Chapter: 12th Computer Science : Chapter 13 : Database concepts and MySql : Python and CSV Files
Writing Data Into Different Types in Csv Files
Writing Data Into Different Types
in Csv Files
As you know Python provides an easy way to work
with CSV file and has csv module to read and write data in the csv file. In the
previous topics, You have learned how to read CSV files in Python. In similar
way, You can also write a new or edit an existing CSV files in Python.

1. Creating A New Normal CSV File
When you have a set of data that you would like
to store inside a CSV file, it’s time to do the opposite and use the write
function.
The csv.writer() method returns a writer object which converts the
user’s data into delimited strings on the given file-like object. The
writerow() method writes a row of data into the specified file.
The syntax for csv.writer() is
csv.writer(fileobject,delimiter,fmtparams)
where
fileobject : passes the path and the mode of the file.
delimiter : an optional parameter containing the standard dilects like , | etc
can be omitted.
fmtparams : optional parameter which help to override the default values of the
dialects like skipinitialspace,quoting etc. can be omitted.
You can create
a normal CSV file using writer() method of csv module having default delimiter
comma (,)
Here’s an example.
The following Python program converts a List of
data to a CSV file called “Pupil.csv” that uses, (comma) as a value separator.
Import csv
csvData = [[‘Student’, ‘Age’],
[‘Dhanush’, ‘17’], [‘Kalyani’, ‘18’], [‘Ram’, ‘15’]] with
open(‘c:\\pyprg\\ch13\\Pupil.csv’, ‘w’) as CF:
writer = csv.writer(CF) # CF is the file object
writer.writerows(csvData) # csvData is the List name
CF.close()
When you open the “Pupil.csv” file with a text
editor, it will show the content as follows.

In the above program, csv.writer() method
converts all the data in the list “csvData” to strings and create the content
as file like object. The writerows () method writes all the data in to the new
CSV file “Pupil.csv”.
2. Modifying An Existing File
Making some changes in the data of the existing
file or adding more data is called modification .For example the “student.csv”
file contains the following data.
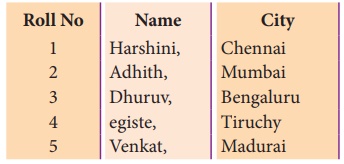
The following program modify the “student.csv”
file by modifying the value of an existing row in student.csv
import csv
row = [‘3’, ‘Meena’,’Bangalore’]
with open(‘student.csv’, ‘r’) as
readFile:
reader = csv.reader(readFile)
lines = list(reader) # list()- to store each row of data as a
list
lines[3] = row
with open(‘student.csv’, ‘w’) as
writeFile:
#returns the writer object which converts the user
data with delimiter
writer = csv.writer(writeFile)
#writerows()method writes multiple rows to a csv file
writer.writerows(lines)
readFile.close()
writeFile.close()
When we open the student.csv file with text
editor, then it will show:
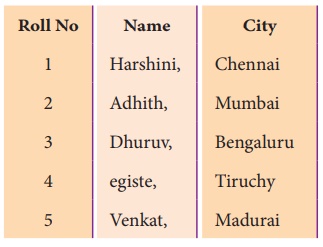
In the above program,the third row of
“student.csv” is modified and saved. First the “student.csv” file is read by
using csv.reader() function. Then, the list() stores each row of the file. The
statement “lines[3] = row”, changed the third row of the file with the new
content in “row”. The file object writer using writerows (lines) writes the
values of the list to “student.csv” file.
(i) ADDING NEW ROW
Sometimes, you may need to add new rows in the
existing CSVfile. Adding a new row at the end of the file is called appending a
row.
The following program add a new row to the
existing “student.csv” file.
import csv
row = [‘6’, ‘Sajini ‘, ‘Madurai’]
with open(‘student.csv’, ‘a’) as
CF: # append mode to add data at the end writer
= csv.writer(CF)
writer.writerow(row) # writerow() method write a single row of
data in file CF.close()
When “student.csv” file is opened with a text
editor, it displays as follows
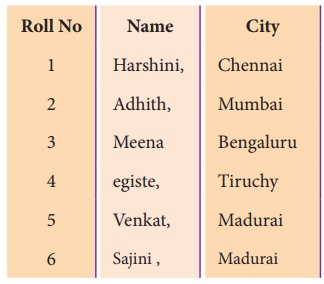
In the above program, a new row is appended
into “student.csv”. For this, purpose only the CSV file is opened in ‘a’ append
mode. Append mode write the value of row after the last line of the
“student.csv file.”
3. CSV Files With Quotes
You can write the csv file with quotes, by
registering new dialects using csv.register_dialect()
class of csv module. The following program explains this.
import csv
info = [[‘SNO’, ‘Person’, ‘DOB’],
[‘1’, ‘Madhu’, ‘18/12/2001’],
[‘2’, ‘Sowmya’,’19/2/1998’],
[‘3’, ‘Sangeetha’,’20/3/1999’],
[‘4’, ‘Eshwar’, ‘21/4/2000’],
[‘5’, ‘Anand’, ‘22/5/2001’]]
csv.register_dialect(‘myDialect’,quoting=csv.QUOTE_ALL)
with
open(‘c:\\pyprg\\ch13\\person.csv’, ‘w’) as f:
writer = csv.writer(f,
dialect=’myDialect’)
for row in info:
writer.writerow(row)
f.close()
When you open “person.csv” file, we get
following output :
“SNO”,”Person”,”DOB”
”1”,”Madhu”,”18/12/2001”
”2”,”Sowmya”,”19/2/1998”
”3”,”Sangeetha”,”20/3/1999”
”4”,”Eshwar”,”21/4/2000”
“5”,”Anand”,”22/5/2001”
In above program, a dialect named myDialect
is registered(declared). Quoting=csv.
QUOTE_ALL allows to write the double quote on
all the values.
4. CSV Files With Custom Delimiters
A delimiter is a string used to separate
fields. The default value is comma(,). You can have custom delimiter in CSV
files by registering a new dialect with the help of csv.register_dialect().This example Program is written using the
custom delimiter pipe(|)
import csv
info = [[‘SNO’, ‘Person’, ‘DOB’],
[‘1’, ‘Madhu’, ‘18/12/2001’],
[‘2’, ‘Sowmya’,’19/2/1998’],
[‘3’, ‘Sangeetha’,’20/3/1999’],
[‘4’, ‘Eshwar’, ‘21/4/2000’],
[‘5’, ‘Anand’, ‘22/5/2001’]]
csv.register_dialect(‘myDialect’,delimiter
= ‘|’)
with
open(‘c:\pyprg\ch13\dob.csv’, ‘w’) as f:
writer = csv.writer(f,
dialect=’myDialect’)
for row in info:
writer.writerow(row)
f.close()
When we open “dob.csv” file, we get the
following output:
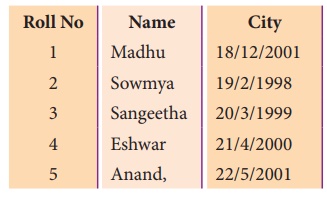
In the above program, a dialect with delimiter
as pipe(|)is registered. Then the list “info” is written into the CSV file
“dob.csv”.
5. CSV File With A Line Terminator
A Line Terminator is a string used to terminate lines produced by
writer. The default value is \r or \n. We can write csv
file with a line terminator in Python by registering new dialects using
csv.register_dialect() class of csv module. For Example
import csv
Data = [[‘Fruit’, ‘Quantity’],
[‘Apple’, ‘5’], [‘Banana’, ‘7’], [‘Mango’, ‘8’]]
csv.register_dialect(‘myDialect’,
delimiter = ‘|’, lineterminator = ‘\n’) with open(‘c:\\pyprg\\ch13\\line.csv’,
‘w’) as f:
writer = csv.writer(f,
dialect=’myDialect’)
writer.writerows(Data)
f.close()
When we open the line.csv file, we get
following output with spacing between lines:
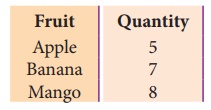
In the above code, the new dialect “myDialect
uses the delimiter=’|’ where a | (pipe) is considered as column separator. The
line terminator=’\r\n\r\n’ separates each row and display the data after every
two lines.
6. CSV File with quote characters
You can write the CSV file with custom quote
characters, by registering new dialects using csv.register_dialect() class of
csv module.
import csv
csvData = [[‘SNO’,’Items’],
[‘1’,’Pen’], [‘2’,’Book’], [‘3’,’Pencil’]]
csv.register_dialect(‘myDialect’,delimiter = ‘|’,quotechar = ‘”’,
quoting=csv.QUOTE_ALL)
with
open(‘c:\\pyprg\\ch13\\quote.csv’, ‘w’) as csvFile:
writer = csv.writer(csvFile,
dialect=’myDialect’)
writer.writerows(csvData)
print(“writing completed”)
csvFile.close()
When you open the “quote.csv” file in notepad,
we get following output:
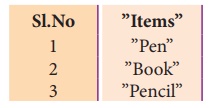
In the above program, myDialect uses pipe (|)
as delimiter and quotechar as doublequote ‘”’ to write inside the file.
7. Writing CSV File Into A Dictionary
Using DictWriter() class of csv module, we can
write a csv file into a dictionary. It creates an object which maps data into a
dictionary. The keys are given by the fieldnames parameter. The following
program helps to write the dictionary in to file.
import csv
data = [{‘MOUNTAIN’ : ‘Everest’,
‘HEIGHT’: ‘8848’},
{‘MOUNTAIN’ : ‘Anamudi ‘,
‘HEIGHT’: ‘2695’},
{‘MOUNTAIN’ : ‘Kanchenjunga’,
‘HEIGHT’: ‘8586’}]
with
open(‘c:\\pyprg\\ch13\\peak.csv’, ‘w’) as CF:
fields = [‘MOUNTAIN’, ‘HEIGHT’]
w = csv.DictWriter(CF,
fieldnames=fields)
w.writeheader()
w.writerows(data)
print(“writing completed”)
CF.close()
When you open the “peak.csv” file in notepad,
you get the following output:
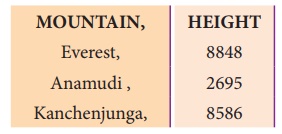
In the above program, use fieldnames as
headings of each column in csv file. Then, use a DictWriter() to write
dictionary data into “peak.csv” file.
Writing Dictionary Into CSV File With Custom Dialects
import csv
csv.register_dialect(‘myDialect’,
delimiter = ‘|’, quoting=csv.QUOTE_ALL)
with
open(‘c:\\pyprg\\ch13\\grade.csv’, ‘w’) as csvfile:
fieldnames = [‘Name’, ‘Grade’]
writer = csv.DictWriter(csvfile,
fieldnames=fieldnames, dialect=”myDialect”)
writer.writeheader()
writer.writerows([{‘Grade’: ‘B’,
‘Name’: ‘Anu’},
{‘Grade’: ‘A’, ‘Name’: ‘Beena’},
{‘Grade’: ‘C’, ‘Name’: ‘Tarun’}])
print(“writing completed”)
When we open grade.csv file, it will contain
following output:

In the above program, a custom dialect called
myDialect with pipe (|) as delimiter uses the fieldnames as headings of each
column to write in a csv file. Finally, we use a DictWriter() to write
dictionary data into “grade.csv” file.
8. Getting Data At Runtime And Writing It In a CSV File
You can even accept the data through keyboard
and write in to a CSV file. For example the following program accept data from
the user through key board and stores it in the file called “dynamicfile.csv”.
It also displays the content of the file.
import csv
with
open(‘c:\\pyprg\\ch13\\dynamicfile.csv’, ‘w’) as f:
w = csv.writer(f)
ans=’y’
while (ans==’y’):
name = input(“Name?: “)
date = input(“Date of birth: “)
place = input(“Place: “)
w.writerow([name, date, place])
ans=input(“Do you want to enter
more y/n?: “)
F=open(‘c:\\pyprg\\ch13\\dynamicfile.csv’,’r’)
reader = csv.reader(F)
for row in reader:
print(row)
F.close()
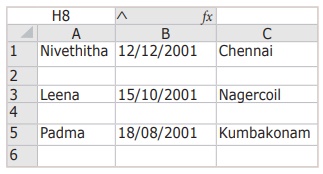
OUTPUT
Name?: Nivethitha
Date of birth: 12/12/2001
Place: Chennai
Do you want to enter more y/n?: y
Name?: Leena
Date of birth: 15/10/2001
Place: Nagercoil
Do you want to enter more y/n?: y
Name?: Padma
Date of birth: 18/08/2001
Place: Kumbakonam
Do you want to enter more y/n?: n
[‘Nivethitha’, ‘12/12/2001’,
‘Chennai’] []
[‘Leena’, ‘15/10/2001’,
‘Nagercoil’] []
[‘Padma’, ‘18/08/2001’,
‘Kumbakonam’]
Related Topics