Chapter: Distributed Systems : Synchronization and Replication
Global states
Global states
How do we
find out if a particular property is true in a distributed system? For
examples, we will look at:
Distributed
Garbage Collection
Deadlock
Detection
Termination
Detection
Debugging
Distributed
Garbage Collection
Objects
are identified as garbage when there are no longer any references to them in the
system
Garbage
collection reclaims memory used by those objects
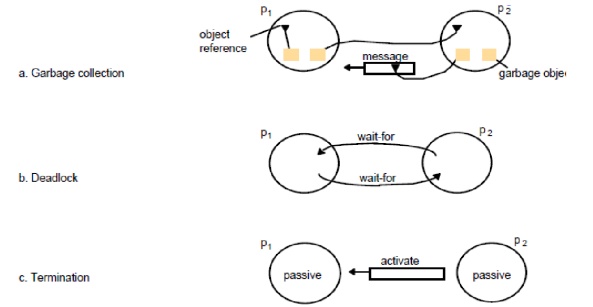
In figure
11.8a, process p2 has two objects that do not have any references to other
objects, but one object does have a reference to a message in transit. It is
not garbage, but the other p2 object is
Thus we
must consider communication channels as well as object references to determine
unreferenced objects
Deadlock
Detection
A
distributed deadlock occurs when each of a collection of processes waits for
another process to send it a message, and there is a cycle in the graph of the waits-for
relationship
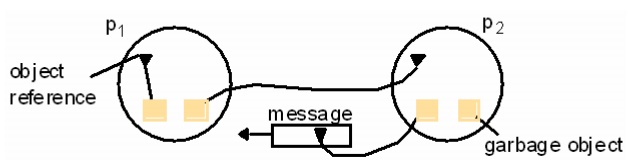
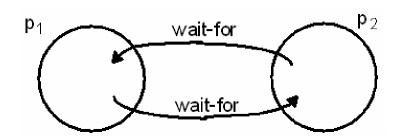
In figure
11.8b, both p1 and p2 wait for a message from the other, so both are blocked
and the system cannot continue
Termination
Detection
It is
difficult to tell whether a distributed algorithm has terminated. It is not
enough to detect whether each process has halted
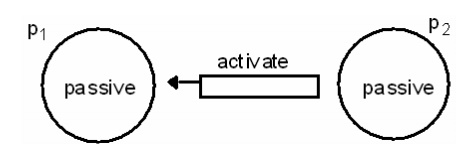
In figure
11.8c, both processes are in passive mode, but there is an activation request
in the network
Termination
detection examines multiple states like deadlock detection, except that a
deadlock may affect only a portion of the processes involved, while termination detection must ensure that all of the processes have
completed
Distributed
Debugging
Distributed
processes are complex to debug. One of many possible problems is that
consistency restraints must be evaluated for simultaneous attribute values in
multiple processes at different instants of time.
All four
of the distributed problems discussed in this section have particular
solutions, but all of them also illustrate the need to observe global states.
We will now look at a general approach to observing global states.
Without
global time identified by perfectly synchronized clocks, the ability to
identify successive states in an individual process does not translate into the
ability to identify successive states in distributed processes
We can
assemble meaningful global states from local states recorded at different local
times in many circumstances, but must do so carefully and recognize limits to
our capabilities
A general
system P of N processes pi (i=1..N)
pi‘s
history: history(pi)=hi=<ei0, ei1, ei2, …>
finite
prefix of pi‘s history: hi k= <ei0, ei1, ei2, …, eik>
state of
pi immediately before the kth event occurs: sik
global
history H=h1 U h2 U…U hN
A cut of
the system‘s execution is a subset of its global history that is a union of
prefix of process histories C=h1c1 U h2c2 U…U hNcN
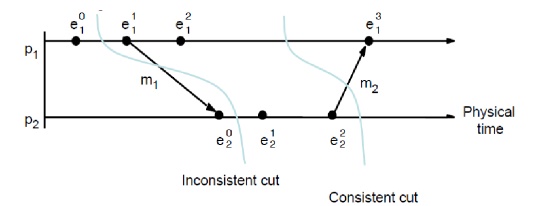
The
following figure gives an example of an inconsistent cutic and a consistent
cutcc. The distinguishing characteristic is that
cutic
includes the receipt of message m1 but not
the sending of it, while
cutcc
includes the sending and receiving of
m1 and cuts between the sending and
receipt of the message m2.
A
consistent cut cannot violate temporal causality by implying that a result
occurred before its cause, as in message m1 being received before the cut and
being sent after the cut.
Global
state predicates
A Global
State Predicate is a function that maps from the set of global process states
to True or False.
Detecting
a condition like deadlock or termination requires evaluating a Global State
Predicate.
A Global
State Predicate is stable: once a system enters a state where it is true, such
as deadlock or termination, it remains true in all future states reachable from
that state.
However,
when we monitor or debug an application, we are interested in non stable
predicates.
The
Snapshot Algorithm
Chandy
and Lamport defined a snapshot algorithm to determine global states of
distributed systems
The goal
of a snapshot is to record a set of process and channel states (a snapshot) for
a set of processes so that, even if the combination of recorded states may not
have occurred at the same time, the recorded global state is consistent
The algorithm
records states locally; it does not gather global states at one site.
The
snapshot algorithm has some assumptions
Neither
channels nor processes fail
Reliable
communications ensure every message sent is received exactly once
Channels
are unidirectional
Messages
are received in FIFO order
There is
a path between any two processes
Any
process may initiate a global snapshot at any time
Processes
may continue to function normally during a snapshot
Snapshot
Algorithm
For each
process, incoming channels are those which other processes can use to send it
messages. Outgoing channels are those it uses to send messages. Each process
records its state and for each incoming channel a set of messages sent to it.
The process records for each channel, any messages sent after it recorded its
state and before the sender recorded its own state. This approach can
differentiate between states in terms of messages transmitted but not yet
received
The algorithm is determined by two rules
Example
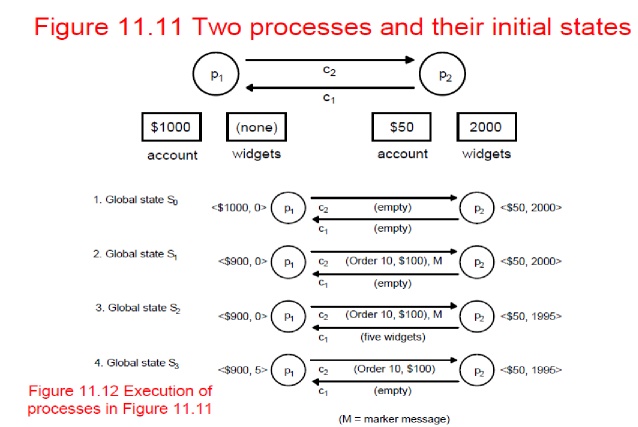
•Figure
11.11 shows an initial state for two processes.
•Figure
11.12 shows four successive states reached and identified after state
transitions by the two processes.
•Termination:
it is assumed that all processes will have recorded their states and channel
states a finite time after some process initially records its state.
Characterizing
a state
A
snapshot selects a consistent cut from the history of the execution. Therefore
the state recorded is consistent. This can be used in an ordering to include or
exclude states that have or have not recorded their state before the cut. This
allows us to distinguish events as pre-snap or post-snap events.
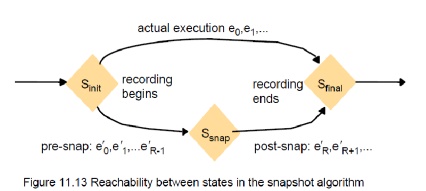
The
reachability of a state (figure 11.13) can be used to determine stable
predicates.
Introduction
Fundamental
issue: for a set of processes, how to coordinate their actions or to agree on
one or more values?
even no
fixed master-slave relationship between the components
Further
issue: how to consider and deal with failures when designing algorithms
Topics
covered
mutual
exclusion
how to
elect one of a collection of processes to perform a special role
multicast
communication
agreement
problem: consensus and byzantine agreement
Failure
Assumptions and Failure Detectors
Failure
assumptions of this chapter
Reliable
communication channels
Processes
only fail by crashing unless state otherwise
Failure
detector: object/code in a process that detects failures of other processes
unreliable
failure detector
One of
two values: unsuspected or suspected
Evidence
of possible failures
Example:
most practical systems
Each
process sends ―alive/I‘m here‖ message to everyone else
If not
receiving ―alive‖ message after timeout, it‘s suspected
maybe
function correctly, but network partitioned
reliable
failure detector
One of
two accurate values: unsuspected or failure – few practical systems
Related Topics