Chapter: Advanced Computer Architecture : Memory And I/O
Important Short Questions and Answers: Memory and I/O
1. What is server utilization?
Mean
number of tasks being serviced divided by service rate Server utilization =
Arrival Rate/Server Rate The value should be between 0 and 1 otherwise there
would be more tasks arriving than could be serviced.
2. What are the steps to design an I/O system?
Ø Naïve
cost-performance design and evaluation
Ø Availability
of naïve design
Ø Response
time
Ø Realistic
cost-performance, design and evaluation
Ø Realistic
design for availability and its evaluation.
3. Briefly discuss about classification of buses?
I/O buses
- These buses are lengthy ad have any types of devices connected to it. CPU memory
buses – They are short and generally of high speed.
4. Explain about bus transactions?
Read
transaction – Transfer data from memory Write transaction – Writes data to
memory
5. What is the bus master?
Bus
masters are devices that can initiate the read or write transaction. E.g CPU is
always a bus master. The bus can have many masters when there are multiple
CPU’s and when the Input
devices
can initiate bus transaction.
6. Mention the advantage of using bus master?
It offers
higher bandwidth by using packets, as opposed to holding the bus for full
transaction.
7. What is spilt transaction?
The idea behind this is to split the
bus into request and replies, so that the buscan be used in the time between
request and the reply
8.What do you understand by true sharing misses?
True
sharing misses are a type of coherent misses that arise from the communication
of data through the cache coherence mechanism. In an invalidation based
protocol, the first write by a processor to a shared cache block causes an
invalidation to establish ownership of that block. Additionally, when another
processor attempts to read a modified word in that cache block, a miss occurs
and the resultant block is transferred. Both these misses are classified as
true sharing misses since they directly arise from the sharing of data among
processors.
9. Assume that words xl and x2 are in the
same cache block, which is in the shared state in the caches of both PI and P2. Assuming the following sequence of
events, identify each miss as a true sharing miss, a false sharing miss, or a
hit. Any miss that would occur if the block size were one word is designated a
true sharing miss.
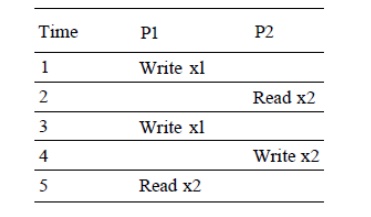
Here are
classifications by time step:
1. This
event is a true sharing miss, since xl was read by P2 and needs to be
invalidated from P2.
2. This
event is a false sharing miss, since x2 was invalidated by the write of xl in
PI, but that value of xl is not used in P2.
3. This
event is a false sharing miss, since the block containing xl is marked shared
due to the read in P2, but P2 did not read xl. The cache block containing xl
will be in the shared state after the read by P2; a write miss is required to
obtain exclusive access to the block. In some protocols this will be handled as
an upgrade request, which generates a bus invalidate, but does not transfer the
cache block.
4. This
event is a false sharing miss for the same reason as step 3.
5. This
event is a true sharing miss, since the value being read was written by P2.
10. Giving priority to read misses over writes
reduces miss penalty. How?
Giving
priority to read misses over writes to reduce miss penalty—A write buffer is a
good place to implement this optimization. Write buffers create hazards because
they hold the updated value of a location needed on a read miss—that is, a
read-after-write hazard through memory. One solution is to check the contents
of the write buffer on a read miss. If there are no conflicts, and if the
memory system is available, sending the read before the writes reduces the miss
penalty. Most processors give reads priority over writes.
11. What is the impact of doubling associativity
while doubling the cache size on the size of the index in Cache mapping?

12.
List the
Six basic optimizations of Cache?
Ø Larger
block size to reduce miss rate Bigger caches to reduce miss rate Higher
associativity to reduce miss rate
Ø Multilevel
caches to reduce miss penalty
Ø Giving
priority to read misses over writes to reduce miss penalty
Ø Avoiding
address translation during indexing of the cache to reduce hit time
13. What is sequential inter-leaving? It is implemented
in which level of the memory hierarchy?
Sequential
inter-leaving is implemented at Cache level. It is one of the optimization
technique used to improve cache performance.
Multibanked
Caches are used to Increase Cache Bandwidth. Clearly, banking works best when
the accesses naturally spread themselves across the banks, so the mapping of
addresses to banks affects the behavior of the memory system. A simple mapping
that works well is to spread the addresses of the block sequentially across the
banks, called sequential interleaving. For example, if there are four banks,
bank 0 has all blocks whose address modulo 4 is 0; bank 1 has all blocks whose
address modulo 4 is 1; and so on. Figure 5.6 shows this interleaving.
Related Topics