Chapter: Compilers : Principles, Techniques, & Tools : Machine-Independent Optimizations
Foundations of Data-Flow Analysis
Foundations of Data-Flow Analysis
1 Semilattices
2 Transfer Functions
3 The Iterative Algorithm for
General Frameworks
4 Meaning of a Data-Flow Solution
Having shown several useful examples of the data-flow abstraction, we
now study the family of data-flow schemas as a whole, abstractly. We shall
answer several basic questions about data-flow algorithms formally:
Under what circumstances is the
iterative algorithm used in data-flow analysis correct?
How precise is the solution
obtained by the iterative algorithm?
Will the iterative algorithm
converge?
What is the meaning of the
solution to the equations?
In Section 9.2, we addressed each of the questions above informally when
describing the reaching-definitions problem. Instead of answering the same
questions for each subsequent problem from scratch, we relied on analogies with
the problems we had already discussed to explain the new problems. Here we
present a general approach that answers all these questions, once and for all,
rigorously, and for a large family of data-flow problems. We first iden-tify
the properties desired of data-flow schemas and prove the implications of these
properties on the correctness, precision, and convergence of the data-flow
algorithm, as well as the meaning of the solution. Thus, to understand old
algorithms or formulate new ones, we simply show that the proposed data-flow
problem definitions have certain properties, and the answers to all the above
difficult questions are available immediately.
The concept of having a common theoretical framework for a class of
sche-mas also has practical implications. The framework helps us identify the
reusable components of the algorithm in our software design. Not only is
cod-ing effort reduced, but programming errors are reduced by not having to recode
similar details several times.
A data-flow analysis framework (D,V,A:F) consists
of
A direction of the data flow D, which is either F O R W A R D S or B A C K W A R D S .
A semilattice (see Section 9.3.1 for the definition), which includes a do-main
of values V and a meet operator A.
A family F of transfer functions from V to V. This family must include
functions suitable for the boundary conditions, which are constant transfer
functions for the special nodes E N T R Y
and E X I T in any flow graph.
1. Semilattices
A semilattice is a set V and a binary meet operator A such that
for all x, y, and z in V:
1 x A x — x (meet is idempotent).
2. x Ay = y A x (meet is commutative).
3 x A (y A z) = (x A y) A z (meet is associative).
A semilattice has a top
element, denoted T, such that
for all x in V, T A x — x.
Optionally, a semilattice may have a bottom
element, denoted ±, such that
for all x in V, _L A x = ±.
Partial Orders
As we shall see, the meet operator of a semilattice defines a partial
order on the values of the domain. A relation < is a partial order on a set V
if for all x, y, and z in V:
1. x < x (the partial order is reflexive).
2. If x < y and y < x, then x = y
(the partial order is antisymmetric).
3. If x < y and y < z, then x < z (the partial order is transitive).
The pair (V, <) is called a poset, or partially ordered set. It is
also convenient to have a < relation for a poset, defined as x < y if and
only if (x < y) and (x / y).
The Partial Order for a
Semilattice
It is useful to define a partial order < for a semilattice (V,
A). For all x and y in V, we define
x < y if and only if x A y =
x.
Because the meet operator A is idempotent, commutative, and associative,
the < order as defined is reflexive, antisymmetric, and transitive. To see
why, observe that:
Reflexivity: for all x, x < x. The proof is that x A x = x since meet
is idempotent.
• Antisymmetry: if x < y and
y < x, then x — y.
In proof, x
< y means x Ay = x and y <
x means y A x = y. By commutativity of A, x = (x Ay) = (y Ax) = y.
• Transitivity: if x < y and y < z, then x < z. In proof, x < y and y < z means that x
A y = x and y A z - y. Then (x A z)
= ((x A y) A z) = (x A (y A z)) =
(x A y) = x, using associativity of meet. Since x A z = x has been shown, we
have x < z, proving transitivity.
Example 9 . 1 8 : The meet
operators used in the examples in Section 9.2 are set union and set
intersection. They are both idempotent, commutative, and associative. For set
union, the top element is 0 and the bottom element is U, the universal set,
since for any subset
xo£U,$Ux = x and U
U x
= U. For set intersection, T is U and ± is 0. V,
the domain of values of the semilattice, is the set of all subsets of U, which
is sometimes called the power set of U and denoted 2U.
For all x and yinV,xUy = x implies x D y; therefore, the partial order
imposed by set union is D, set
inclusion. Correspondingly, the partial order imposed by set intersection is C,
set containment. That is, for set intersection, sets with fewer elements are
considered to be smaller in the partial order. How-ever, for set union, sets
with more elements are considered to
be smaller in the partial order. To say that sets larger in size are smaller in
the partial order is counterintuitive; however, this situation is an
unavoidable consequence of the definitions.6
As discussed in Section 9.2, there are usually many solutions to a set
of data-flow equations, with the greatest solution (in the sense of the partial
order <) being the most precise. For example, in reaching definitions, the
most precise among all the solutions to the data-flow equations is the one with
the smallest number of definitions, which corresponds to the greatest element
in the partial order defined by the meet operation, union. In available
expressions, the most precise solution is the one with the largest number of
expressions. Again, it is the greatest solution in the partial order defined by
intersection as the meet
operation. •
G r e a t e s t Lower B o u n d s
There is another useful relationship between the meet operation and the
partial ordering it imposes. Suppose (V, A) is a semilattice. A greatest lower bound (or gib) of domain elements x and y is an element g such
that
g<x,
g < y, and
3. If z is any element such
that z < x and z < y, then z < g.
It turns out that the meet of x
and y is their only greatest lower
bound. To see why, let g = x A y.
Observe that:
6 And if we defined the partial
order to be > instead of <, then the problem would surface when the meet
was intersection, although not for union.
Joins, Lub's, and Lattices
In symmetry to the gib operation on elements of a poset, we may define
the least upper bound (or lub) of elements x and y to be that
element b such that x <b, y <b, and if z is any element such that x < z and y < z, then b < z.
One can show that there is at most one such element b if it exists.
In a true lattice, there are
two operations on domain elements, the meet A, which we have seen, and the
operator join, denoted V, which gives
the lub of two elements (which therefore must always exist in the lattice). We
have been discussing only "semi" lattices, where only one of the meet
and join operators exist. That is, our semilattices are meet semilattices. One could
also speak of join semilattices, where
only the join operator exists, and in
fact some literature on program analysis does use the notation of join
semilattices. Since the traditional data-flow literature speaks of meet
semilattices, we shall also do so in this book.
g < x because (x A y) A x = x A y. The proof involves simple uses of associativity, commutativity, and idempotence. That is,
g Ax = ((x A y) A x) — (x A (y A x)) =
(x A (x A y)) =
((x Ax) Ay) =
(x Ay) = g
9 < y by a similar argument.
Suppose z is any element such that z < x and z < y. We claim z < g, and therefore, z cannot be
a gib of x and y unless it is also g. In proof: (zAg) = (zA (xAy)) — ((zAx) Ay).
Since z < x, we know (zAx) =
z, so (z Ag) = (z Ay). Since z < y,
we know z Ay = z, and therefore z Ag — z.
We have proven z < g and conclude g = x A y is the only gib of x and
y.
Lattice Diagrams
It often helps to draw the domain V
as a lattice diagram, which is a graph whose nodes are the elements of V, and whose edges are directed
downward, from x to y if y
< x. For example, Fig. 9.22 shows the set V for a reaching-definitions data-flow schema where there are three
definitions: d±, d2, and d%. Since < is an edge
is directed downward from any subset of these three definitions to each of its
supersets. Since < is transitive, we conventionally omit the edge from x to y
as long as there is another path from x
to y left in the diagram. Thus,
although {di,d2,dz} < {di}, we do
not draw this edge since it is represented by the path through {di,d2}, for example.
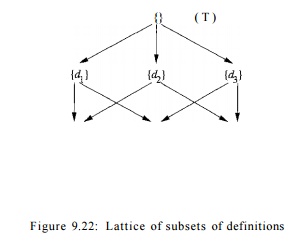
It is also useful to note that we can read the meet off such diagrams.
Since x A y is the gib, it is
always the highest z for which there
are paths downward to z from both x and y. For example, if x is {di}
and y is { ^ 2 } , then z in Fig.
9.22 is {G?I,G?2}5 which makes sense, because the
meet operator is union. The top element will appear at the top of the lattice
diagram; that is, there is a path downward from T to each element. Likewise,
the bottom element will appear at the bottom, with a path downward from every
element to _L.
Product Lattices
While Fig. 9.22 involves only three definitions, the lattice diagram of
a typical program can be quite large. The set of data-flow values is the power
set of the definitions, which therefore contains 2n elements
if there are n definitions in the
program. However, whether a definition reaches a program is independent of the
reachability of the other definitions. We may thus express the lattice7 of
definitions in terms of a "product lattice," built from one simple
lattice for each definition. That is, if there were only one definition d in the program, then the lattice would
have two elements: {}, the empty set, which is the top element, and {d}, which is the bottom element.
2. The meet A for the product
lattice is defined as follows. If (a,
b) and (a1, b') are domain elements of
the product lattice, then

So we might ask under what circumstances does (a AA a', bAB b') = (a,
&)? That happens exactly when a A A a' — a and b AB b' — b. But these two
conditions are the same as a <A OJ and b <B b'.
The product of lattices is an associative operation, so one can show
that the rules (9.19) and (9.20) extend to any number of lattices. That is, if
we are given lattices (Ai, Ai) for i =
1, 2 , . . . , k, then the product of all k lattices, in this order, has domain
A1 x A2 x • • • x Ak, a meet operator
defined by
( a i , a 2 ) - • • ,ak) A
(h,b2,... ,bk) = (ax Ai
h,a2 A2 b2,... ,ak Ak
h)
and a partial order defined by
(oi, a2,... , ak) < (bi, b2,... , bk) if and only if a« < bi for
all i.
Height of a
Semilattice
We may learn something about the rate of convergence of a data-flow
analysis algorithm by studying the "height" of the associated
semilattice. An ascending chain in a poset (V, <) is a sequence
where x1 < x2 < ... < xn. The height of a semilattice is
the largest number of < relations in any ascending chain; that is, the
height is one less than the number of elements in the chain. For
example, the height of the reaching definitions semilattice for a
program with
n definitions is n.
Showing convergence of an iterative data-flow algorithm is much easier
if the semilattice has finite height. Clearly, a lattice consisting of a finite
set of values will have a finite height; it is also possible for a lattice with
an infinite number of values to have a finite height. The lattice used in the
constant propagation algorithm is one such example that we shall examine
closely in Section 9.4.
2. Transfer Functions
The family of transfer functions F
: V -» V in a data-flow framework has the following properties:
1. F has an identity function i", such that I(x) = x for all x in
V.
2. F is closed under composition; that is, for any two functions / and g
in F, the function h defined by
h(x) = g(f(x)) is in F.
Monotone Frame works
To make an iterative algorithm for data-flow analysis work, we need for
the data-flow framework to satisfy one more condition. We say that a framework
is monotone if when we apply any transfer function / in F to two members of V,
the first being no greater than the second, then the first result is no greater
than the second result.
3. The
Iterative Algorithm for General Frameworks
We can generalize Algorithm 9.11 to make it work for a large variety of
data-flow problems.
Algorithm 9 . 2 5 : Iterative
solution to general data-flow
frameworks.
INPUT: A data-flow framework with the following components:
1. A data-flow graph, with
specially labeled E N T R Y and E X I T nodes,
2. A direction of the data-flow D,
3. A set of values V,
4. A meet operator A,
5. A set of functions F,
where fs in F is the transfer function
for block B,
and
A constant value GENTRY or f EXIT in V, representing the boundary condition
for forward and backward frameworks, respectively.
OUTPUT: Values in V
for IN[B] and OUT [B] for each block B in the data-flow graph.
METHOD: The algorithms for solving forward and backward data-flow prob-lems are
shown in Fig. 9.23(a) and 9.23(b), respectively. As with the familiar iterative
data-flow algorithms from Section 9.2, we compute IN and O U T for each
block by successive approximation. •
It is possible to write the forward and backward versions of Algorithm
9.25 so that a function implementing the meet operation is a parameter, as is a
function that implements the transfer function for each block. The flow graph
itself and the boundary value are also parameters. In this way, the compiler
implementor can avoid recoding the basic iterative algorithm for each data-flow
framework used by the optimization phase of the compiler.
We can use the abstract framework discussed so far to prove a number of
useful properties of the iterative algorithm:
If Algorithm 9.25 converges, the
result is a solution to the data-flow equa-tions.
If the framework is monotone,
then the solution found is the maximum fixedpoint (MFP) of the data-flow
equations. A maximum fixedpoint is a
solution with the property that in any other solution, the values of IN[B] and O U T [B] are < the
corresponding values of the MFP .
If the semilattice of the framework is monotone and of finite height,
then the algorithm is guaranteed to converge.
We shall argue these points assuming that the framework is forward. The
case of backwards frameworks is essentially the same. The first property is
easy to show. If the equations are not satisfied by the time the while-loop
ends, then there will be at least one change to an OUT (in the forward case) or
IN (in the backward case), and we must go around the loop again.
4. Meaning of a Data-Flow
Solution
We now know that the solution found using the iterative algorithm is the
max-imum fixedpoint, but what does the result represent from a
program-semantics point of view? To understand the solution of a data-flow
framework (D, F, V, A), let us first
describe what an ideal solution to the framework would be. We show that the
ideal cannot be obtained in general, but that Algorithm 9.25 approxi-mates the
ideal conservatively.
The Ideal
Solution
Without
loss of generality, we shall assume for now that the data-flow framework of
interest is a forward-flowing problem. Consider the entry point of a basic
block B. The ideal solution begins by
finding all the possible execution
paths leading from the program entry to the beginning of B. A path is "possible" only if there is some computation
of the program that follows exactly that path. The ideal solution would then
compute the data-flow value at the end of each possible path and apply the meet
operator to these values to find their greatest lower bound. Then no execution
of the program can produce a smaller value for that program point. In addition,
the bound is tight; there is no greater data-flow value that is a gib for the
value computed along every possible path to B
in the flow graph.
Related Topics