Chapter: Advanced Computer Architecture : Memory And I/O
Cache Performance
Cache Performance
The
average memory access time is calculated as follows
Average
memory access time = hit time + Miss rate x Miss Penalty.
Where Hit
Time is the time to deliver a block in the cache to the processor (includes
time to determine whether the block is in the cache), Miss Rate is the fraction
of memory references not found in cache (misses/references) and Miss Penalty is
the additional time required because of a miss the average memory access time
due to cache misses predicts processor performance.
First,
there are other reasons for stalls, such as contention due to I/O devices using
memory and due to cache misses
Second,
The CPU stalls during misses, and the memory stall time is strongly correlated
to average memory access time.
CPU time
= (CPU execution clock cycles + Memory stall clock cycles) × Clock cycle time
There are
17 cache optimizations into four categories:
1
Reducing the miss penalty: multilevel caches, critical word first, read miss
before write miss, merging write buffers, victim caches;
2
Reducing the miss rate larger block size, larger cache size, higher associativity,
pseudo-associativity, and compiler optimizations;
3
Reducing the miss penalty or miss rate via parallelism: nonblocking caches,
hardware prefetching, and compiler prefetching;
4
Reducing the time to hit in the cache: small and simple caches, avoiding
address translation, and pipelined cache access.
1. Techniques for Reducing Cache
Miss Penalty
There are
five optimizations techniques to reduce miss penalty.
i) First Miss Penalty Reduction Technique:
Multi-Level Caches
The First
Miss Penalty Reduction Technique follows the Adding another level of cache
between the original cache and memory. The first-level cache can be small
enough to match the clock cycle time of the fast CPU and the second-level cache
can be large enough to capture many accesses that would go to main memory,
thereby the effective miss penalty.
The
definition of average memory access time for a two-level cache. Using the
subscripts L1 and L2 to refer, respectively, to a
first-level and a second-level cache, the formula is
Average
memory access time = Hit timeL1 + Miss rateL1 × Miss
penalty L1 and
Miss
penaltyL1 = Hit timeL2 + Miss rateL2 × Miss
penalty L2
so
Average memory access time = Hit timeL1 + Miss rateL1×
(Hit time L2 + Miss rateL2 × Miss penaltyL2)
Local miss rate
This rate
is simply the number of misses in a cache divided by the total number of memory
accesses to this cache. As you would expect, for the first-level cache it is
equal to Miss rateL1 and for the second-level cache it is Miss rateL2
Global miss rate
The
number of misses in the cache divided by the total num-ber of memory accesses
generated by the CPU. Using the terms above, the global miss rate for the
first-level cache is still just Miss rateL1 but for the second-level
cache it is Miss rateL1 × Miss rate L2.
This
local miss rate is large for second level caches because the first-level cache
skims the cream of the memory accesses. This is why the global miss rate is the
more useful measure: it indicates what fraction of the memory accesses that
leave the CPU go all the way to memory.
Here is a
place where the misses per instruction metric shines. Instead of confusion
about local or global miss rates, we just expand memory stalls per instruction
to add the impact of a second level cache.
Average
memory stalls per instruction = Misses per instructionL1× Hit time L2
+ Misses per instructionL2 × Miss penalty L2.
We can
consider the parameters of second-level caches. The foremost difference between
the two levels is that the speed of the first-level cache affects the clock
rate of the CPU, while the speed of the second-level cache only affects the
miss penalty of the first-level cache.
The
initial decision is the size of a second-level cache. Since everything in the
first-level cache is likely to be in the second-level cache, the second-level
cache should be much bigger than the first. If second-level caches are just a
little bigger, the local miss rate will be high.
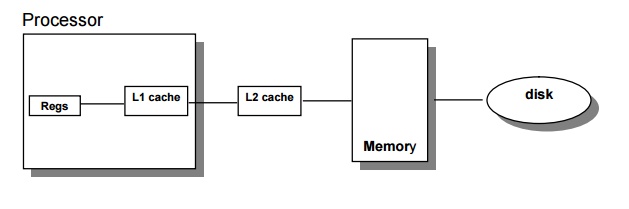
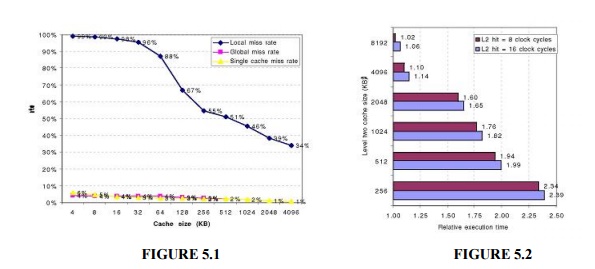
Figures
5.1 and 5.2 show how miss rates and relative execution time change with the
size of a second-level cache for one design.
ii) Second Miss Penalty Reduction Technique:
Critical Word First and Early Restart
Multilevel
caches require extra hardware to reduce miss penalty, but not this second technique.
It is based on the observation that the CPU normally needs just one word of the
block at a time. This strategy is impatience: Don’t wait for the full block to
be loaded before sending the requested word and restarting the CPU.
Here are
two specific strategies:
Critical word first
Request
the missed word first from memory and send it to the CPU as soon as it arrives;
let the CPU continue execution while filling the rest of the words in the
block. Critical-word-first fetch is also called wrapped fetch and requested
word first.
Early restart
Fetch the
words in normal order, but as soon as the requested word of the block arrives,
send it to the CPU and let the CPU continue execution.
Generally
these techniques only benefit designs with large cache blocks, since the
benefit is low unless blocks are large. The problem is that given spatial
locality, there is more than random chance that the next miss is to the
remainder of the block. In such cases, the effective miss penalty is the time
from the miss until the second piece arrives.
iii) Third Miss Penalty Reduction Technique: Giving
Priority to Read Misses over Writes
This
optimization serves reads before writes have been completed. We start with
looking at complexities of a write buffer. With a write-through cache the most
important improvement is a write buffer of the proper size. Write buffers,
however, do complicate memory accesses in that they might hold the updated
value of a location needed on a read miss. The simplest way out of this is for
the read miss to wait until the write buffer is empty.
The
alternative is to check the contents of the write buffer on a read miss, and if
there are no conflicts and the memory system is available, let the read miss
continue. Virtually all desktop and server processors use the latter approach,
giving reads priority over writes.
The cost
of writes by the processor in a write-back cache can also be reduced. Suppose a
read miss will replace a dirty memory block. Instead of writing the dirty block
to memory, and then reading memory, we could copy the dirty block to a buffer,
then read memory, and then write memory.
This way
the CPU read, for which the processor is probably waiting, will finish sooner.
Similar to the situation above, if a read miss occurs, the processor can either
stall until the buffer is empty or check the addresses of the words in the
buffer for conflicts.
iv) Fourth Miss Penalty Reduction Technique:
Merging Write Buffer
This
technique also involves write buffers, this time improving their efficiency.
Write through caches rely on write buffers, as all stores must be sent to the
next lower level of the hierarchy. As mentioned above, even write back caches
use a simple buffer when a block is replaced.
If the
write buffer is empty, the data and the full address are written in the buffer,
and the write is finished from the CPU's perspective; the CPU continues working
while the write buffer prepares to write the word to memory.
If the
buffer contains other modified blocks, the addresses can be checked to see if
the address of this new data matches the address of the valid write buffer
entry. If so, the new data are combined with that entry, called write merging.
If the
buffer is full and there is no address match, the cache (and CPU) must wait
until the buffer has an empty entry. This optimization uses the memory more
efficiently since multiword writes are usually faster than writes performed one
word at a time.
The
optimization also reduces stalls due to the write buffer being full. Figure
5.12 shows a write buffer with and without write merging. Assume we had four
entries in the write buffer, and each entry could hold four 64-bit words.
Without this optimization, four stores to sequential addresses would fill the
buffer at one word per entry, even though these four words when merged exactly
fit within a single entry of the write buffer.
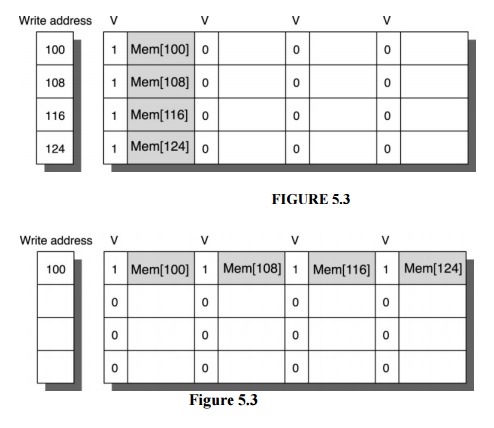
Figure
5.3 & 5.4 To illustrate write merging, the write buffer on top does not use
it while the write buffer on the bottom does. The four writes are merged into a
single buffer entry with write merging; without it, the buffer is full even
though three-fourths of each entry is wasted. The buffer has four entries, and
each entry holds four 64-bit words.
The
address for each entry is on the left, with valid bits (V) indicating whether
or not the next sequential eight bytes are occupied in this entry. (Without
write merging, the words to the right in the upper drawing would only be used
for instructions which wrote multiple words at the same time.)
v) Fifth Miss Penalty Reduction Technique: Victim
Caches
One
approach to lower miss penalty is to remember what was discarded in case it is
needed again. Since the discarded data has already been fetched, it can be used
again at small cost.
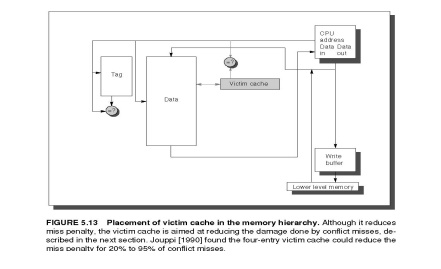
Such
“recycling” requires a small, fully associative cache between a cache and its
refill
path.
Figure 5.13 shows the organization. This victim cache contains only blocks that
are discarded from a cache because of a miss “victims” and are checked on a
miss to see if they have
the
desired data before going to the next lower-level memory. If it is found there,
the victim block and cache block are swapped. The AMD Athlon has a victim cache
with eight entries.
Jouppi
[1990] found that victim caches of one to five entries are effective at
reducing misses, especially for small, direct-mapped data caches. Depending on
the program, a four-entry victim cache might remove one quarter of the misses
in a 4-KB direct-mapped data cache.
Summary of Miss Penalty Reduction Techniques
The first
technique follows the proverb “the more the merrier”: assuming the principle of
locality will keep applying recursively, just keep adding more levels of
increasingly larger caches until you are happy. The second technique is
impatience: it retrieves the word of the block that caused the miss rather than
waiting for the full block to arrive. The next technique is preference. It
gives priority to reads over writes since the processor generally waits for
reads but continues after launching writes.
The
fourth technique is companion-ship, combining writes to sequential words into a
single block to create a more efficient transfer to memory. Finally comes a
cache equivalent of recycling, as a victim cache keeps a few discarded blocks
available for when the fickle primary cache wants a word that it recently
discarded. All these techniques help with miss penalty, but multilevel caches
is probably the most important.
2. Techniques to reduce miss rate
The
classical approach to improving cache behavior is to reduce miss rates, and
there are five techniques to reduce miss rate. we first start with a model that
sorts all misses into three
simple
categories:
Compulsory
The very
first access to a block cannot be in the cache, so the block must be brought
into the cache. These are also called cold start misses or first reference
misses.
Capacity
If the
cache cannot contain all the blocks needed during execution of a program,
capacity misses (in addition to compulsory misses) will occur be-cause of
blocks being discarded and later retrieved.
Conflict
If the
block placement strategy is set associative or direct mapped, conflict misses
(in addition to compulsory and capacity misses) will occur be-cause a block may
be discarded and later retrieved if too many blocks map to its set. These
misses are also called collision misses or interference misses. The idea is
that hits in a fully associative cache which become misses in an N-way set
associative cache are due to more than N requests on some popular sets.
i ) First Miss Rate Reduction Technique: Larger
Block Size
The
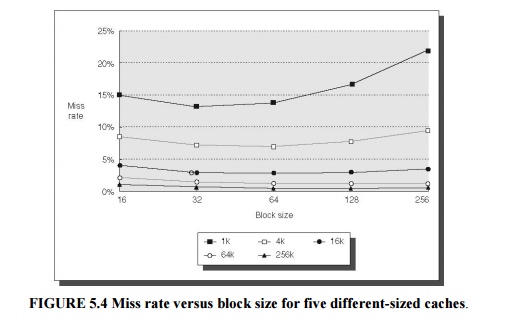
simplest way to reduce miss rate is to increase the block size. Figure 5.4
shows the trade-off of block size versus miss rate for a set of programs and
cache sizes. Larger block sizes will reduce compulsory misses. This reduction
occurs because the principle of locality has two components: temporal locality
and spatial locality. Larger blocks take advantage of spatial locality.
At the
same time, larger blocks increase the miss penalty. Since they reduce the
number of blocks in the cache, larger blocks may increase conflict misses and
even capacity misses if the cache is small. Clearly, there is little reason to
increase the block size to such a size that it increases the miss rate. There
is also no benefit to reducing miss rate if it increases the average memory
access time. The increase in miss penalty may outweigh the decrease in miss
rate.
ii) Second Miss Rate Reduction Technique: Larger
caches
The
obvious way to reduce capacity misses in the above is to increases capacity of
the cache. The obvious drawback is longer hit time and higher cost. This
technique has been especially popular in off-chip caches: The size of second or
third level caches in 2001 equals the size of main memory in desktop computers.
iii) Third Miss Rate Reduction Technique: Higher
Associativity:
Generally
the miss rates improves with higher associativity. There are two general rules
of thumb that can be drawn. The first is that eight-way set associative is for
practical purposes as effective in reducing misses for these sized caches as
fully associative. You can see the difference by comparing the 8-way entries to
the capacity miss, since capacity misses are calculated using fully associative
cache.
The
second observation, called the 2:1 cache rule of thumb and found on the front
inside cover, is that a direct-mapped cache of size N has about the same miss
rate as a 2-way set associative cache of size N/2. This held for cache sizes
less than 128 KB.
iv) Fourth Miss Rate Reduction Technique: Way
Prediction and Pseudo-Associative Caches
In
way-prediction, extra bits are kept in the cache to predict the set of the next
cache access. This prediction means the multiplexer is set early to select the
desired set, and only a single tag comparison is performed that clock cycle. A
miss results in checking the other sets for matches in subsequent clock cycles.
The Alpha
21264 uses way prediction in its instruction cache. (Added to each block of the
instruction cache is a set predictor bit. The bit is used to select which of
the two sets to try on the next cache access. If the predictor is correct, the
instruction cache latency is one clock cycle. If not, it tries the other set, changes
the set predictor, and has a latency of three clock cycles.
In
addition to improving performance, way prediction can reduce power for embedded
applications. By only supplying power to the half of the tags that are expected
to be used, the MIPS R4300 series lowers power consumption with the same
benefits.
A related
approach is called pseudo-associative or column associative. Accesses proceed
just as in the direct-mapped cache for a hit. On a miss, however, before going
to the next lower level of the memory hierarchy, a second cache entry is
checked to see if it matches there. A simple way is to invert the most
significant bit of the index field to find the other block in the
“pseudo
set.”
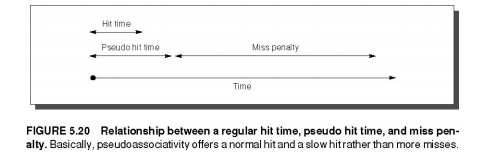
Pseudo-associative
caches then have one fast and one slow hit time—corresponding to a regular hit
and a pseudo hit—in addition to the miss penalty. Figure 5.20 shows the
relative times. One danger would be if many fast hit times of the direct-mapped
cache became slow hit times in the pseudo-associative cache. The performance
would then be degraded by this optimization. Hence, it is important to indicate
for each set which block should be the fast hit and which should be the slow
one. One way is simply to make the upper one fast and swap the contents of the
blocks. Another danger is that the miss penalty may become slightly longer,
adding the time to check another cache entry.
v) Fifth Miss Rate Reduction Technique: Compiler
Optimizations
This
final technique reduces miss rates without any hardware changes. This magical
reduction comes from optimized software. The increasing performance gap between
processors and main memory has inspired compiler writers to scrutinize the
memory hierarchy to see if compile time optimizations can improve performance.
Once again research is split between improvements in instruction misses and
improvements in data misses.
Code can
easily be rearranged without affecting correctness; for example, reordering the
procedures of a program might reduce instruction miss rates by reducing
conflict misses. Reordering the instructions reduced misses by 50% for a 2-KB
direct-mapped instruction cache with 4-byte blocks, and by 75% in an 8-KB
cache.
Another
code optimization aims for better efficiency from long cache blocks. Aligning
basic blocks so that the entry point is at the beginning of a cache block
decreases the chance of a cache miss for sequential code.
Loop Interchange:
Some
programs have nested loops that access data in memory in non-sequential order.
Simply exchanging the nesting of the loops can make the code access the data in
the order it is stored. Assuming the arrays do not fit in cache, this technique
reduces misses by improving spatial locality; reordering maximizes use of data
in a cache block before it is discarded.
/* Before */ for (j = 0; j < 100; j = j+1) for
(i = 0; i < 5000; i = i+1)
x[i][j] =
2 * x[i][j];
/* After
*/
for (i =
0; i < 5000; i = i+1) for (j = 0; j < 100; j = j+1) x[i][j] = 2 *
x[i][j];
This
optimization improves cache performance without affecting the number of
instructions executed.
Blocking:
This
optimization tries to reduce misses via improved temporal locality. We are
again dealing with multiple arrays, with some arrays accessed by rows and some
by columns. Storing the arrays row by row (row major order) or column by column
(column major order) does not solve the problem because both rows and columns
are used in every iteration of the loop. Such orthogonal accesses mean the
transformations such as loop interchange are not helpful.
Instead
of operating on entire rows or columns of an array, blocked algorithms operate
on submatrices or blocks. The goal is to maximize accesses to the data loaded
into the cache before the data are replaced.
Summary of Reducing Cache Miss Rate
This section
first presented the three C’s model of cache misses: compulsory, capacity, and
conflict. This intuitive model led to three obvious optimizations: larger block
size to reduce compulsory misses, larger cache size to reduce capacity misses,
and higher associativity to reduce conflict misses. Since higher associativity
may affect cache hit time or cache power consumption, way prediction checks
only a piece of the cache for hits and then on a miss checks the rest. The
final technique is the favorite of the hardware designer, leaving cache
optimizations to the compiler.
Related Topics