Chapter: Security in Computing : Database and Data Mining Security
Multilevel Databases
Multilevel Databases
So far, we have considered data in only two
categories: either sensitive or nonsensitive. We have alluded to some data
items being more sensitive than others, but we have allowed only yes-or-no
access. Our presentation may have implied that sensitivity was a function of
the attribute, the column in which the data appeared, although nothing we have
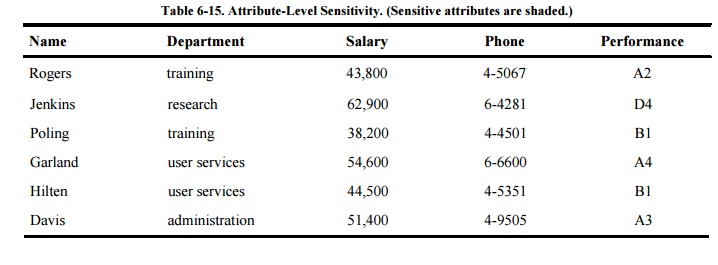
done depended on this interpretation of sensitivity. Such a model appears in Table 6-15, where two columns are identified (by
shading) as sensitive. In fact, though, sensitivity is determined not just by
attribute but also in ways that we investigate in the next section.
Sidebar
6-5: Who Wrote Shakespeare's Plays?
Most people would answer
"Shakespeare" when asked who wrote any of the plays attributed to the
bard. But for 150 years literary scholars have had their doubts. In 1852, it
was suggested that Edward de Vere, Earl of Oxford, wrote at least some of the
works. For decades scholarly debate raged, citing what was known of
Shakespeare's education, travels, work schedule, and the few other facts known
about him.
In the 1980s a new analytic technique was
developed: computerized analysis of text. Different researchers studied
qualities such as word choice, images used in different plays, word pairs,
sentence structure, and the likeany structural element that could show
similarity or dissimilarity. (See, for example, [FAR96a] and [KAR01],
as well as www.shakespearefellowship.org.) The debate continues as
researchers develop more and more qualities to correlate among databases (the
language of the plays and other works attributed to Shakespeare). The debate
will probably never be settled.
But the technique has proven useful. In
1996, an author called Anonymous published the novel Primary Colors. Many
people tried to determine who the author was. But Donald Foster, a professor at
Vassar College, aided by some simple computer tools, attributed the novel to
Joe Klein, who later admitted being the author. Neumann [NEU96] in the
Risks forum, notes how hard it is to lie convincingly, even having tried to
alter your writing style, given "telephone records, credit-card records,
airplane reservation databases, library records, snoopy neighbors, coincidental
encounters, etc."in short, given aggregation.
The
approach has uses outside the literary field. In 2002 the SAS Institute,
vendors of statistical analysis software, introduced data mining software
intended to find patterns in old e-mail messages and other masses of text. The
company suggests the tool might be useful in identifying and blocking spam.
Another possible use is detecting lies, or perhaps just flagging potential
inconsistencies. It could also help locate the author of malicious code.
The Case for Differentiated Security
Consider a database
containing data on U.S. government expenditures. Some of the expenditures are
for paper clips, which is not sensitive information. Some salary expenditures
are subject to privacy requirements. Individual salaries are sensitive, but the
aggregate (for example, the total Agriculture Department payroll, which is a
matter of public record) is not sensitive. Expenses of certain military
operations are more sensitive; for example, the total amount the United States
spends for ballistic missiles, which is not public. There are even operations
known only to a few people, and so the amount spent on these operations, or
even the fact that anything was spent on such an operation, is highly
sensitive.
Table 6-15 lists employee
information. It may in fact be the case that Davis is a temporary employee
hired for a special project, and her whole record has a different
sensitivity from the others. Perhaps the phone shown for Garland is her private
line, not available to the public. We can refine the sensitivity of the data by
depicting it as shown in Table 6-16.
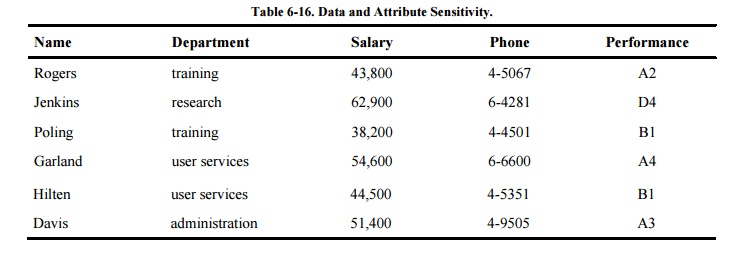
From this description, three
characteristics of database security emerge.
The security of a single
element may be different from the security of other elements of the same record
or from other values of the same attribute. That is, the security of one
element may differ from that of other elements of the same row or column. This
situation implies that security should be implemented for each individual
element.
Two levelssensitive and
nonsensitiveare inadequate to represent some security situations. Several
grades of security may be needed. These grades may represent ranges of
allowable knowledge, which may overlap. Typically, the security grades form a
lattice.
The security of an aggregatea
sum, a count, or a group of values in a databasemay differ from the security of
the individual elements. The security of the aggregate may be higher or lower
than that of the individual elements.
These three principles lead
to a model of security not unlike the military model of security encountered in
Chapter 5, in which the sensitivity of
an object is defined as one of n levels and is further separated into
compartments by category.
Granularity
Recall that the military
classification model applied originally to paper documents and was adapted to
computers. It is fairly easy to classify and track a single sheet of paper or,
for that matter, a paper file, a computer file, or a single program or process.
It is entirely different to classify individual data items.
For obvious reasons, an
entire sheet of paper is classified at one level, even though certain words,
such as and, the, or of, would be innocuous in any context, and other words,
such as codewords like Manhattan project, might be sensitive in any context.
But defining the sensitivity of each value in a database is similar to applying
a sensitivity level to each individual word of a document.
And the problem is still more
complicated. The word Manhattan by itself is not sensitive, nor is project.
However, the combination of these words produces the sensitive codeword
Manhattan project. A similar situation occurs in databases. Therefore, not only
can every element of a database have a distinct sensitivity, every combination
of elements can also have a distinct sensitivity. Furthermore, the combination
can be more or less sensitive than any of its elements.
So what would we need in
order to associate a sensitivity level with each value of a database? First, we
need an access control policy to dictate which users may have access to what
data. Typically, to implement this policy each data item is marked to show its
access limitations. Second, we need a means to guarantee that the value has not
been changed by an unauthorized person. These two requirements address both
confidentiality and integrity.
Security Issues
In Chapter 1 , we introduced three general security concerns:
integrity, confidentiality, and availability. In this section, we extend the
first two of these concepts to include their special roles for multilevel
databases.
Integrity
Even in a single-level
database in which all elements have the same degree of sensitivity, integrity
is a tricky problem. In the case of multilevel databases, integrity becomes
both more important and more difficult to achieve. Because of the *-property
for access control, a process that reads high-level data is not allowed to
write a file at a lower level. Applied to databases, however, this principle
says that a high-level user should not be able to write a lower-level data
element.
The problem with this
interpretation arises when the DBMS must be able to read all records in the
database and write new records for any of the following purposes: to do
backups, to scan the database to answer queries, to reorganize the database
according to a user's processing needs, or to update all records of the
database.
When people encounter this problem, they handle
it by using trust and common sense. People who have access to sensitive
information are careful not to convey it to uncleared individuals. In a
computing system, there are two choices: Either the process cleared at a high
level cannot write to a lower level or the process must be a "trusted
process," the computer equivalent of a person with a security clearance.
Confidentiality
Users trust that a database
will provide correct information, meaning that the data are consistent and
accurate. As indicated earlier, some means of protecting confidentiality may
result in small changes to the data. Although these perturbations should not
affect statistical analyses, they may produce two different answers representing
the same underlying data value in response to two differently formed queries.
In the multilevel case, two different users operating at two different levels
of security might get two different answers to the same query. To preserve
confidentiality, precision is sacrificed.
Enforcing confidentiality
also leads to unknowing redundancy. Suppose a personnel specialist works at one
level of access permission. The specialist knows that Bob Hill works for the
company. However, Bob's record does not appear on the retirement payment
roster. The specialist assumes this omission is an error and creates a record
for Bob.
The reason that no record for Bob appears is
that Bob is a secret agent, and his employment with the company is not supposed
to be public knowledge. A record on Bob actually is in the file but, because of
his special position, his record is not accessible to the personnel specialist.
The DBMS cannot reject the record from the personnel specialist because doing
so would reveal that there already is such a record at a sensitivity too high
for the specialist to see. The creation of the new record means that there are
now two records for Bob Hill: one sensitive and one not, as shown in Table 6-17. This situation is called polyinstantiation, meaning that one
record can appear (be instantiated) many times, with a different level of
confidentiality each time.

This problem is exacerbated
because Bob Hill is a common enough name that there might be two different
people in the database with that name. Thus, merely scanning the database (from
a high-sensitivity level) for duplicate names is not a satisfactory way to find
records entered unknowingly by people with only low clearances.
We might also find other reasons, unrelated to
sensitivity level, that result in polyinstantiation. For example, Mark Thyme
worked for Acme Corporation for 30 years and retired. He is now drawing a
pension from Acme, so he appears as a retiree in one personnel record. But Mark
tires of being home and is rehired as a part-time contractor; this new work
generates a second personnel record for Mark. Each is a legitimate employment
record. In our zeal to reduce polyinstantiation, we must be careful not to
eliminate legitimate records such as these.
Related Topics