Chapter: Biochemistry: Protein Purification and Characterization Techniques
Sequencing of Peptides: The Edman Method
Sequencing of Peptides: The Edman
Method
The actual sequencing of each peptide produced by specific cleavage of a protein is accomplished by repeated application of the Edman degradation.
The sequence of a peptide containing 10 to 40 residues can be determined by this method in about 30 minutes using as little as 10 picomoles of material, with the range being based on the amount of purified fragment and the complexity of the sequence.
For example, proline is more difficult to sequence than
serine because of its chemical reactivity. (The amino acid sequences of the
individual peptides in Figure 5.19 are determined by the Edman method after the
peptides are separated from one another.) The overlapping sequences of peptides
produced by different reagents provide the key to solving the puzzle. The
alignment of like sequences on different peptides makes deducing the overall
sequence possible. The Edman method has become so efficient that it is no
longer considered necessary to identify the N-terminal and C-terminal ends of a
protein by chemical or enzymatic methods. While interpreting results, however,
it is necessary to keep in mind that a protein may consist of more than one
polypeptide chain.

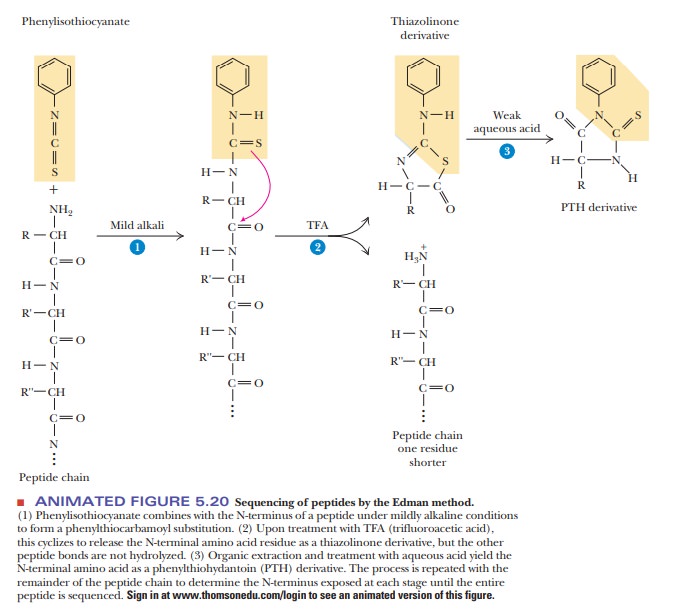
In the
sequencing of a peptide, the Edman reagent, phenyl
isothiocyanate, reacts with the peptide’s N-terminal residue. The modified
amino acid can be cleaved off, leaving
the rest of the peptide intact, and can be detected as the
phen-ylthiohydantoin derivative of the amino acid. The second amino acid of the
original peptide can then be treated in the same way, as can the third. With an
automated instrument called a sequencer
(Figure 5.20), the process is repeated until the whole peptide is sequenced.
Another sequencing method uses the fact that the amino acid sequence of a protein reflects the base sequence of the DNA in the gene that coded for that protein. Using currently available methods, it is sometimes easier to obtain the sequence of the DNA than that of the protein. Using the genetic code, one can immediately determine the amino acid sequence of the protein. Convenient though this method may be, it does not determine the positions of disulfide bonds or detect amino acids, such as hydroxyproline, that are modi-fied after translation, nor does it take into account the extensive processing that occurs with eukaryotic genomes before the final protein is synthesized.
To
finish this section, let’s go back to why we needed to cut the protein into
pieces. Because the amino acid analyzer is giving us the sequence, it is easy
to think that we could analyze a 100-amino-acid protein in one step with the
ana-lyzer and get the sequence without having to digest the protein with
trypsin, chymotrypsin, or other chemicals. However, we must consider the logistical
reality of doing the Edman degradation. As shown in step 1 of Figure 5.20, we
react the peptide with the Edman reagent, phenylisothiocyanate (PITC). The
stoichiometry of this reaction is that one molecule of the peptide reacts with
one molecule of PITC. This yields one molecule of the PTH derivative in step 3
that is then analyzed. Unfortunately, it is very difficult to get an exact
stoichiometric match. For example, let’s say we are analyzing a peptide with
the sequence Asp-Leu-Tyr, etc. For simplicity, assume we add 100 molecules of
the peptide to 98 molecules of the PITC because we cannot measure the
quantities perfectly accurately. What happens then? In step 1, the PITC is
limiting, so we eventually end up with 98 PTH derivatives of aspartate, which
are analyzed correctly and we know the N-terminus is aspartate. In the second
round of the reaction, we add more PITC, but now there are two peptides; 98 of
them begin with leucine and 2 of them begin with aspartate. When we analyze the
PTH derivatives of round 2, we get two signals, one saying the derivative is
leucine and the other saying aspartate. In round 2, the small amount of PTH
derivative of aspartate does not interfere with our ability to recognize the
true second amino acid. However, with every round, this situation gets worse
and worse as more of the by-products show up. At some point, we get an analysis
of the PTH derivatives that cannot be identified. For this reason, we have to
start with smaller fragments so that we can analyze their sequences before the
signal degrades.
Related Topics