Chapter: 12th Computer Science : Chapter 13 : Database concepts and MySql : Python and CSV Files
Read and write a CSV file Using Python
Read and write a CSV file Using Python
Python provides a module named CSV, using this you can do several
operations on the CSV files. The CSV library contains objects and other code to
read, write, and process data from
and to CSV files.
1. Read a CSV File Using Python
There are two ways to read a CSV file.
1. Use the csv module’s reader function
2. Use the DictReader class.
When you want to read from or write to a file
,you need to open it. Once the reading is over it needs to be closed. So that,
resources that are tied with the file are freed. Hence, in Python, a file
operation takes place in the following order

Python has a built-in function open() to open a file. This function returns a file object, also called a
handle, as it is used to read or modify the file accordingly.
For Example
>>>f =
open("sample.txt") # open file
in current directory and f is file object
>>> f =
open('c:\\pyprg\\ch13sample5.csv') # specifying full path
You can specify the mode while opening a file.
In mode, you can specify whether you want to read 'r', write 'w' or append
'a' to the file. you can also
specify “text or binary” in which the file is to be opened.
The default is reading in text mode. In this mode, while reading from the file the
data would be in the format of strings.
On the other hand, binary mode returns bytes and this is the mode to be used when dealing with non-text files like image or
exe files.
Python File Modes
Mode : Description
'r' : Open a file for reading.
(default)
'w' : Open a file for writing.
Creates a new file if it does not exist or truncates the file if it exists.
'x' : Open a file for exclusive
creation. If the file already exists, the operation fails.
'a' : Open for appending at the
end of the file without truncating it. Creates a new file if it does not exist.
't' : Opren in text mode.
(default)
'b' : Open in binary mode.
'+' : Open a file for updating
(reading and writing)
f=open("sample.txt")
#equivalent to 'r' or 'rt'
f = open("sample.txt",'w') # write in
text mode
f = open("image1.bmp",'r+b') # read
and write in binary mode
Python has a garbage collector to clean up unreferenced objects but, one must not rely on it to close the file.
f = open("test.txt") #
since no mode is specified the default mode rt is used
# perform file operations
f.close()
The above method is not entirely safe. If an exception
occurs when you are performing some operation with the file, the code exits
without closing the file. The best way to do this is using the “with” statement. This ensures that the
file is closed when the block inside with
is exited. You need not to explicitly call the close() method. It is done
internally.
with
open("test.txt",’r’) as f:
# f is file object to perform file operations
Closing a file will free up the resources that were tied with the
file and is done using Python close() method.
f = open("sample.txt")
perform file operations
f.close()
(i) CSV
Module’s Reader Function
You can read the contents of CSV file with the
help of csv.reader() method. The reader function is designed to take each line of the file and make a list of
all columns. Then, you just
choose the column you want the variable data for. Using this method one can
read data from csv files of different formats like quotes (" "), pipe
(|) and comma (,).
The syntax for csv.reader() is
csv.reader(fileobject,delimiter,fmtparams)
Where
file object :- passes
the path and the mode of the file
delimiter :- an
optional parameter containing the standard dilects like , | etc can be omitted
fmtparams: optional
parameter which help to override the default values of the dialects like
skipinitialspace,quoting etc. Can be omitted

(a) CSV file with default delimiter comma (,)
The following program read a file called
“sample1.csv” with default delimiter comma (,) and print row by row.
#importing csv
import csv
#opening the csv file which is in different location
with read mode with open('c:\\pyprg\\sample1.csv', 'r') as F:
#other way to open the file is f=
('c:\\pyprg\\sample1.csv', 'r')
reader = csv.reader(F)
#printing each line of the Data row by row print(row)
F.close()
OUTPUT
['SNO', 'NAME', 'CITY']
['12101', 'RAM', 'CHENNAI']
['12102', 'LAVANYA', 'TIRUCHY']
['12103', 'LAKSHMAN', 'MADURAI']
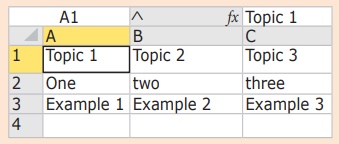
(b) CSV files- data with Spaces at the beginning
Consider the following file “sample2.csv”
containing the following data when opened through notepad

The following program read the file through
Python using “csv.reader()”.
import csv
csv.register_dialect('myDialect',delimiter
= ',',skipinitialspace=True)
F=open('c:\\pyprg\\sample2.csv','r')
reader = csv.reader(F,
dialect='myDialect')
for row in reader:
print(row)
F.close()
OUTPUT
['Topic1', 'Topic2', 'Topic3']
['one', 'two', 'three']
['Example1', 'Example2',
'Example3']
As you can see in “sample2.csv” there are
spaces after the delimiter due to which the output is also displayed with
spaces.
These whitespaces can be removed, by
registering new dialects using csv.register_dialect()
class of csv module. A dialect describes
the format of the csv file that is to be read. In dialects the parameter “skipinitialspace” is used for removing
whitespaces after the delimiter.
The following program reads “sample2.csv” file, which contains
spaces after the delimiter.
import csv
csv.register_dialect('myDialect',delimiter
= ',',skipinitialspace=True)
F=open('c:\\pyprg\\sample2.csv','r')
reader = csv.reader(F,
dialect='myDialect')
for row in reader:
print(row)
F.close()
OUTPUT
['Topic1', 'Topic2', 'Topic3']
['one', 'two', 'three']
['Example1', 'Example2',
'Example3']
(c) CSV File-Data With Quotes
You can read the csv file with quotes, by
registering new dialects using csv.register_dialect() class of csv module.
Here, we have quotes.csv file with following
data.
SNO,Quotes
1, "The secret to getting
ahead is getting started."
2, "Excellence is a
continuous process and not an accident."
3, "Work hard dream big
never give up and believe yourself."
4, "Failure is the
opportunity to begin again more intelligently."
5, "The successful warrior
is the average man, with laser-like focus."
The following Program read “quotes.csv” file,
where delimiter is comma (,) but the quotes are within quotes (“ “).
import csv
csv.register_dialect('myDialect',delimiter
= ',',quoting=csv.QUOTE_ALL,
skipinitialspace=True)
f=open('c:\\pyprg\\quotes.csv','r')
reader = csv.reader(f,
dialect='myDialect')
for row in reader:
print(row)
OUTPUT
['SNO', 'Quotes']
['1', 'The secret to getting
ahead is getting started.']
['2', 'Excellence is a continuous
process and not an accident.']
['3', 'Work hard dream big never
give up and believe yourself.'] ['4', 'Failure is the opportunity to begin
again more intelligently.']
['5', 'The successful warrior is
the average man, with laser-like focus. ']
In the above program, register a dialect with
name myDialect. Then, we used csv.
QUOTE_ALL to display all the characters after double quotes.
(d) CSV files with Custom Delimiters
You can read CSV file having custom delimiter by registering a new
dialect with the help of csv.register_dialect().
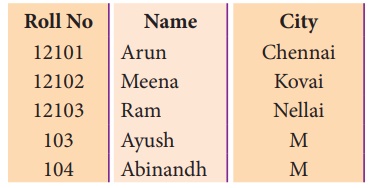
In the following file called “sample4.csv”,each
column is separated with | (Pipe symbol)
The following program read the file
“sample4.csv” with user defined delimiter “|”
import csv
csv.register_dialect('myDialect',
delimiter = '|')
with
open('c:\\pyprg\\sample4.csv', 'r') as f:
reader = csv.reader(f,
dialect='myDialect')
for row in reader:
print(row)
f.close()
OUTPUT
['RollNo', 'Name', 'City']
['12101', 'Arun', 'Chennai']
['12102', 'Meena', 'Kovai']
['12103', 'Ram', 'Nellai']

In the above program, a new dialects called
myDialect is registered. Use the delimiter=| where a pipe (|) is considered as
column separator.
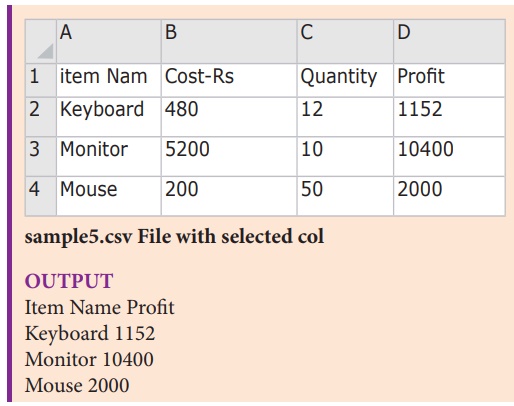
2. Read a specific column In a File
To get the specific columns like only Item Name
and profit for the “sample5.csv” file .Then you have to do the following:
import csv
#opening the csv file which is in different location
with read mode
f=open("c:\\pyprg\\ch13sample5.csv",'r')
#reading the File with the help of csv.reader()
readFile=csv.reader(f)
#printing the selected column
for col in readFile :
print col[0],col[3]
f.close()
sample5.csv File in Excel
3. Read A CSV File And Store It In A List
In this topic you are going to read a CSV file
and the contents of the file will be stored as a list. The syntax for storing
in the List is
list = [] # Start as the empty
list
list.append(element) # Use
append() to add elements
For example all the row values of “sample.csv”
file is stored in a list using the following program
import csv
#other way of declaring the filename
inFile= 'c:\\pyprg\\sample.csv'
F=open(inFile,'r')
reader = csv.reader(F)
#declaring
array
arrayValue = []
#displaying the content of the list
for row in reader:
arrayValue.append(row)
print(row)
F.close()
sample.csv opened in MS-Excel
sample5.csv File with selected col
OUTPUT
['Topic1', 'Topic2', 'Topic3']
[' one', 'two', 'three']
['Example1', 'Example2',
'Example3']
4. Read A CSV File And Store A Column Value In A List For Sorting
In this program you are going to read a
selected column from the “sample6.csv” file by getting from the user the column
number and store the content in a list.
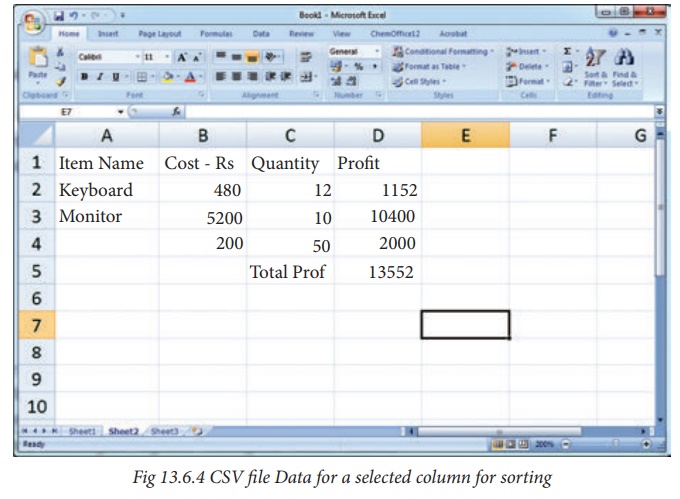
Since the row heading is also get sorted, to
avoid that the first row should be skipped. This is can be done by using the
command “next()”. The list is sorted and displayed.
#sort a selected column given by user leaving the
header column
import csv
#other way of
declaring the filename
inFile= ‘c:\\pyprg\\sample6.csv’
# openning the csv file which is in the same location
of this
python file
F=open(inFile,’r’)
#reading the File with the help of csv.reader() reader = csv.reader(F)
#skipping the first row(heading) next(reader)
#declaring a list
arrayValue = []
a = int(input (“Enter the column
number 1 to 3:-“))
#sorting a particular column-cost
for row in reader:
arrayValue.append(row[a]) arrayValue.sort()
for row in arrayValue: print
(row)
F.close()
OUTPUT
Enter the column number 1 to 3:-
2
50
12
10
5. Sorting A CSV File With A Specified Column
In this program you are going to see the
“sample8.csv” file’s entire content is transferred to a list. Then the list of
rows is sorted and displayed in ascending order of quantity. To sort by more than
one column you can use itemgetter with multiple indices: operator .itemgetter
(1,2), The content of “sample8.csv” is
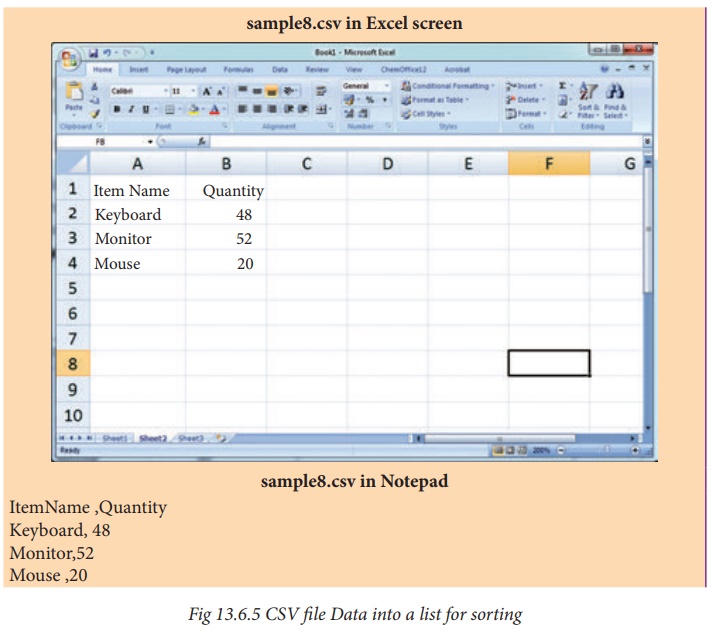
The following program do the task mentioned
above using operator.itemgetter(col_no)
#Program to sort the entire row by using a specified
column.
#declaring multiple header files import csv ,operator
#One more way to read the file
data =
csv.reader(open(‘c:\\PYPRG\\sample8.csv’))
next(data) #(to omit the header)
#using operator module for sorting multiple columns
sortedlist = sorted (data,
key=operator.itemgetter(1)) # 1 specifies we want to sort
# according to second column
for row in sortedlist:
print(row)
OUTPUT
[‘Mouse ‘, ‘20’]
[‘Keyboard ‘, ‘48’]
[‘Monitor’, ‘52’]
Note
The sorted() method sorts the elements of a
given item in a specific order – Ascending or Descending. Sort() method which
performs the same way as sorted(). Only difference, sort() method doesn’t
return any value and changes the original list itself.
6. Reading CSV File Into A Dictionary
To read a CSV file into a dictionary can be
done by using DictReader class of
csv module which works similar to the reader() class but creates an object
which maps data to a dictionary. The keys are given by the fieldnames as
parameter. DictReader works by
reading the first line of the CSV and using each comma separated value in this
line as a dictionary key. The
columns in each subsequent row then behave like dictionary values and can be
accessed with the appropriate key (i.e. fieldname).
If the first row of your CSV does not contain
your column names, you can pass a fieldnames parameter into the DictReader’s
constructor to assign the dictionary keys manually.
The main difference between the csv.reader()
and DictReader() is in simple terms csv. reader and csv.writer work with list/tuple, while csv.DictReader and
csv.DictWriter work with dictionary. csv.DictReader and csv.DictWriter take
additional argument fieldnames that are used as dictionary keys.
For Example Reading “sample8.csv” file into a dictionary
import csv
filename =
‘c:\\pyprg\\sample8.csv’
input_file
=csv.DictReader(open(filename,’r’))
for row in input_file:
print(dict(row)) #dict() to print data
OUTPUT
{‘ItemName ‘: ‘Keyboard ‘,
‘Quantity’: ‘48’}
{‘ItemName ‘: ‘Monitor’,
‘Quantity’: ‘52’}
{‘ItemName ‘: ‘Mouse ‘,
‘Quantity’: ‘20’}
In the above program, DictReader() is used to
read “sample8.csv” file and map into a dictionary. Then, the function dict() is
used to print the data in dictionary format without order.
Remove the dict() function from
the above program and use print(row).Check you are getting the following output
OrderedDict([(‘ItemName ‘,
‘Keyboard ‘), (‘Quantity’, ‘48’)])
OrderedDict([(‘ItemName ‘,
‘Monitor’), (‘Quantity’, ‘52’)])
OrderedDict([(‘ItemName ‘, ‘Mouse
‘), (‘Quantity’, ‘20’)])
7. Reading CSV File With User Defined Delimiter Into A Dictionary
You can also register new dialects and use it
in the DictReader() methods. Suppose “sample8.csv” is in the following format

Then “sample8.csv” can be read into a
dictionary by registering a new dialect
import csv
csv.register_dialect(‘myDialect’,delimiter
= ‘|’,skipinitialspace=True)
filename =
‘c:\\pyprg\\ch13\\sample8.csv’
with open(filename, ‘r’) as
csvfile:
reader = csv.DictReader(csvfile,
dialect=’myDialect’)
for row in reader:
print(dict(row))
csvfile.close()
OUTPUT
{‘ItemName ,Quantity’: ‘Keyboard
,48’}
{‘ItemName ,Quantity’:
‘Monitor,52’}
{‘ItemName ,Quantity’: ‘Mouse
,20’}
Related Topics