Chapter: Software Testing : Test Case Design
Boundary Value Analysis
Boundary Value Analysis
Equivalence
class partitioning gives the tester a useful tool with which to develop black
box based-test cases for the software-under-test. The method requires that a
tester has access to a specification of input/output behavior for the target
software. The test cases developed based on equivalence class partitioning can
be strengthened by use of an technique called boundary value analysis. With
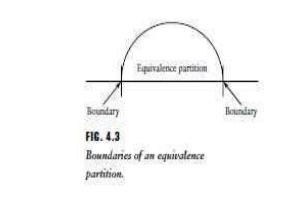
experience, testers soon realize that many defects occur directly on, and above
and below, the edges of equivalence classes. Test cases that consider these boundaries
on both the input and output spaces as shown in Figure 4.3 are often valuable
in revealing defects. Whereas equivalence class partitioning directs the tester
to select test cases from any element of an equivalence class, boundary value
analysis requires that the tester select elements close to the edges, so that
both the upper and lower edges of an equivalence class are covered by test
cases. As in the case of equivalence class partitioning, the ability to develop
high quality test cases with the use of boundary values requires experience.
The rules-of-thumb described below are useful for getting started with boundary
value analysis.
1. If an input condition for the
software-under-test is specified as a range of values, develop valid test
cases for the ends of the range, and invalid test cases for possibilities just
above and below the ends of the range. For example if a specification states
that an input value for a module must lie in the range between _1.0 and _1.0,
valid tests that include values for ends of the range, as well as invalid test
cases for values just above and below the ends, should be included. This would
result in input values of _1.0, _1.1, and 1.0, 1.1.
2. If an
input condition for the software-under-test is specified as a number of values, develop valid test
cases for the minimum and maximum numbers as well as invalid test cases that
include one lesser and one greater than the maximum and minimum. For example,
for the real-estate module mentioned previously that specified a house can have
one to four owners, tests that include 0,1 owners and 4,5 owners would be
developed. The following is an example of applying boundary value analysis to
output equivalence classes. Suppose a table of 1 to 100 values is to be
produced by a module. The tester should select input data to generate an output
table of size 0,1, and 100 values, and if possible 101 values.
3. If the
input or output of the software-under-test is an ordered set, such as a table
or a linear list, develop tests that focus on the first and last elements of
the set. It is important for the tester to keep in mind that equivalence class
partitioning and boundary value analysis apply to testing both inputs and
outputs of the software-under-test, and, most importantly, conditions are not combined for equivalence class
partitioning or boundary value analysis. Each condition is considered
separately, and test cases are developed to insure coverage of all the
individual conditions. An example follows.
An Example of the Application of Equivalence Class
Partitioning and Boundary Value Analysis
Suppose
we are testing a module that allows a user to enter new widget identifiers into
a widget data base. We will focus only on selecting equivalence classes and
boundary values for the inputs. The input specification for the module states
that a widget identifier should consist of 3-15 alphanumeric characters of
which the first two must be letters. We have three separate conditions that
apply to the input: (i) it must consist of alphanumeric characters, (ii) the
range for the total number of characters is between 3 and 15, and, (iii) the
first two characters must be letters. Our approach to designing the test cases
is as follows. First we will identify input equivalence classes and give them
each an identifier. Then we will augment these with the results from boundary
value analysis. Tables will be used to organize and record our findings. We
will label the equivalence classes with an identifier ECxxx, where xxx is an
integer whose value is one or greater. Each class will also be categorized as
valid or invalid for the input domain.
First we
consider condition 1, the requirement for alphanumeric characters. This is a
―must be‖ condition. We derive two
equivalence classes.
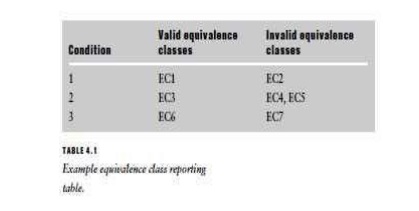
EC1. Part
name is alphanumeric, valid. EC2. Part name is not alphanumeric, invalid.
Then we
treat condition 2, the range of allowed characters 3-15.
EC3. The
widget identifier has between 3 and 15 characters, valid. EC4. The widget
identifier has less than 3 characters, invalid. EC5. The widget identifier has
greater than 15 characters, invalid.
Finally
we treat the ―must be‖ case for
the first two characters.
EC6. The
first 2 characters are letters, valid.
EC7. The
first 2 characters are not letters, invalid.
Note that
each condition was considered separately. Conditions are not combined to select equivalence classes. The tester may find
later on that a specific test case covers more than one equivalence class. The
equivalence classes selected may be recorded in the form of a table as shown in
Table 4.1. By inspecting such a table the tester can confirm that all the
conditions and associated valid and invalid equivalence classes have been
considered. Boundary value analysis is now used to refine the results of
equivalence class partitioning. The boundaries to focus on are those in the
allowed length for the widget identifier. An experienced tester knows that the
module could have defects related to handling widget identifiers that are of
length equal to, and directly adjacent to, the lower boundary of 3 and the
upper boundary of 15. A simple set of abbreviations can be used to represent
the bounds groups. For example:
BLB—a value just below the lower
bound
LB—the value on the lower boundary
ALB—a value just above the lower
boundary
BUB—a value just below the upper
bound
UB—the value on the upper bound
AUB—a value just above the upper
bound
For our
example module the values for the bounds groups are:
BLB— 2 BUB—14 LB—3 UB—15 ALB—4 AUB—16
Note that
in this discussion of boundary value analysis, values just above the lower
bound (ALB) and just below the upper bound (BUB) were selected. These are both
valid cases and may be omitted if the tester does not believe they are
necessary. The next step in the test case design process is to select a set of
actual input values that covers all the equivalence classes and the boundaries.
Once again a table can be used to organize the results. Table 4.2 shows the
inputs for the sample module. Note that the table has the module name,
identifier, a date of creation for the test input data, and the author of the
test cases.
Table 4.2
only describes the tests for the module in terms of inputs derived from
equivalence classes and boundaries. Chapter 7 will describe the components
required for a complete test case. These include test inputs as shown in Table
4.2, along with test conditions and expected outputs.
Test logs
are used to record the actual outputs and conditions when execution is
complete. Actual outputs are compared to expected outputs to determine whether
the module has passed or failed the test. Note that by inspecting the completed
table the tester can determine whether all the equivalence classes and
boundaries have been covered by actual input test cases. For this example the
tester has selected a total of nine test cases. The reader should also note
then when selecting inputs based on equivalence classes, a representative value
at the midpoint of the bounds of each relevant class should be included as a
typical case. In this example, a test case was selected with 9 characters, the
average of the range values of 3 and 15 (test case identifier 9). The set of
test cases presented here is not unique: other sets are possible that will also
cover all the equivalence classes and bounds. Based on equivalence class
partitioning and boundary value analysis these test cases should have a high
possibility of revealing defects in the module as opposed to selecting test
inputs at random from the input domain. In the latter case there is no way of
estimating how productive the input choices would be. This approach is also a
better alternative to exhaustive testing where many combinations of characters,
both valid and invalid cases, would have to be used. Even for this simple
module exhaustive testing would not be feasible.
Related Topics