Chapter: Distributed Systems : Communication in Distributed System
Case Study: Java RMI
Case Study: Java RMI
Java Remote interfaces Shape and ShapeList and Java class ShapeListServant implements interface ShapeList
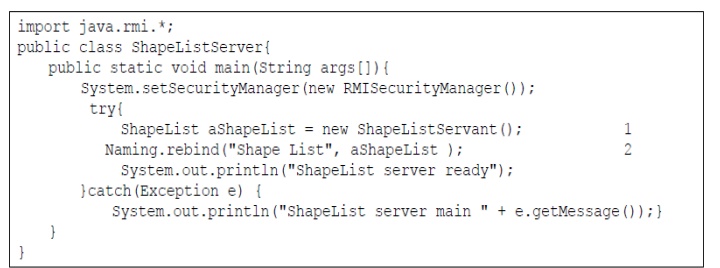
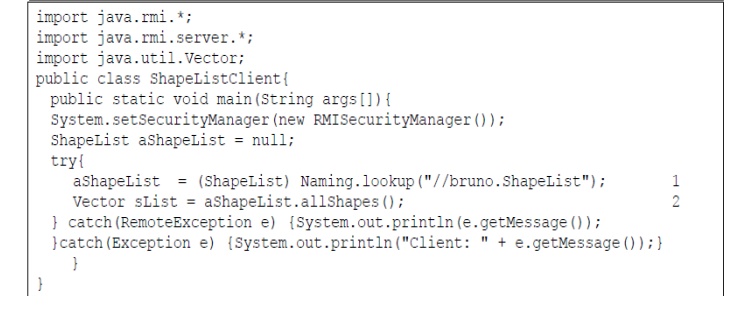
Java class ShapeListServer with main and Java client of ShapreList

Naming class of Java RMIregistry

Java class ShapeListServer with main method

Java class ShapeListServant implements interface ShapeList

Java class ShapeListServant implements interface ShapeList

Java RMI Callbacks
•Callbacks
server notifying the clients of events
why?
polling from clients increases overhead on server
not up-to-date for clients to inform users
how
remote object (callback object) on client for server to call
client tells the server about the callback object, server put the client on a list
server call methods on the callback object when events occur
client might forget to remove itself from the list
lease--client expire
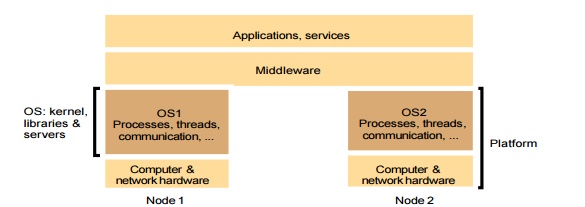
The task of any operating system is to provide problem-oriented abstractions of the underlying physical resources – the processors, memory, networks, and storage media. An operating system such as UNIX (and its variants, such as Linux and Mac OS X) or Windows (and its variants, such as XP, Vista and Windows 7) provides the programmer with, for example, files rather than disk blocks, and with sockets rather than raw network access. It takes over the physical resources on a single node and manages them to present these resource abstractions through the system-call interface.
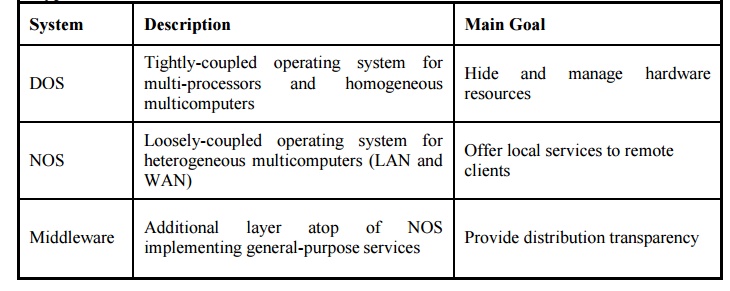
The operating system’s middleware support role, it is useful to gain some historical perspective by examining two operating system concepts that have come about during the development of distributed systems: network operating systems and distributed operating systems.
Both UNIX and Windows are examples of network operating systems. They have a networking capability built into them and so can be used to access remote resources. Access is network-transparent for some – not all – types of resource. For example, through a distributed file system such as NFS, users have network-transparent access to files. That is, many of the files that users access are stored remotely, on a server, and this is largely transparent to their applications.
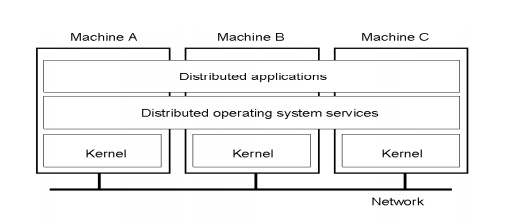
An operating system that produces a single system image like this for all the resources in a distributed system is called a distributed operating system
Middleware and the Operating System
What is a distributed OS?
– Presents users (and applications) with an integrated computing platform that hides the individual computers.
– Has control over all of the nodes (computers) in the network and allocates their resources to tasks without user involvement.
§ In a distributed OS, the user doesn't know (or care) where his programs are running.
– Examples:
§ Cluster computer systems
§ V system, Sprite
– In fact, there are no distributed operating systems in general use, only network operating systems such as UNIX, Mac OS and Windows.
– to remain the case, for two main reasons.
The first is that users have much invested in their application software, which often meets their current problem-solving needs; they will not adopt a new operating system that will not run their applications, whatever efficiency advantages it offers.
The second reason against the adoption of distributed operating systems is that users tend to prefer to have a degree of autonomy for their machines, even in a closely knit organization.
Combination of middleware and network OS
– No distributed OS in general use
o Users have much invested in their application software
o Users tend to prefer to have a degree of autonomy for their machines
– Network OS provides autonomy
– Middleware provides network-transparent access resource
The relationship between OS and Middleware
– Operating System
o Tasks: processing, storage and communication
o Components: kernel, library, user-level services
– Middleware
o runs on a variety of OS-hardware combinations
o remote invocations
Functions that OS should provide for middleware
The following figure shows how the operating system layer at each of two nodes supports a common middleware layer in providing a distributed infrastructure for applications and services.
Encapsulation: They should provide a useful service interface to their resources – that is, a set of operations that meet their clients’ needs. Details such as management of memory and devices used to implement resources should be hidden from clients.
Protection: Resources require protection from illegitimate accesses – for example, files are protected from being read by users without read permissions, and device registers are protected from application processes.
Concurrent processing: Clients may share resources and access them concurrently. Resource managers are responsible for achieving concurrency transparency.
Communication: Operation parameters and results have to be passed to and from resource managers, over a network or within a computer.
Scheduling: When an operation is invoked, its processing must be scheduled within the kernel or server.
The core OS components
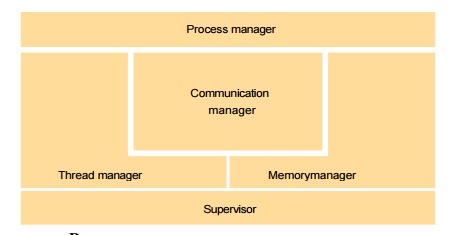
Process manager
Handles the creation of and operations upon processes.
Thread manager
Thread creation, synchronization and scheduling
Communication manager
Communication between threads attached to different processes on the same computer
Memory manager
Management of physical and virtual memory
Supervisor
Dispatching of interrupts, system call traps and other exceptions
control of memory management unit and hardware caches
processor and floating point unit register manipulations Software and hardware service layers in distributed systems

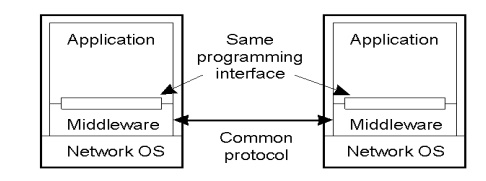
Middleware and Openness
In an open middleware-based distributed system, the protocols used by each middleware layer should be the same, as well as the interfaces they offer to applications.
Typical Middleware Services
· Communication
· Naming
· Persistence
· Distributed transactions
· Security
Middleware Models
· Distributed files
o Examples?
· Remote procedure call
o Examples?
· Distributed objects
o Examples?
· Distributed documents
o Examples?
· Others?
o Message-oriented middleware (MOM)
o Service oriented architecture (SOA)
o Document-oriented
Middleware and the Operating System
· Middleware implements abstractions that support network-wide programming. Examples:
§ RPC and RMI (Sun RPC, Corba, Java RMI)
§ event distribution and filtering (Corba Event Notification, Elvin)
§ resource discovery for mobile and ubiquitous computing
§ support for multimedia streaming
· Traditional OS's (e.g. early Unix, Windows 3.0)
o simplify, protect and optimize the use of local resources
· Network OS's (e.g. Mach, modern UNIX, Windows NT)
o do the same but they also support a wide range of communication standards and enable remote processes to access (some) local resources (e.g. files).
DOS vs. NOS vs. Middleware Discussion
· What is good/bad about DOS?
o Transparency
o Other issues have reduced success.
o Problems are often socio-technological.
· What is good/bad about NOS?
o Simple.
o Decoupled, easy to add/remove.
o Lack of transparency.
· What is good/bad about middleware?
o Easy to make multiplatform.
o Easy to start something new.
§ But this can also be bad.
Types of Distributed Oss
Illegitimate access
Maliciously contrived code
Benign code
· contains a bug
· have unanticipated behavior
Example: read and write in File System
o Illegal user vs. access right control
o Access the file pointer variable directly (setFilePointerRandomly) vs. type-safe language
§ Type–safe language, e.g. Java or Modula-3
§ Non-type-safe language, e.g. C or C++
Kernel and Protection
Kernel
o always runs
o complete access privileges for the physical resources
Different execution mode
o An address space: a collection of ranges of virtual memory locations, in each of which a specified combination of memory access rights applies, e.g.: read only or read-write
o supervisor mode (kernel process) / user mode (user process)
o Interface between kernel and user processes: system call trap
The price for protection
· switching between different processes take many processor cycles
· a system call trap is a more expensive operation than a simple method call
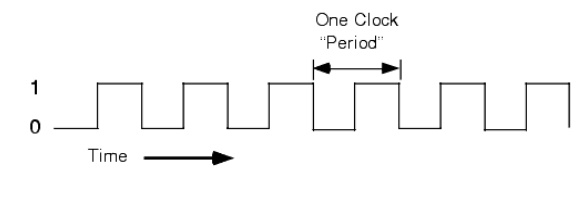
The System Clock

Process and thread
Process
o A program in execution
o Problem: sharing between related activities are awkward and expensive
o Nowadays, a process consists of an execution environment together with one or more threads
o an analogy at page 215
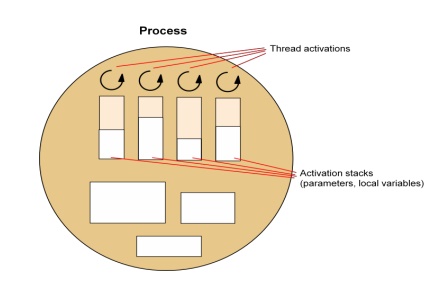
Thread
o Abstraction of a single activity
o Benefits
§ Responsiveness
§ Resource sharing
§ Economy
§ Utilization of MP architectures
Execution environment
· the unit of resource management
· Consist of
o An address space
o Thread synchronization and communication resources such as semaphores and communication interfaces (e.g. sockets)
o Higher-level resources such as open files and windows
· Shared by threads within a process
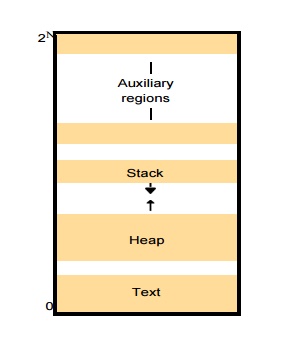
· Address space
Address space
o a unit of management of a process’s virtual memory
o Up to 232 bytes and sometimes up to 264 bytes
o consists of one or more regions
Region
· an area of continuous virtual memory that is accessible by the threads of the owning process
The number of regions is indefinite
– Support a separate stack for each thread
– access mapped file
– Share memory between processes
Region can be shared
– Libraries
– Kernel
– Shared data and communication
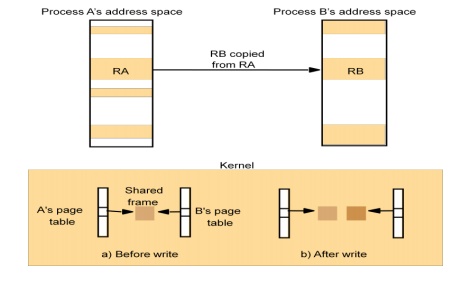
– Copy-on-write
Creation of new process in distributed system
Creating process by the operation system
Fork, exec in UNIX
Process creation in distributed system
– The choice of a target host
– The creation of an execution environment, an initial thread
Choice of process host
Choice of process host
o running new processes at their originator’s computer
o sharing processing load between a set of computers
Load sharing policy
o Transfer policy: situate a new process locally or remotely?
o Location policy: which node should host the new process?
§ Static policy without regard to the current state of the system
§ Adaptive policy applies heuristics to make their allocation decision
o Migration policy: when&where should migrate the running process?
Load sharing system
o Centralized
o Hierarchical
o Decentralized
– Creation of a new execution environment
– Initializing the address space
o Statically defined format
o With respect to an existing execution environment, e.g. fork
o Copy-on-write scheme
Threads concept and implementation
Client and server with threads
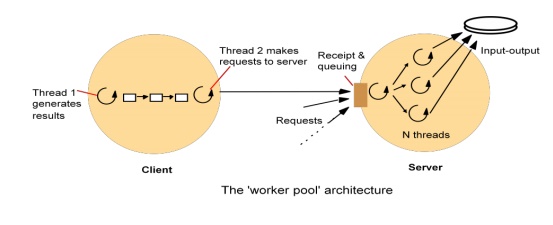
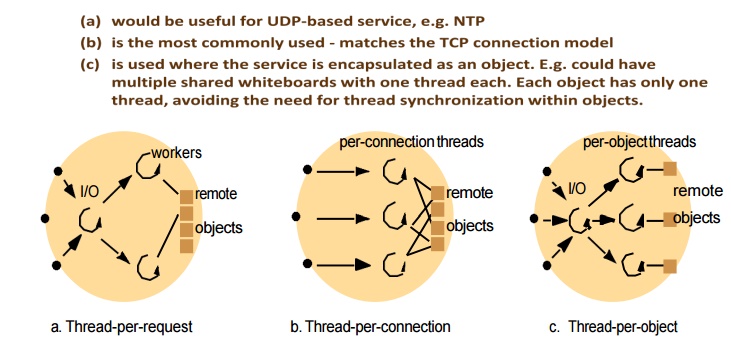
Alternative server threading architectures
Threads versus multiple processes
Creating a thread is (much) cheaper than a process (~10-20 times)
Switching to a different thread in same process is (much) cheaper (5-50 times)
Threads within same process can share data and other resources more conveniently and efficiently (without copying or messages)
Threads within a process are not protected from each other
State associated with execution environments and threads
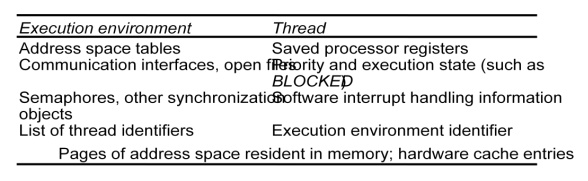
Threads implementation
– Threads can be implemented:
o in the OS kernel (Win NT, Solaris, Mach)
o at user level (e.g. by a thread library: C threads, pthreads), or in the language (Ada, Java).
– lightweight - no system calls
– modifiable scheduler
– low cost enables more threads to be employed
§ not pre-emptive
§ can exploit multiple processors
§ -page fault blocks all threads
o hybrid approaches can gain some advantages of both
§ user-level hints to kernel scheduler
§ hierarchic threads (Solaris 2)
§ event-based (SPIN, FastThreads)
Implementation of invocation mechanisms
Communication primitives
– TCP(UDP) Socket in Unix and Windows
– DoOperation, getRequest, sendReply in Amoeba
– Group communication primitives in V system
Protocols and openness
o provide standard protocols that enable internetworking between middleware
o integrate novel low-level protocols without upgrading their application
o Static stack
§ new layer to be integrated permanently as a ―driver‖
o Dynamic stack
§ protocol stack be composed on the fly
§ E.g. web browser utilize wide-area wireless link on the road and faster Ethernet connection in the office
Invocation costs
o Different invocations
o The factors that matter
§ synchronous/asynchronous, domain transition, communication across a network, thread scheduling and switching
Invocation over the network
o Delay: the total RPC call time experienced by a client
o Latency: the fixed overhead of an RPC, measured by null RPC
o Throughput: the rate of data transfer between computers in a single RPC
o An example
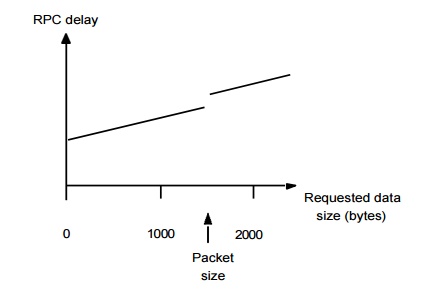
§ Threshold: one extra packet to be sent, might be an extra acknowledge packet is needed
Invocations between address spaces
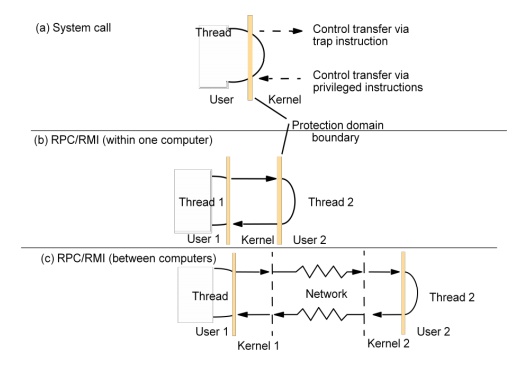
Support for communication and invocation
The performance of RPC and RMI mechanisms is critical for effective distributed systems.
o Typical times for 'null procedure call':
o –Local procedure call < 1 microseconds
o Remote procedure call ~ 10 milliseconds
o 'network time' (involving about 100 bytes transferred, at 100 megabits/sec.) accounts for only .01 millisecond; the remaining delays must be in OS and middleware - latency, not communication time.
– Factors affecting RPC/RMI performance
o marshalling/unmarshalling + operation despatch at the server
o data copying:- application -> kernel space -> communication buffers
o thread scheduling and context switching:- including kernel entry
o protocol processing:- for each protocol layer
o network access delays:- connection setup, network latency
Improve the performance of RPC
– Memory sharing
o rapid communication between processes in the same computer
– Choice of protocol
o TCP/UDP
§ E.g. Persistent connections: several invocations during one
o OS’s buffer collect several small messages and send them together
– Invocation within a computer
o Most cross-address-space invocation take place within a computer
o LRPC (lightweight RPC)
RPC delay against parameter size
A client stub marshals the call arguments into a message, sends the request message and receives and unmarshals the reply.
At the server, a worker thread receives the incoming request, or an I/O threadreceives the request and passes it to a worker thread; in either case, the worker calls the appropriate server stub.
The server stub unmarshals the request message, calls the designated procedure, and marshals and sends the reply.
The following are the main components accounting for remote invocation delay, besides network transmission times:
Marshalling: Marshalling and unmarshalling, which involve copying and converting data, create a significant overhead as the amount of data grows.
Data copying: Potentially, even after marshalling, message data is copied several times in the course of an RPC:
across the user–kernel boundary, between the client or server address space and kernel buffers;
across each protocol layer (for example, RPC/UDP/IP/Ethernet);
between the network interface and kernel buffers.
Transfers between the network interface and main memory are usually handled by direct memory access (DMA). The processor handles the other copies.
Packet initialization: This involves initializing protocol headers and trailers, including checksums. The cost is therefore proportional, in part, to the amount of data sent.
Thread scheduling and context switching: These may occur as follows:
Several system calls (that is, context switches) are made during an RPC, as stubs invoke the kernel’s communication operations.
One or more server threads is scheduled.
If the operating system employs a separate network manager process, then each
Send involves a context switch to one of its threads.
Waiting for acknowledgements: The choice of RPC protocol may influence delay, particularly when large amounts of data are sent.
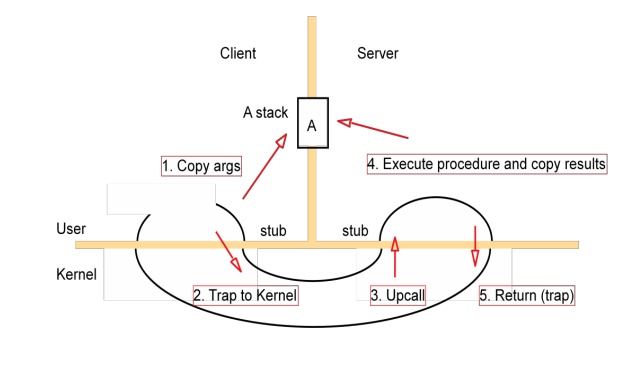
A lightweight remote procedure call
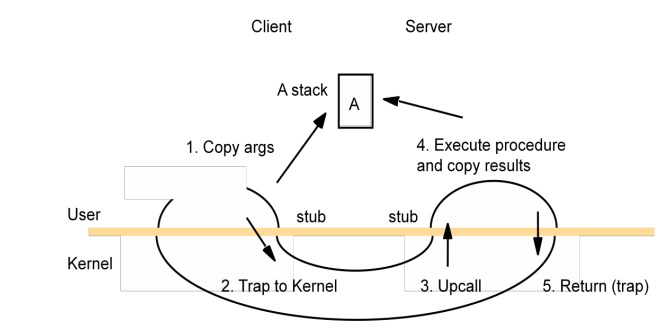
Bershad's LRPC
– Uses shared memory for interprocess communication
o while maintaining protection of the two processes
o arguments copied only once (versus four times for convenitional RPC)
– Client threads can execute server code
o via protected entry points only (uses capabilities)
– Up to 3 x faster for local invocations
Asynchronous operation
– Performance characteristics of the Internet
o High latencies, low bandwidths and high server loads
o Network disconnection and reconnection.
o outweigh any benefits that the OS can provide
– Asynchronous operation
o Concurrent invocations
§ E.g., the browser fetches multiple images in a home page by concurrent GET requests
o Asynchronous invocation: non-blocking call
§ E.g., CORBA oneway invocation: maybe semantics, or collect result by a separate call
– Persistent asynchronous invocations
o Designed for disconnected operation
o Try indefinitely to perform the invocation, until it is known to have succeeded or failed, or until the application cancels the invocation
o QRPC (Queued RPC)
§ Client queues outgoing invocation requests in a stable log
§ Server queues invocation results
– The issues to programmers
o How user can continue while the results of invocations are still not known?
The following figure shows the potential benefits of interleaving invocations (such as HTTP requests) between a client and a single server on a single-processor machine. In the serialized case, the client marshals the arguments, calls the Send operation and then waits until the reply from the server arrives – whereupon it Receives, unmarshals and then processes the results. After this it can make the second invocation.
Times for serialized and concurrent invocations
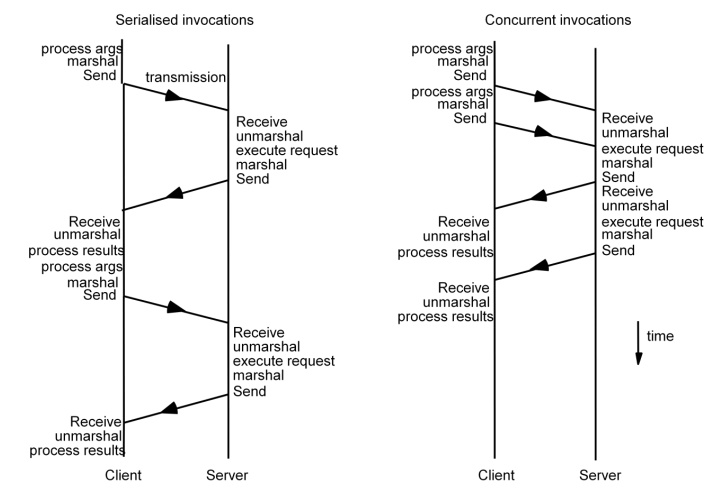
In the concurrent case, the first client thread marshals the arguments and calls the Send operation. The second thread then immediately makes the second invocation. Each thread waits to receive its results. The total time taken is liable to be lower than in the serialized case, as the figure shows. Similar benefits apply if the client threads make concurrent requests to several servers, and if the client executes on a multiprocessor even greater throughput is potentially possible, since the two threads’ processing can also be overlapped.
Operating System Architecture
– A key principle of distributed systems is openness.
– The major kernel architectures:
o Monolithic kernels
o Micro-kernels
– An open distributed system should make it possible to:
o Run only that system software at each computer that is necessary for its particular role in the system architecture. For example, system software needs for PDA and dedicated server are different. Loading redundant modules wastes memory resources.
o Allow the software (and the computer) implementing any particular service to be changed independent of other facilities.
o Allow for alternatives of the same service to be provided, when this is required to suit different users or applications.
o Introduce new services without harming the integrity of existing ones.
– A guiding principle of operating system design:
o The separation of fixed resource management ―mechanisms― from resource management ―policies‖, which vary from application to application and service to service.
o For example, an ideal scheduling system would provide mechanisms that enable a multimedia application such as videoconferencing to meet its real-time demands The kernel would provide only the most basic mechanisms upon which the general resource management tasks at a node are carried out.
o Server modules would be dynamically loaded as required, to implement the required resourced management policies for the currently running applications.
o while coexisting with a non-real-time application such as web browsing.
– Monolithic Kernels
o A monolithic kernel can contain some server processes that execute within its address space, including file servers and some networking.
o The code that these processes execute is part or the standard kernel configuration.
Monolithic kernel and microkernel
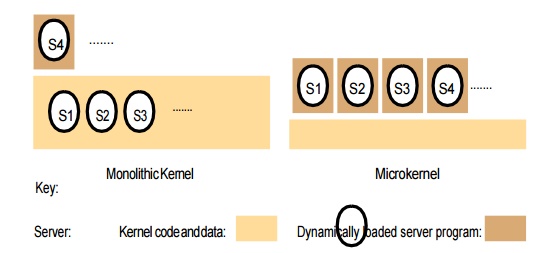
Microkernel
The microkernel appears as a layer between hardware layer and a layer consisting of major systems.
If performance is the goal, rather than portability, then middleware may use the facilities of the microkernel directly.
The role of the microkernel
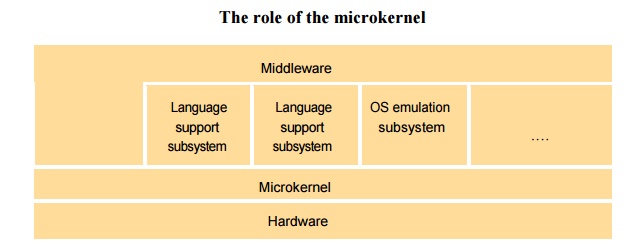
§ The microkernel supports middleware via subsystems
– Monolithic and Microkernel comparison
o The advantages of a microkernel
§ Its extensibility
§ Its ability to enforce modularity behind memory protection boundaries.
§ Its small kernel has less complexity.
o The advantages of a monolithic
§ The relative efficiency with which operations can be invoked because even invocation to a separate user-level address space on the same node is more costly.
– Hybrid Approaches
o Pure microkernel operating system such as Chorus & Mach have changed over a time to allow servers to be loaded dynamically into the kernel address space or into a user-level address space.
o In some operating system such as SPIN, the kernel and all dynamically loaded modules grafted onto the kernel execute within a single address space
Related Topics