Chapter: Distributed Systems : Communication in Distributed System
Performance of communication channels
Performance of
communication channels
Performance of communication channels • The communication channels in our model are realized in a variety
of ways in distributed systems – for example, by an implementation of streams
or by simple message passing over a computer network. Communication over a
computer network has the following performance characteristics relating to
latency, bandwidth and jitter:
The delay
between the start of a message’s transmission from one process and the
beginning of its receipt by another is referred to as latency. The latency includes:
The time
taken for the first of a string of bits transmitted through a network to reach
its destination. For example, the
latency for the transmission of a message through a satellite link is the time
for a radio signal to travel to the satellite and back.
The delay
in accessing the network, which increases significantly when the network is
heavily loaded. For example, for
Ethernet transmission the sending station waits for the network to be free of
traffic.
The time
taken by the operating system communication services at both the sending and
the receiving processes, which
varies according to the current load on the operating systems.
The bandwidth of a computer network is the
total amount of information that can be transmitted over it in a given time.
When a large number of communication channels are using the same network, they
have to share the available bandwidth.
Jitter is the variation in the time
taken to deliver a series of messages. Jitter is relevant to multimedia data. For example, if
consecutive samples of audio data are played with differing time intervals, the
sound will be badly distorted.
Computer clocks and timing events • Each computer in a distributed system has its own internal clock, which
can be used by local processes to obtain the value of the current time.
Therefore two processes running on different computers can each associate
timestamps with their events. However, even if the two processes read their
clocks at the same time, their local clocks may supply different time values.
This is because computer clocks drift from perfect time and, more importantly,
their drift rates differ from one another. The term clock drift rate refers to the rate at which a computer clock
deviates from a perfect reference clock. Even if the clocks on all the
computers in a distributed system are set to the same time initially, their
clocks will eventually vary quite significantly unless corrections are applied.
Two variants of the interaction model • In a distributed system it is hard to set limits on the time that can be
taken for process execution, message delivery or clock drift. Two opposing
extreme positions provide a pair of simple models – the first has a strong
assumption of time and the second makes no assumptions about time:
Synchronous distributed systems:
Hadzilacos and Toueg define a synchronous distributed system to be one in which the following bounds
are defined:
·
The time to execute each step of a process has
known lower and upper bounds.
·
Each message transmitted over a channel is received
within a known bounded time.
·
Each process has a local clock whose drift rate
from real time has a known bound.
Asynchronous distributed systems: Many
distributed systems, such as the Internet, are very useful without being able to qualify as synchronous systems.
Therefore we need an alternative model. An asynchronous distributed system is
one in which there are no bounds on:
·
Process execution speeds – for example, one process
step may take only a picosecond and another a century; all that can be said is
that each step may take an arbitrarily long time.
·
Message transmission delays – for example, one
message from process A to process B may be delivered in negligible time and
another may take several years. In other words, a message may be received after
an arbitrarily long time.
·
Clock drift rates – again, the drift rate of a
clock is arbitrary.
Event ordering • In many cases, we are interested in knowing whether an event
(sending or receiving a message) at one process
occurred before, after or concurrently with another event at another process.
The execution of a system can be described in terms of events and their
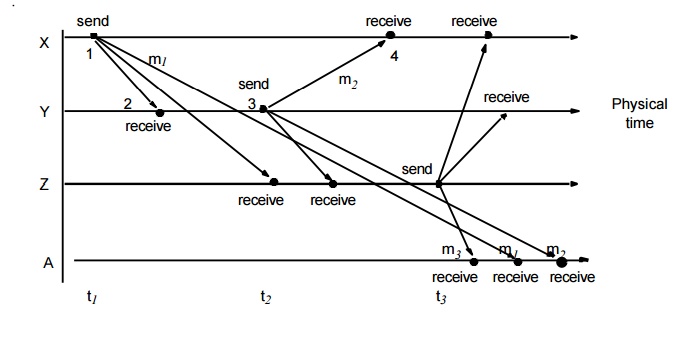
ordering despite the lack of accurate clocks. For example, consider the
following set of exchanges between a group of email users, X, Y, Z and A, on a
mailing list:
1. User X
sends a message with the subject Meeting.
2. Users Y
and Z reply by sending a message with the subject Re: Meeting.
In real
time, X’s message is sent first, and Y reads it and replies; Z then reads both
X’s message and Y’s reply and sends another reply, which references both X’s
and Y’s
messages.
But due to the independent delays in message delivery, the messages may be
delivered as shown in the following figure and some users may view these two
messages in the wrong order.
Failure model
In a
distributed system both processes and communication channels may fail – that
is, they may depart from what is considered to be correct or desirable
behaviour. The failure model defines the ways in which failure may occur in
order to provide an understanding of the effects of failures. Hadzilacos and
Toueg provide a taxonomy that distinguishes between the failures of processes
and communication channels. These are presented under the headings omission
failures, arbitrary failures and timing failures.
Omission failures • The faults classified as omission failures refer to cases when a process or communication channel
fails to perform actions that it is supposed to do.
Process omission failures: The chief omission
failure of a process is to crash. When, say that a process has crashed we mean that it has halted and will not
execute any further steps of its program ever. The design of services that can
survive in the presence of faults can be simplified if it can be assumed that
the services on which they depend crash cleanly – that is, their processes
either function correctly or else stop. Other processes may be able to detect
such a crash by
the fact that the process repeatedly fails to respond to invocation messages.
However, this method of crash detection relies on the use of timeouts – that is, a method in which
one process allows a fixed period of time for
something
to occur. In an asynchronous system a timeout can indicate only that a process
is not responding – it may have crashed or may be slow, or the messages may not
have arrived.
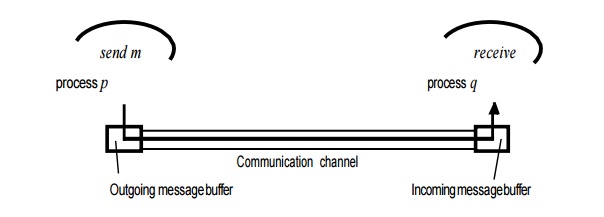
Communication omission failures: Consider the communication primitives send and receive. A process p performs a send by inserting the message m in its outgoing message buffer. The communication channel transports m to q’s incoming message buffer. Process q performs a receive by taking m from its incoming message buffer and delivering it. The outgoing and incoming message buffers are typically provided by the operating system.
Arbitrary failures • The term arbitrary or Byzantine failure is used to describe the worst possible failure
semantics, in which any type of error may occur. For example, a process may set
wrong values in its data items, or it may return a wrong value in response to
an invocation.
An
arbitrary failure of a process is one in which it arbitrarily omits intended
processing steps or takes unintended processing steps. Arbitrary failures in
processes cannot be detected by seeing whether the process responds to
invocations, because it might arbitrarily omit to reply.
Communication
channels can suffer from arbitrary failures; for example, message contents may
be corrupted, nonexistent messages may be delivered or real messages may be
delivered more than once. Arbitrary failures of communication channels are rare
because the communication software is able to recognize them and reject the
faulty
messages.
For example, checksums are used to detect corrupted messages, and message sequence
numbers can be used to detect nonexistent and duplicated messages.

Timing failures • Timing failures are applicable in synchronous distributed systems
where time limits are set on process execution time, message delivery time
and clock drift rate. Timing failures are listed in the following figure. Any
one of these failures may result in responses being unavailable to clients
within a specified time interval.
In an
asynchronous distributed system, an overloaded server may respond too slowly,
but we cannot say that it has a timing failure since no guarantee has been
offered. Real-time operating systems are designed with a view to providing
timing guarantees, but they are more complex to design and may require
redundant hardware.
Most
general-purpose operating systems such as UNIX do not have to meet real-time
constraints.
Masking failures • Each component in a distributed system is generally constructed
from a collection of other components. It is possible to construct reliable
services from components that exhibit failures. For example, multiple servers
that hold replicas of data can continue to provide a service when one of them
crashes. A knowledge of the failure characteristics of a component can enable a
new service to be designed to mask the failure of the components on which it
depends. A service masks a failure
either by hiding it altogether or by converting it into a more acceptable type
of failure. For an example of the latter, checksums are used to mask corrupted
messages, effectively converting an arbitrary failure into an omission failure.
The omission failures can be hidden by using a protocol that retransmits
messages that do not arrive at their destination. Even process crashes may be
masked, by replacing the process and restoring its memory from information
stored on disk by its predecessor.

Reliability of one-to-one communication
• Although a basic communication channel can exhibit the omission
failures described above, it is possible to use it to build a communication
service that masks some of those failures.
The term reliable communication is defined in
terms of validity and integrity as follows:
Validity: Any message in the outgoing
message buffer is eventually delivered to the incoming message buffer.
Integrity: The message received is
identical to one sent, and no messages are delivered twice.
The
threats to integrity come from two independent sources:
Any
protocol that retransmits messages but does not reject a message that arrives
twice. Protocols can attach sequence numbers to messages so as to detect those
that are delivered twice.
Malicious
users that may inject spurious messages, replay old messages or tamper with
messages. Security measures can be taken to maintain the integrity property in
the face of such attacks.
Related Topics