Chapter: Security in Computing : Database and Data Mining Security
Sensitive Data
Sensitive Data
Some databases contain what is called sensitive
data. As a working definition, let us say that sensitive data are data that should not be made public. Determining
which data items and fields are sensitive depends both on the individual
database and the underlying meaning of the data. Obviously, some databases,
such as a public library catalog, contain no sensitive data; other databases,
such as defense-related ones, are totally sensitive. These two casesnothing
sensitive and everything sensitiveare the easiest to handle because they can be
covered by access controls to the database as a whole. Someone either is or is
not an authorized user. These controls are provided by the operating system.
The more difficult problem, which is also the more interesting one,
is the case in which some but not all of the elements in the database are
sensitive. There may be varying degrees of sensitivity. For example, a
university database might contain student data consisting of name, financial
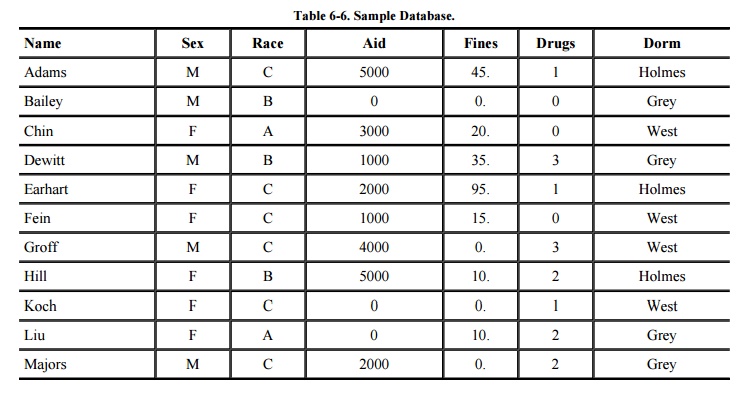
aid, dorm, drug use, sex, parking fines, and race. An example of this database is
shown in Table 6 -6. Name and dorm are
probably the least sensitive; financial aid, parking fines, and drug use the
most; sex and race somewhere in between. That is, many people may have
legitimate access to name, some to sex and race, and relatively few to
financial aid, parking fines, or drug use. Indeed, knowledge of the existence
of some fields, such as drug use, may itself be sensitive. Thus, security
concerns not only the data elements but also their context and meaning.
Furthermore, we must take into account
different degrees of sensitivity. For instance, although they are all highly
sensitive, the financial aid, parking fines, and drug-use fields may not have
the same kinds of access restrictions. Our security requirements may demand
that a few people be authorized to see each field, but no one be authorized to
see all three. The challenge of the access control problem is to limit users'
access so that they can obtain only the data to which they have legitimate
access. Alternatively, the access control problem forces us to ensure that
sensitive data are not to be released to unauthorized people.
Several factors can make data sensitive.
· Inherently sensitive. The value itself may be
so revealing that it is sensitive. Examples are the locations of defensive
missiles or the median income of barbers in a town with only one barber.
· From a sensitive source. The source of the data
may indicate a need for confidentiality. An example is information from an
informer whose identity would be compromised if the information were disclosed.
· Declared sensitive. The database administrator
or the owner of the data may have declared the data to be sensitive. Examples
are classified military data or the name of the anonymous donor of a piece of
art.
· Part of a sensitive attribute or a sensitive
record. In a database, an entire attribute or record may be classified as
sensitive. Examples are the salary attribute of a personnel database or a
record describing a secret space mission.
· Sensitive in relation to previously disclosed
information. Some data become sensitive in the presence of other data. For
example, the longitude coordinate of a secret gold mine reveals little, but the
longitude coordinate in conjunction with the latitude coordinate pinpoints the
mine.
All of these factors must be considered to determine the
sensitivity of the data.
Access Decisions
Remember that a database
administrator is a person who decides what data should be in the database and
who should have access to it. The database administrator considers the need for
different users to know certain information and decides who should have what
access. Decisions of the database administrator are based on an access policy.
The database manager or DBMS
is a program that operates on the database and auxiliary control information to
implement the decisions of the access policy. We say that the database manager
decides to permit user x to access data y. Clearly, a program or machine cannot
decide anything; it is more precise to say that the program performs the
instructions by which x accesses y as a way of implementing the policy
established by the database administrator. (Now you see why we use the simpler
wording.) To keep explanations concise, we occasionally describe programs as if
they can carry out human thought processes.
The DBMS may consider several
factors when deciding whether to permit an access. These factors include
availability of the data, acceptability of the access, and authenticity of the
user. We expand on these three factors below.
Availability of Data
One or more required elements
may be inaccessible. For example, if a user is updating several fields, other
users' accesses to those fields must be blocked temporarily. This blocking
ensures that users do not receive inaccurate information, such as a new street
address with an old city and state, or a new code component with old
documentation. Blocking is usually temporary. When performing an update, a user
may have to block access to several fields or several records to ensure the
consistency of data for others.
Notice, however, that if the updating user
aborts the transaction while the update is in progress, the other users may be
permanently blocked from accessing the record. This indefinite postponement is also
a security problem, resulting in denial of service.
Acceptability of Access
One or more values of the record may be
sensitive and not accessible by the general user. A DBMS should not release
sensitive data to unauthorized individuals.
Deciding what is sensitive, however, is not as
simple as it sounds, because the fields may not be directly requested. A user
may have asked for certain records that contain sensitive data, but the user's
purpose may have been only to project the values from particular fields that
are not sensitive. For example, a user of the database shown in Table 6-6 may request the NAME and DORM of any
student for whom FINES is not 0. The exact value of the sensitive field FINES
is not disclosed, although "not 0" is a partial disclosure. Even when
a sensitive value is not explicitly given, the database manager may deny access
on the grounds that it reveals information the user is not authorized to have.
Alternatively, the user may want to derive a
nonsensitive statistic from the sensitive data; for example, if the average
financial aid value does not reveal any individual's financial aid value, the
database management system can safely return the average. However, the average
of one data value discloses that value.
Assurance of Authenticity
Certain characteristics of
the user external to the database may also be considered when permitting
access. For example, to enhance security, the database administrator may permit
someone to access the database only at certain times, such as during working
hours. Previous user requests may also be taken into account; repeated requests
for the same data or requests that exhaust a certain category of information
may be used to find out all elements in a set when a direct query is not
allowed. As we shall see, sensitive data can sometimes be revealed by combined
results from several less sensitive queries.
Types of Disclosures
Data can be sensitive, but so
can their characteristics. In this section, we see that even descriptive
information about data (such as their existence or whether they have an element
that is zero) is a form of disclosure.
Exact Data
The most serious disclosure
is the exact value of a sensitive data item itself. The user may know that
sensitive data are being requested, or the user may request general data
without knowing that some of it is sensitive. A faulty database manager may
even deliver sensitive data by accident, without the user's having requested
it. In all of these cases the result is the same: The security of the sensitive
data has been breached.
Bounds
Another exposure is disclosing bounds on a sensitive value; that is, indicating that a sensitive value, y, is between two values, L and H. Sometimes, by using a narrowing technique not unlike the binary search, the user may first determine that L y H and then see whether L y H/2, and so forth, thereby permitting the user to determine y to any desired precision. In another case, merelyrevealing that a value such as the athletic scholarship budget or the number of CIA agents exceeds a certain amount may be a serious breach of security.
Sometimes, however, bounds
are a useful way to present sensitive data. It is common to release upper and
lower bounds for data without identifying the specific records. For example, a
company may announce that its salaries for programmers range from $50,000 to
$82,000. If you are a programmer earning $79,700, you can presume that you are
fairly well off, so you have the information you want; however, the
announcement does not disclose who are the highest- and lowest-paid
programmers.
Negative Result
Sometimes we can word a query
to determine a negative result. That is, we can learn that z is not the value
of y. For example, knowing that 0 is not the total number of felony convictions
for a person reveals that the person was convicted of a felony. The distinction
between 1 and 2 or 46 and 47 felonies is not as sensitive as the distinction
between 0 and 1. Therefore, disclosing that a value is not 0 can be a
significant disclosure. Similarly, if a student does not appear on the honors
list, you can infer that the person's grade point average is below 3.50. This
information is not too revealing, however, because the range of grade point
averages from 0.0 to 3.49 is rather wide.
Existence
In some cases, the existence
of data is itself a sensitive piece of data, regardless of the actual value.
For example, an employer may not want employees to know that their use of long
distance telephone lines is being monitored. In this case, discovering a LONG DISTANCE
field in a personnel file would reveal sensitive data.
Probable Value
Finally, it may be possible
to determine the probability that a certain element has a certain value. To see
how, suppose you want to find out whether the president of the United States is
registered in the Tory party. Knowing that the president is in the database,
you submit two queries to the database:
·
How many people have 1600 Pennsylvania Avenue as their official
residence? (Response: 4)
·
How many people have 1600 Pennsylvania Avenue as their official
residence and have YES as the value of TORY? (Response: 1)
From these queries you
conclude there is a 25 percent likelihood that the president is a registered
Tory.
Summary of Partial Disclosure
We have seen several examples
of how a security problem can result if characteristics of sensitive data are
revealed. Notice that some of the techniques we presented used information
about the data, rather than direct access to the data, to infer sensitive
results. A successful security strategy must protect from both direct and
indirect disclosure.
Security versus Precision
Our examples have illustrated
how difficult it is to determine which data are sensitive and how to protect
them. The situation is complicated by a desire to share nonsensitive data. For
reasons of confidentiality we want to disclose only those data that are not
sensitive. Such an outlook encourages a conservative philosophy in determining
what data to disclose: less is better than more.
On the other hand, consider
the users of the data. The conservative philosophy suggests rejecting any query
that mentions a sensitive field. We may thereby reject many reasonable and
nondisclosing queries. For example, a researcher may want a list of grades for
all students using drugs, or a statistician may request lists of salaries for
all men and for all women. These queries probably do not compromise the
identity of any individual. We want to disclose as much data as possible so
that users of the database have access to the data they need. This goal, called
precision, aims to protect all
sensitive data while revealing as much nonsensitive data as possible.
We can depict the relationship between security
and precision with concentric circles. As Figure
6-3 shows, the sensitive data in the central circle should be
carefully concealed. The outside band represents data we willingly disclose in
response to queries. But we know that the user may put together pieces of
disclosed data and infer other, more deeply hidden, data. The figure shows us
that beneath the outer layer may be yet more nonsensitive data that the user
cannot infer.
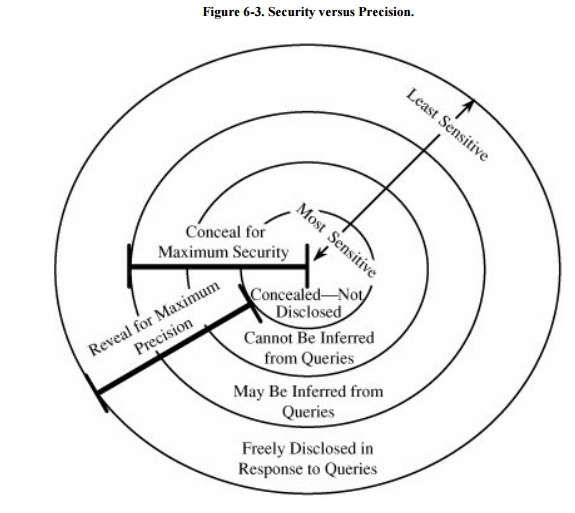
The ideal combination of security and precision
allows us to maintain perfect confidentiality with maximum precision; in other
words, we disclose all and only the nonsensitive data. But achieving this goal
is not as easy as it might seem, as we show in the next section. Sidebar 6-3 gives an example of using
imprecise techniques to improve accuracy. In the next section, we consider ways
in which sensitive data can be obtained from queries that appear harmless.
Sidebar
6-3: Accuracy and Imprecision
Article I of the U.S. Constitution
charges Congress with determining the "respective numbers… of free…and all
other persons…within every…term of ten years." This count is used for many
things, including apportioning the number of representatives to Congress and
distributing funds fairly to the states. Although difficult in 1787, this task
has become increasingly challenging. The count cannot simply be based on
residences, because some homeless people would be missed. A fair count cannot
be obtained solely by sending a questionnaire for each person to complete and
return, because some people cannot read and, more significantly, many people do
not return such forms. And there is always the possibility that a form would be
lost in the mail.
For the 2000 census the U.S. Census
Bureau proposed using statistical sampling and estimating techniques to
approximate the population. With these techniques they would select certain
areas in which to take two counts: a regular count and a second, especially
diligent search for every person residing in the area. In this way the bureau
could determine the "undercount," the number of people missed in the
regular count. They could then use this undercount factor to adjust the regular
count in other similar areas and thus obtain a more accurate, although less
precise, count.
The Supreme Court ruled that statistical
sampling techniques were acceptable for determining revenue distribution to the
states but not for allocating representatives in Congress. As a result, the
census can never get an exact, accurate count of the number of people in the
United States or even in a major U.S. city. At the same time, concerns about
precision and privacy prevent the Census Bureau from releasing information
about any particular individual living in the United States.
Does this
lack of accuracy and exactness mean that the census is not useful? No. We may
not know exactly how many people live in Washington, D.C., or the exact
information about a particular resident of Washington, D.C., but we can use the
census information to characterize the residents of Washington, D.C. For
example, we can determine the maximum, minimum, mean, and median ages or
incomes, and we can investigate the relationships among characteristics, such
as between education level and income. So
accuracy and precision help to reflect the balance between protection and need
to know.
Related Topics