Chapter: Security in Computing : Database and Data Mining Security
Introduction to Databases
Introduction to Databases
We begin by describing a
database and defining terminology related to its use. We draw on examples from
what is called the relational database because it is one of the most widely
used types. However, all the concepts described here apply to any type of
database. We first define the basic concepts and then use them to discuss
security concerns.
Concept of a Database
A database is a collection of data and a set of rules that organize
the data by specifying certain relationships among the data. Through these
rules, the user describes a logical format for the data. The data items are
stored in a file, but the precise physical format of the file is of no concern
to the user. A database administrator
is a person who defines the rules that organize the data and also controls who
should have access to what parts of the data. The user interacts with the
database through a program called a database
manager or a database management system (DBMS), informally
known as a front end.
Components of Databases
The database file consists of records, each of which contains one
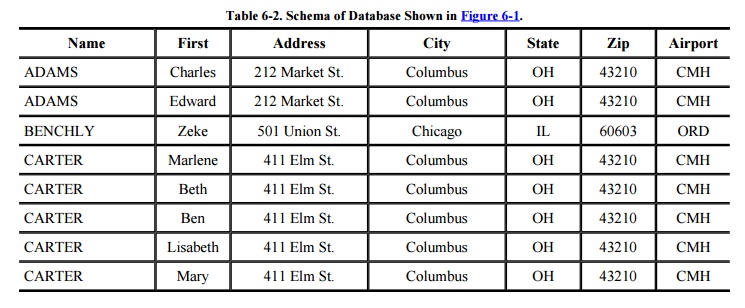
related group of data. As shown in the example in Table
6 -1, a record in a name and address file consists of one name and
address. Each record contains fields
or elements, the elementary data
items themselves. The fields in the name and address record are NAME, ADDRESS,
CITY, STATE, and ZIP (where ZIP is the U.S. postal code). This database can be
viewed as a two-dimensional table, where a record is a row and each field of a
record is an element of the table.

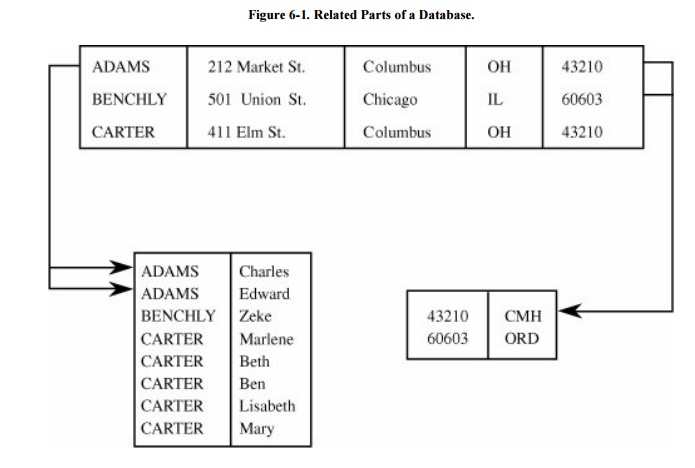
Not every database is easily represented as a
single, compact table. The database in Figure 6-1
logically consists of three files with possibly different uses. These three
files could be represented as one large table, but that depiction may not
improve the utility of or access to the data.
The logical structure of a database is called a
schema. A particular user may have
access to only part of the database, called a subschema. The overall schema of the database in Figure 6-1 is detailed in Table 6-2. The three separate blocks of the
figure are examples of subschemas, although other subschemas of this database
can be defined. We can use schemas and subschemas to present to users only
those elements they wish or need to see. For example, if Table 6 -1 represents the employees at a company,
the subschema on the lower left can list employee names without revealing
personal information such as home address.
The rules of a database identify the columns
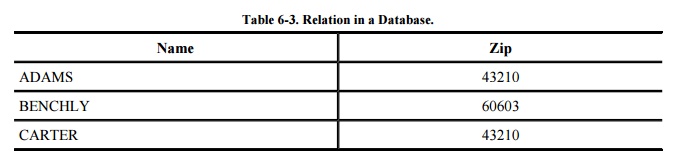
with names. The name of each column is called an attribute of the database. A relation
is a set of columns. For example, using the database in Table 6-2, we see that NAMEZIP is a relation
formed by taking the NAME and ZIP columns, as shown in Table 6-3. The relation specifies clusters of
related data values in much the same way that the relation "mother
of" specifies a relationship among pairs of humans. In this example, each
cluster contains a pair of elements, a NAME and a ZIP. Other relations can have
more columns, so each cluster may be a triple, a 4-tuple, or an n-tuple (for
some value n) of elements.
Queries
Users interact with database
managers through commands to the DBMS that retrieve, modify, add, or delete
fields and records of the database. A command is called a query. Database management systems have precise rules of syntax for
queries. Most query languages use an English-like notation, and many are based
on SQL, a structured query language originally developed by IBM. We have
written the example queries in this chapter to resemble English sentences so
that they are easy to understand. For example, the query
SELECT NAME = 'ADAMS'
retrieves all records having
the value ADAMS in the NAME field.
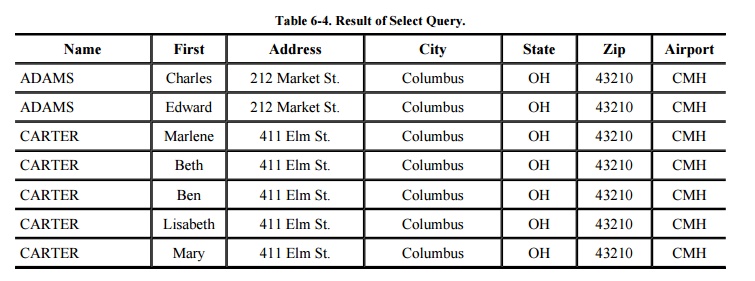
The result of executing a query is a subschema.
One way to form a subschema of a database is by selecting records meeting
certain conditions. For example, we might select records in which ZIP=43210,
producing the result shown in Table 6-4.
After having selected records, we may project these records onto one or more
attributes. The select operation identifies certain rows from the database, and
a project operation extracts the values from certain fields (columns) of those
records. The result of a select-project operation is the set of values of
specified attributes for the selected records. For example, we might select
records meeting the condition ZIP=43210 and project the results onto the
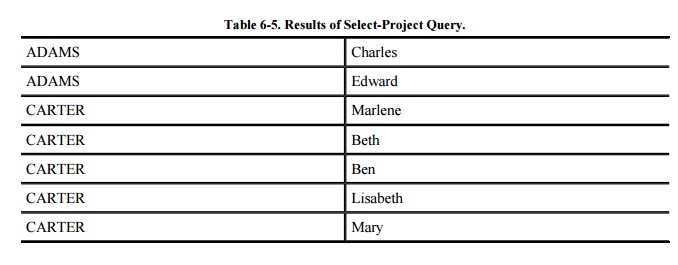
attributes NAME and FIRST, as in Table 6-5.
The result is the list of first and last names of people whose addresses have
zip code 43210.
Notice that we do not have to project onto the
same attribute(s) on which the selection is done. For example, we can build a
query using ZIP and NAME but project the result onto FIRST:

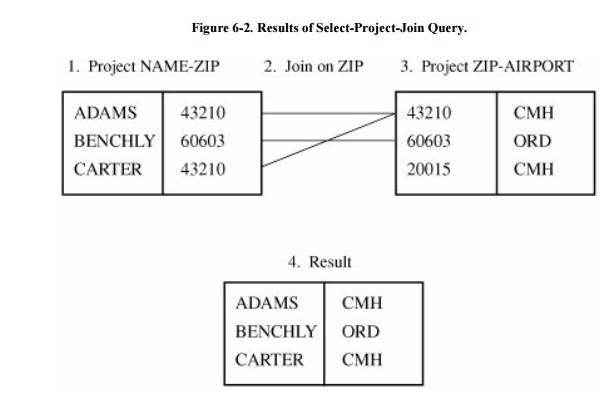
We can also merge two subschema on a common
element by using a join query. The
result of this operation is a subschema whose records have the same value for
the common element. For example, Figure 6-2
shows that the subschema NAMEZIP and the subschema ZIPAIRPORT can be joined on
the common field ZIP to produce the subschema NAMEAIRPORT.
Advantages of Using Databases
The logical idea behind a
database is this: A database is a single collection of data, stored and
maintained at one central location, to which many people have access as needed.
However, the actual implementation may involve some other physical storage
arrangement or access. The essence of a good database is that the users are
unaware of the physical arrangements; the unified logical arrangement is all
they see. As a result, a database offers many advantages over a simple file
system:
z shared access, so that many
users can use one common, centralized set of data
minimal redundancy, so that
individual users do not have to collect and maintain their own sets of data
data consistency, so that a
change to a data value affects all users of the data value
data integrity, so that data
values are protected against accidental or malicious undesirable changes
controlled access, so that
only authorized users are allowed to view or to modify data values
A DBMS is designed to provide these advantages
efficiently. However, as often happens, the objectives can conflict with each
other. In particular, as we shall see, security interests can conflict with
performance. This clash is not surprising because measures taken to enforce
security often increase the computing system's size or complexity. What is
surprising, though, is that security interests may also reduce the system's
ability to provide data to users by limiting certain queries that would
otherwise seem innocuous.
Related Topics