Chapter: Distributed Systems : Communication in Distributed System
TCP stream communication
TCP stream communication
The API
to the TCP protocol, which originates from BSD 4.x UNIX, provides the abstraction
of a stream of bytes to which data may be written and from which data may be
read. The following characteristics of the network are hidden by the stream
abstraction:
Message sizes: The application can choose how
much data it writes to a stream or reads from it. It may deal in very small or very large sets of data. The
underlying implementation of a TCP stream decides how much data to collect
before transmitting it as one or more IP packets. On arrival, the data is
handed to the application as requested. Applications can, if necessary, force
data to be sent immediately.
Lost messages: The TCP protocol uses an
acknowledgement scheme. As an example of a simple scheme (which is not used in TCP), the sending end keeps a record
of each IP packet sent and the receiving end acknowledges all the arrivals. If
the sender does not receive an acknowledgement within a timeout, it retransmits
the message. The more sophisticated sliding window scheme [Comer 2006] cuts
down on the number of acknowledgement messages required.
Flow control: The TCP protocol attempts to
match the speeds of the processes that read from and write to a stream. If the writer is too fast for the reader, then
it is blocked until the reader has consumed sufficient data.
Message duplication and ordering: Message
identifiers are associated with each IP packet, which enables the recipient to detect and reject duplicates, or to
reorder messages that do not arrive in sender order.
Message destinations: A pair
of communicating processes establish a connection before they can communicate over a stream. Once a
connection is established, the processes simply read from and write to the
stream without needing to use Internet addresses and ports. Establishing a
connection involves a connect request
from client to server followed by an accept
request from server to client before any communication can take place. This
could be a considerable overhead for a single client-server request and reply.
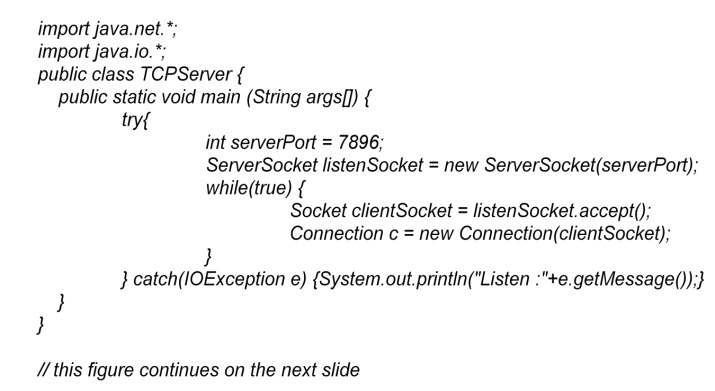
Java API for TCP streams • The Java
interface to TCP streams is provided in
the classes
ServerSocket and Socket:
ServerSocket: This class is intended for use
by a server to create a socket at a server port for listening for connect
requests from clients. Its accept
method gets a connect request from
the queue or, if the queue is empty, blocks until one arrives. The result of
executing accept is an instance of Socket – a socket to use for
communicating with the client.
Socket: This class is for use by a pair
of processes with a connection. The client uses a constructor to create a socket, specifying the DNS hostname and
port of a server. This constructor not only creates a socket associated with a
local port but also connects it to
the specified remote computer and port number. It can throw an UnknownHostException if the hostname is
wrong or an IOException if an IO
error occurs.
TCP client makes connection to server, sends request and receives reply

TCP
server makes a connection for each client and then echoes the client’s request

The
information stored in running programs is represented as data structures – for
example, by sets of interconnected objects – whereas the information in
messages consists of sequences of bytes. Irrespective of the form of
communication used, the data structures must be flattened (converted to a
sequence of bytes) before transmission and rebuilt on arrival. The individual
primitive data items transmitted in messages can be data values of many
different types, and not all computers store primitive values such as integers
in the same order. The representation of floating-point numbers also differs
between architectures. There are two variants for the ordering of integers: the
so-called big-endian order, in which
the most significant byte comes first; and little-endian
order, in which it comes last. Another issue is the set of codes used to
represent characters: for example,
the majority of applications on systems such as UNIX use ASCII character
coding, taking one byte per character, whereas the Unicode standard allows for
the representation of texts in many different languages and takes two bytes per
character.
One of
the following methods can be used to enable any two computers to exchange
binary data values:
The
values are converted to an agreed external format before transmission and
converted to the local form on receipt; if the two computers are known to be
the same type, the conversion to external format can be omitted.
The
values are transmitted in the sender’s format, together with an indication of
the format used, and the recipient converts the values if necessary. Note,
however, that bytes themselves are never altered during transmission. To
support RMI or RPC, any data type that can be passed as an argument or returned
as a result must be able to be flattened and the individual primitive data
values represented in an agreed format. An agreed standard for the
representation of data structures and primitive values is called an external data representation.
Marshalling is the process of taking a
collection of data items and assembling them into a form suitable for transmission in a message. Unmarshalling is the process of disassembling them on arrival to
produce an equivalent collection of data items at the destination. Thus
marshalling consists of the translation of structured data items and
primitive
values into an external data representation. Similarly, unmarshalling consists
of the generation of primitive values from their external data representation
and the rebuilding of the data structures.
Three
alternative approaches to external data representation and marshalling are
discussed:
CORBA’s
common data representation, which is concerned with an external representation
for the structured and primitive
types that can be passed as the arguments and results of remote method
invocations in CORBA. It can be used by a variety of programming languages.
Java’s
object serialization, which is concerned with the flattening and external data
representation of any single object or tree of objects that may need to be
transmitted in a message or stored on a disk. It is for use only by Java.
XML
(Extensible Markup Language), which defines a textual fomat for representing
structured data. It was originally intended for documents containing textual
self-describing structured data – for example documents accessible on the Web –
but it is now also used to represent the data sent in messages exchanged by
clients and servers in web services.
In the
first two cases, the marshalling and unmarshalling activities are intended to
be carried out by a middleware layer without any involvement on the part of the
application programmer. Even in the case of XML, which is textual and therefore
more accessible to hand-encoding, software for marshalling and unmarshalling is
available for all commonly used platforms and programming environments. Because
marshalling requires the consideration of all the finest details of the
representation of the primitive components of composite objects, the process is
likely to be error-prone if carried out by hand. Compactness is another issue
that can be addressed in the design of automatically generated marshalling
procedures.
In the
first two approaches, the primitive data types are marshalled into a binary
form. In the third approach (XML), the primitive data types are represented
textually. The textual representation of a data value will generally be longer
than the equivalent binary representation. The HTTP protocol, which is
described in Chapter 5, is another example of the textual approach.
Another
issue with regard to the design of marshalling methods is whether the
marshalled data should include information concerning the type of its contents.
For example, CORBA’s representation includes just the values of the objects
transmitted, and nothing about their types. On the other hand, both Java
serialization and XML do include type information, but in different ways. Java
puts all of the required type information into the serialized form, but XML
documents may refer to externally defined sets of names (with types) called namespaces.
Although
we are interested in the use of an external data representation for the
arguments and results of RMIs and RPCs, it does have a more general use for
representing data structures, objects or structured documents in a form suitable
for transmission in messages or storing in files.
Related Topics