the closure of the set of all items [A→αX.ẞ] such that [A→α.X ẞ] is in I
30.
Write the configuration of an LR parser?
A configuration of an LR parser is a
pair whose first component is the stack contents and whose second component is
the unexpended input:
(s0
X1 s1 X2 s2 …Xm sm , ai
ai+1 … an $)
31.
Define LR grammar.
A grammar for which we can construct a
parsing table is said to be an LR grammar.
32.
What are kernel and non kernel
items?Nov/Dec 2005
i.
The set of items which include the
initial item, SS, and all items whose dots are not at the left end are known
as kernel items.
ii.
The set of items, which have their dots
at the left end, are known as non kernel items.
33.
Why SLR and LALR are more
economical to construct than canonical LR?
For a comparison of parser size, the SLR
and LALR tables for a grammar always have the same number of states, and this
number is typically several hundred states for a language like Pascal. The
canonical LR table would typically have several thousand states for the same
size language. Thus, it is much easier and more economical to construct SLR and
LALR tables than the canonical LR tables.
34.
What is ambiguous grammer? Give an
example.
A grammer G is said to be ambiguous if it generates
more than one parse trees for sentence of language L(G).
Example:
E-> E+E|E*E|id
Related Topics