Chapter: Distributed Systems : Communication in Distributed System
System architectures
System architectures
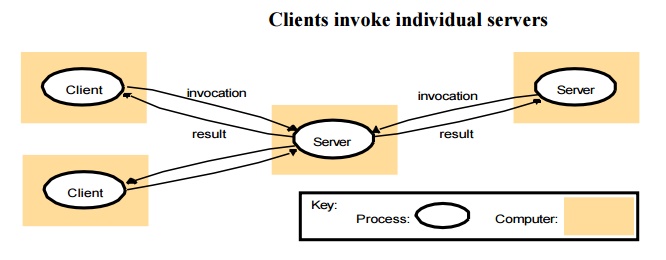
Client-server: This is the architecture that is most
often cited when distributed systems are discussed. It is historically the most important and remains the
most widely employed. Figure 2.3 illustrates the simple structure in which
processes take on the roles of being clients or servers. In particular, client
processes interact with individual server processes in potentially separate
host computers in order to access the shared resources that they manage.
Servers
may in turn be clients of other servers, as the figure indicates. For example,
a web server is often a client of a local file server that manages the files in
which the web pages are stored. Web servers and most other Internet services
are clients of the DNS service, which translates Internet domain names to
network addresses.
Another
web-related example concerns search
engines, which enable users to look up summaries of information available
on web pages at sites throughout the Internet. These summaries are made by
programs called web crawlers, which
run in the background at a search engine site using HTTP requests to access web
servers throughout the Internet. Thus a search engine is both a server and a
client: it responds to queries from browser clients and it runs web crawlers
that act as clients of other web servers. In this example, the server tasks
(responding to user queries) and the crawler tasks (making requests to other
web servers) are entirely independent; there is little need to synchronize them
and they may run concurrently. In fact, a typical search engine would normally
include many
concurrent
threads of execution, some serving its clients and others running web crawlers.
In Exercise 2.5, the reader is invited to consider the only synchronization
issue that does arise for a concurrent search engine of the type outlined here.
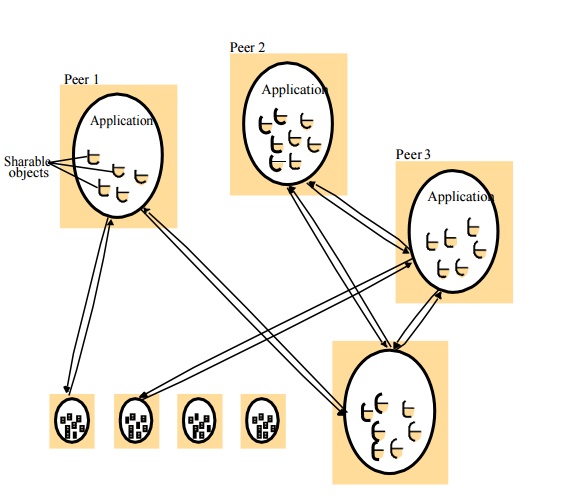
Peer-to-peer: In this architecture all of the
processes involved in a task or activity play similar roles, interacting cooperatively as peers without any distinction between client and server processes
or the computers on which they run. In practical terms, all participating
processes run the same program and offer the same set of interfaces to each
other.
While the client-server model offers a direct and relatively simple approach to
the sharing of data and other resources, it scales poorly.
A distributed application based on peer processes
A number
of placement strategies have evolved in response to this problem, but none of
them addresses the fundamental issue – the need to distribute shared resources
much more widely in order to share the computing and communication loads
incurred in accessing them amongst a much larger number of computers and
network links. The key insight that led to the development of peer-to-peer
systems is that the network and computing resources owned by the users of a
service could also be put to use to support that service. This has the useful
consequence that the resources available to run the service grow with the
number of users.
Models of
systems share some fundamental properties. In particular, all of them are
composed of processes that communicate with one another by sending messages
over a computer network. All of the models share the design requirements of
achieving the performance and reliability characteristics of processes and
networks and ensuring the security of the resources in the system.
About
their characteristics and the failures and security risks they might exhibit.
In general, such a fundamental model should contain only the essential
ingredients that need to consider in order to understand and reason about some
aspects of a system’s behaviour. The purpose of such a model is:
To make
explicit all the relevant assumptions about the systems we are modelling.
To make
generalizations concerning what is possible or impossible, given those
assumptions. The generalizations may take the form of general-purpose
algorithms or desirable properties that are guaranteed. The guarantees are
dependent
on logical analysis and, where appropriate, mathematical proof.
The
aspects of distributed systems that we wish to capture in our fundamental
models are intended to help us to discuss and reason about:
Interaction: Computation occurs within
processes; the processes interact by passing messages, resulting in communication (information flow) and coordination
(synchronization and ordering of activities) between processes. In the analysis
and design of distributed systems we are concerned especially with these
interactions. The interaction model must reflect the facts that communication
takes place with delays that are often of considerable duration, and that the
accuracy with which independent processes can be coordinated is limited by
these delays and by the difficulty of maintaining the same notion of time
across all the computers in a distributed system.
Failure: The correct operation of a
distributed system is threatened whenever a fault occurs in any of the computers on which it runs (including software faults)
or in the network that connects them. Our model defines and classifies the
faults. This provides a basis for the analysis of their potential effects and
for the design of systems that are able to tolerate faults of each type while
continuing to run correctly.
Security: The modular nature of
distributed systems and their openness exposes them to attack by both external and internal agents. Our
security model defines and classifies the forms that such attacks may take,
providing a basis for the analysis of threats to a system and for the design of
systems that are able to resist them.
Interaction model
Fundamentally
distributed systems are composed of many processes, interacting in complex
ways. For example:
·
Multiple server processes may cooperate with one
another to provide a service; the examples mentioned above were the Domain Name
System, which partitions and replicates its data at servers throughout the
Internet, and Sun’s Network Information Service, which keeps replicated copies
of password files at several servers in a local area network.
·
A set of peer processes may cooperate with one
another to achieve a common goal: for example, a voice conferencing system that
distributes streams of audio data in a similar manner, but with strict
real-time constraints.
Most
programmers will be familiar with the concept of an algorithm – a sequence of
steps to
be taken in order to perform a desired computation. Simple programs are
controlled by algorithms in which the steps are strictly sequential. The
behaviour of the program and the state of the program’s variables is determined
by them. Such a program is executed as a single process. Distributed systems
composed of multiple processes such as those outlined above are more complex.
Their behaviour and state can be described by a distributed algorithm – a definition of the steps to be taken by
each of the processes of which the system is composed, including the transmission of messages between them. Messages are
transmitted between processes to
transfer information between them and to coordinate their activity.
Two significant
factors affecting interacting processes in a distributed system:
·
Communication performance is often a limiting
characteristic.
·
It is impossible to maintain a single global notion
of time.
Related Topics