Chapter: Security in Computing : Database and Data Mining Security
Proposals for Multilevel Security
Proposals for Multilevel Security
As you can already tell,
implementing multilevel security for databases is difficult, probably more so
than in operating systems, because of the small granularity of the items being
controlled. In the remainder of this section, we study approaches to multilevel
security for databases.
Separation
As we have already seen,
separation is necessary to limit access. In this section, we study mechanisms
to implement separation in databases. Then, we see how these mechanisms can
help to implement multilevel security for databases.
Partitioning
The obvious control for
multilevel databases is partitioning. The database is divided into separate
databases, each at its own level of sensitivity. This approach is similar to
maintaining separate files in separate file cabinets.
This control destroys a basic
advantage of databases: elimination of redundancy and improved accuracy through
having only one field to update. Furthermore, it does not address the problem
of a high-level user who needs access to some low-level data combined with
high-level data.
Nevertheless, because of the
difficulty of establishing, maintaining, and using multilevel databases, many
users with data of mixed sensitivities handle their data by using separate,
isolated databases.
Encryption
If sensitive data are
encrypted, a user who accidentally receives them cannot interpret the data.
Thus, each level of sensitive data can be stored in a table encrypted under a
key unique to the level of sensitivity. But encryption has certain
disadvantages.
First, a user can mount a chosen plaintext
attack. Suppose party affiliation of REP or DEM is stored in encrypted form in
each record. A user who achieves access to these encrypted fields can easily
decrypt them by creating a new record with party=DEM and comparing the
resulting encrypted version to that element in all other records. Worse, if
authentication data are encrypted, the malicious user can substitute the
encrypted form of his or her own data for that of any other user. Not only does
this provide access for the malicious user, but it also excludes the legitimate
user whose authentication data have been changed to that of the malicious user.
These possibilities are shown in Figures 6-5
and 6-6.
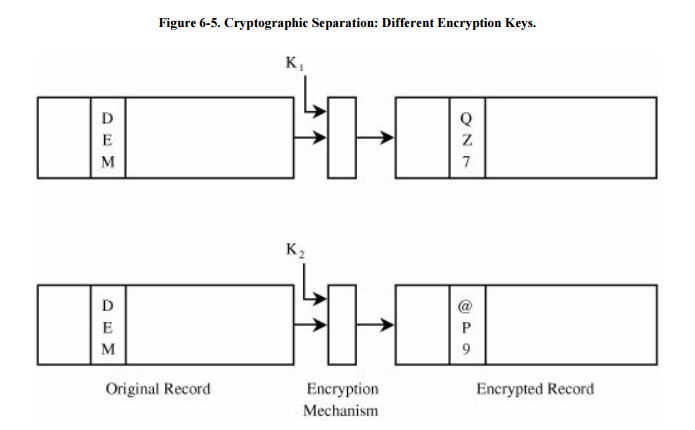
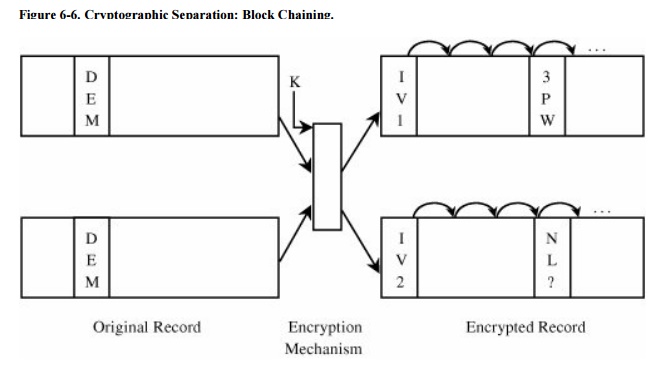
Using a different encryption
key for each record overcomes these defects. Each record's fields can be
encrypted with a different key, or all fields of a record can be
cryptographically linked, as with cipher block chaining.
The disadvantage, then, is
that each field must be decrypted when users perform standard database
operations such as "select all records with SALARY > 10,000."
Decrypting the SALARY field, even on rejected records, increases the time to
process a query. (Consider the query that selects just one record but that must
decrypt and compare one field of each record to find the one that satisfies the
query.) Thus, encryption is not often used to implement separation in
databases.
Integrity Lock
The integrity lock was first proposed at the U.S. Air Force Summer
Study on Data Base Security [AFS83]. The
lock is a way to provide both integrity and limited access for a database. The
operation was nicknamed "spray paint" because each element is
figuratively painted with a color that denotes its sensitivity. The coloring is
maintained with the element, not in a master database table.
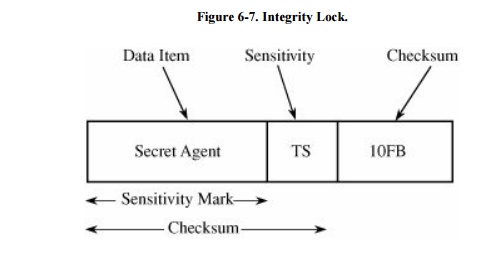
A model of the basic integrity lock is shown in
Figure 6-7. As illustrated, each
apparent data item consists of three pieces: the actual data item itself, a
sensitivity label, and a checksum. The sensitivity label defines the
sensitivity of the data, and the checksum is computed across both data and
sensitivity label to prevent unauthorized modification of the data item or its
label. The actual data item is stored in plaintext, for efficiency because the
DBMS may need to examine many fields when selecting records to match a query.
The sensitivity label should
be
unforgeable, so that a
malicious subject cannot create a new sensitivity level for an element
unique, so that a malicious
subject cannot copy a sensitivity level from another element
concealed, so that a malicious subject cannot
even determine the sensitivity level of an arbitrary element
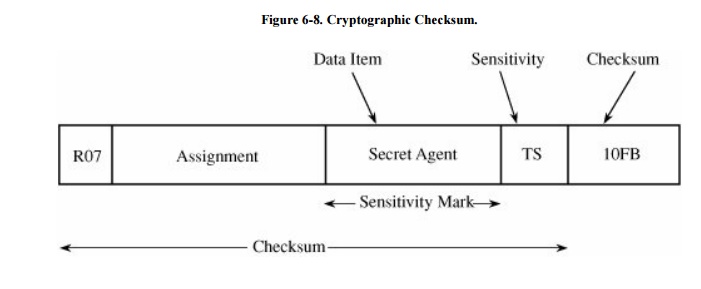
The third piece of the integrity lock for a
field is an error-detecting code, called a cryptographic checksum. To guarantee
that a data value or its sensitivity classification has not been changed, this
checksum must be unique for a given element, and must contain both the
element's data value and something to tie that value to a particular position
in the database. As shown in Figure 6-8,
an appropriate cryptographic checksum includes something unique to the record
(the record number), something unique to this data field within the record (the
field attribute name), the value of this element, and the sensitivity
classification of the element. These four components guard against anyone's
changing, copying, or moving the data. The checksum can be computed with a strong
encryption algorithm or hash function.
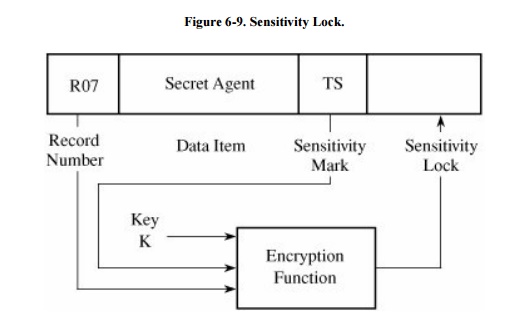
Sensitivity Lock
The sensitivity lock shown in Figure 6-9 was designed by Graubert and Kramer [GRA84b] to meet these principles. A sensitivity lock is a combination of a
unique identifier (such as the record number) and the sensitivity level.
Because the identifier is unique, each lock relates to one particular record.
Many different elements will have the same sensitivity level. A malicious
subject should not be able to identify two elements having identical
sensitivity levels or identical data values just by looking at the sensitivity
level portion of the lock. Because of the encryption, the lock's contents,
especially the sensitivity level, are concealed from plain view. Thus, the lock
is associated with one specific record, and it protects the secrecy of the
sensitivity level of that record.
Designs of Multilevel Secure Databases
This section covers different
designs for multilevel secure databases. These designs show the tradeoffs among
efficiency, flexibility, simplicity, and trustworthiness.
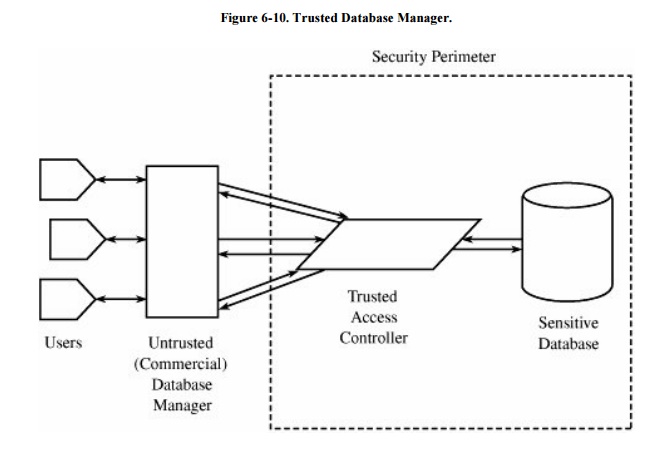
Integrity Lock
The integrity lock DBMS was invented as a
short- term solution to the security problem for multilevel databases. The
intention was to be able to use any (untrusted) database manager with a trusted
procedure that handles access control. The sensitive data were obliterated or
concealed with encryption that protected both a data item and its sensitivity.
In this way, only the access procedure would need to be trusted because only it
would be able to achieve or grant access to sensitive data. The structure of
such a system is shown in Figure 6-10.
The efficiency of integrity
locks is a serious drawback. The space needed for storing an element must be
expanded to contain the sensitivity label. Because there are several pieces in
the label and one label for every element, the space required is significant.
Problematic, too, is the
processing time efficiency of an integrity lock. The sensitivity label must be
decoded every time a data element is passed to the user to verify that the
user's access is allowable. Also, each time a value is written or modified, the
label must be recomputed. Thus, substantial processing time is consumed. If the
database file can be sufficiently protected, the data values of the individual
elements can be left in plaintext. That approach benefits select and project
queries across sensitive fields because an element need not be decrypted just
to determine whether it should be selected.
A final difficulty with this
approach is that the untrusted database manager sees all data, so it is subject
to Trojan horse attacks by which data can be leaked through covert channels.
Trusted Front End
The model of a trusted front -end process is shown in Figure
6-11. A trusted front end is also known as a guard and operates much
like the reference monitor of Chapter 5.
This approach, originated by Hinke and Schaefer [HIN75],
recognizes that many DBMSs have been built and put into use without
consideration of multilevel security. Staff members are already trained in
using these DBMSs, and they may in fact use them frequently. The front-end
concept takes advantage of existing tools and expertise, enhancing the security
of these existing systems with minimal change to the system. The interaction
between a user, a trusted front end, and a DBMS involves the following steps.
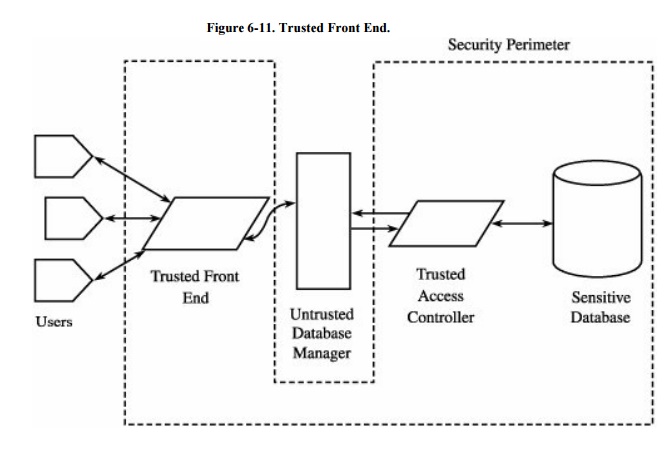
A user identifies himself or herself to the front end; the front
end authenticates the user's identity.
The user issues a query to the front end.
The front end verifies the user's authorization to data.
The front end issues a query to the database manager.
·
The database manager performs I/O access, interacting with
low-level access control to achieve access to actual data.
·
The database manager returns the result of the query to the trusted
front end.
·
The front end analyzes the sensitivity levels of the data items in
the result and selects those items consistent with the user's security level.
·
The front end transmits selected data to the untrusted front end
for formatting.
·
The untrusted front end transmits formatted data to the user.
The trusted front end serves
as a one-way filter, screening out results the user should not be able to
access. But the scheme is inefficient because potentially much data is
retrieved and then discarded as inappropriate for the user.
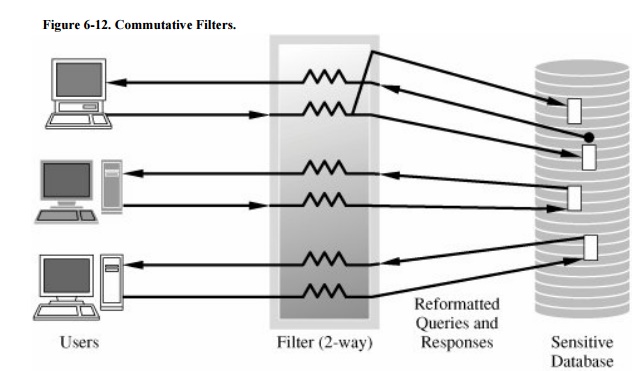
Commutative Filters
The notion of a commutative
filter was proposed by Denning [DEN85]
as a simplification of the trusted interface to the DBMS. Essentially, the
filter screens the user's request, reformatting it if necessary, so that only
data of an appropriate sensitivity level are returned to the user.
A commutative filter is a process that forms an interface between the
user and a DBMS. However, unlike the trusted front end, the filter tries to
capitalize on the efficiency of most DBMSs. The filter reformats the query so
that the database manager does as much of the work as possible, screening out
many unacceptable records. The filter then provides a second screening to
select only data to which the user has access.
Filters can be used for
security at the record, attribute, or element level.
z When used at the record level, the filter requests desired data
plus cryptographic checksum information; it then verifies the accuracy and
accessibility of data to be passed to the user.
At the attribute level, the
filter checks whether all attributes in the user's query are accessible to the
user and, if so, passes the query to the database manager. On return, it
deletes all fields to which the user has no access rights.
At the element level, the
system requests desired data plus cryptographic checksum information. When
these are returned, it checks the classification level of every element of
every record retrieved against the user's level.
Suppose a group of physicists in Washington
works on very sensitive projects, so the current user should not be allowed to
access the physicists' names in the database. This restriction presents a
problem with this query:
retrieve NAME where ((OCCUP=PHYSICIST) ^(CITY=WASHDC))
Suppose, too, that the
current user is prohibited from knowing anything about any people in Moscow.
Using a conventional DBMS, the query might access all records, and the DBMS
would then pass the results on to the user. However, as we have seen, the user
might be able to infer things about Moscow employees or Washington physicists
working on secret projects without even accessing those fields directly.
The commutative filter re-forms the original
query in a trustable way so that sensitive information is never extracted from
the database. Our sample query would become

The filter works by
restricting the query to the DBMS and then restricting the results before they
are returned to the user. In this instance, the filter would request NAME,
NAME-SECRECY-LEVEL, OCCUP, OCCUP-SECRECY-LEVEL, CITY, and CITY-SECRECY-LEVEL
values and would then filter and return to the user only those fields and items
that are of a secrecy level acceptable for the user. Although even this simple
query becomes complicated because of the added terms, these terms are all added
by the front-end filter, invisible to the user.
An example of this query filtering in operation
is shown in Figure 6-12. The advantage
of the commutative filter is that it allows query selection, some optimization,
and some subquery handling to be done by the DBMS. This delegation of duties
keeps the size of the security filter small, reduces redundancy between it and
the DBMS, and improves the overall efficiency of the system.
Distributed Databases
The distributed or federated
database is a fourth design for a secure multilevel database. In this case, a
trusted front end controls access to two unmodified commercial DBMSs: one for
all low-sensitivity data and one for all high-sensitivity data.
The front end takes a user's
query and formulates single-level queries to the databases as appropriate. For
a user cleared for high-sensitivity data, the front end submits queries to both
the high- and low-sensitivity databases. But if the user is not cleared for
high-sensitivity data, the front end submits a query to only the
low-sensitivity database. If the result is obtained from either back-end
database alone, the front end passes the result back to the user. If the result
comes from both databases, the front end has to combine the results
appropriately. For example, if the query is a join query having some
high-sensitivity terms and some low, the front end has to perform the
equivalent of a database join itself.
The distributed database
design is not popular because the front end, which must be trusted, is complex,
potentially including most of the functionality of a full DBMS itself. In
addition, the design does not scale well to many degrees of sensitivity; each
sensitivity level of data must be maintained in its own separate database.
Window/View
Traditionally, one of the
advantages of using a DBMS for multiple users of different interests (but not
necessarily different sensitivity levels) is the ability to create a different
view for each user. That is, each user is restricted to a picture of the data
reflecting only what the user needs to see. For example, the registrar may see
only the class assignments and grades of each student at a university, not
needing to see extracurricular activities or medical records. The university
health clinic, on the other hand, needs medical records and drug-use
information but not scores on standardized academic tests.
The notion of a window or a
view can also be an organizing principle for multilevel database access. A
window is a subset of a database, containing exactly the information that a
user is entitled to access. Denning [DEN87a]
surveys the development of views for multilevel database security.
A view can represent a single
user's subset database so that all of a user's queries access only that
database. This subset guarantees that the user does not access values outside
the permitted ones, because nonpermitted values are not even in the user's
database. The view is specified as a set of relations in the database, so the
data in the view subset change as data change in the database.
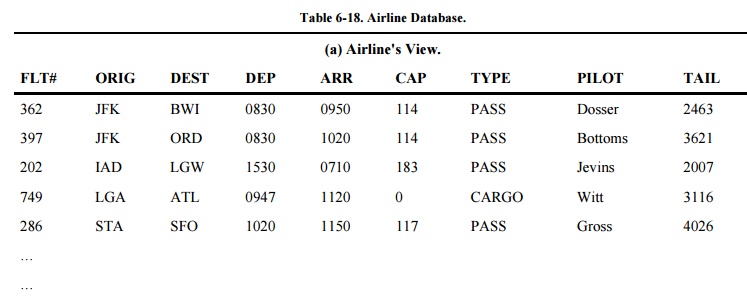
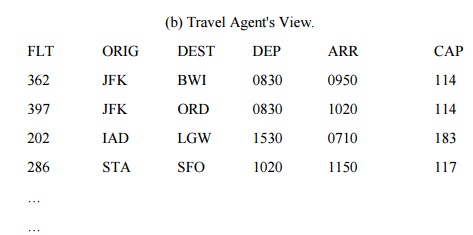
For example, a travel agent
might have access to part of an airline's flight information database. Records
for cargo flights would be excluded, as would the pilot's name and the serial
number of the plane for every flight. Suppose the database contained an
attribute TYPE whose value was either CARGO or PASS (for passenger). Other
attributes might be flight number, origin, destination, departure time, arrival
time, capacity, pilot, and tail number.
Now suppose the airline created some passenger
flights with lower fares that could be booked only directly through the
airline. The airline might assign their flight numbers a more sensitive rating
to make these flights unavailable to travel agents. The whole database, and the
agent's view, might have the logical structure shown in Table 6-18.
The travel agent's view of
the database is expressed as
view AGENT-INFO
FLTNO:=MASTER.FLTNO
ORIG:=MASTER.ORIG
DEST:=MASTER.DEST
DEP:=MASTER.DEP
ARR:=MASTER.ARR
CAP:=MASTER.CAP
where
MASTER.TYPE='PASS' class AGENT
auth retrieve
Because the access class of
this view is AGENT, more sensitive flight numbers (flights booked only through
the airline) do not appear in this view. Alternatively, we could have
eliminated the entire records for those flights by restricting the record
selection with a where clause. A view may involve computation or complex selection
criteria to specify subset data.
The data presented to a user
is obtained by filtering of the contents of the original database. Attributes,
records, and elements are stripped away so that the user sees only acceptable
items. Any attribute (column) is withheld unless the user is authorized to
access at least one element. Any record (row) is withheld unless the user is
authorized to access at least one element. Then, for all elements that still
remain, if the user is not authorized to access the element, it is replaced by
UNDEFINED. This last step does not compromise any data because the user knows
the existence of the attribute (there is at least one element that the user can
access) and the user knows the existence of the record (again, at least one
accessible element exists in the record).
In addition to elements, a view includes
relations on attributes. Furthermore, a user can create new relations from new
and existing attributes and elements. These new relations are accessible to
other users, subject to the standard access rights. A user can operate on the
subset database defined in a view only as allowed by the operations authorized
in the view. As an example, a user might be allowed to retrieve records
specified in one view or to retrieve and update records as specified in another
view. For instance, the airline in our example may restrict travel agents to
retrieving data.
The Sea Views project described in [DEN87a, LUN90a]
is the basis for a system that integrates a trusted operating system to form a
trusted database manager. The layered implementation as described is shown in Figure 6-13. The lowest layer, the reference
monitor, performs file interaction, enforcing the BellLa Padula access
controls, and does user authentication. Part of its function is to filter data
passed to higher levels. The second level performs basic indexing and
computation functions of the database. The third level translates views into
the base relations of the database. These three layers make up the trusted
computing base (TCB) of the system. The remaining layers implement normal DBMS
functions and the user interface.
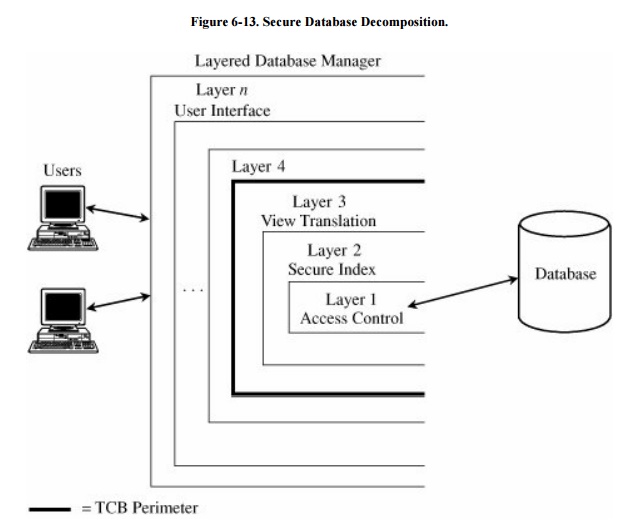
This layered approach makes
views both a logical division of a database and a functional one. The approach
is an important step toward the design and implementation of a trustable
database management system.
Practical Issues
The multilevel security
problem for databases has been studied since the 1970s. Several promising
research results have been identified, as we have seen in this chapter.
However, as with trusted operating systems, the consumer demand has not been
sufficient to support many products. Civilian users have not liked the
inflexibility of the military multilevel security model, and there have been
too few military users. Consequently, multilevel secure databases are primarily
of research and historical interest.
The general concepts of
multilevel databases are important. We do need to be able to separate data
according to their degree of sensitivity. Similarly, we need ways of combining
data of different sensitivities into one database (or at least into one virtual
database or federation of databases). And these needs will only increase over
time as larger databases contain more sensitive information, especially for
privacy concerns.
In the next section we study data mining, a
technique of growing significance, but one for which we need to be able to
address degrees of sensitivity of the data.
Related Topics