Chapter: Distributed and Cloud Computing: From Parallel Processing to the Internet of Things : Distributed System Models and Enabling Technologies
Scalable Computing Over the Internet
SCALABLE COMPUTING OVER THE INTERNET
Over the past 60 years,
computing technology has undergone a series of platform and environment
changes. In this section, we assess evolutionary changes in machine
architecture, operating system platform, network connectivity, and application
workload. Instead of using a centralized computer to solve computational
problems, a parallel and distributed computing system uses multiple computers
to solve large-scale problems over the Internet. Thus, distributed computing
becomes data-intensive and network-centric. This section identifies the
applications of modern computer systems that practice parallel and distributed
computing. These large-scale Internet applications have significantly enhanced
the quality of life and information services in society today.
1. The Age of Internet Computing
Billions of people use the
Internet every day. As a result, supercomputer sites and large data centers
must provide high-performance computing services to huge numbers of Internet
users concurrently. Because of this high demand, the Linpack Benchmark for high-performance computing (HPC) applications is no longer
optimal for measuring system performance. The emergence of computing clouds
instead demands high-throughput
computing (HTC) systems built with parallel and distribu-ted computing
technologies [5,6,19,25]. We have to upgrade data centers using fast servers,
storage systems, and high-bandwidth networks. The purpose is to advance
network-based computing and web services with the emerging new technologies.
1.1
The Platform Evolution
Computer technology has gone
through five generations of development, with each generation lasting from 10
to 20 years. Successive generations are overlapped in about 10 years. For
instance, from 1950 to 1970, a handful of mainframes, including the IBM 360 and
CDC 6400, were built to satisfy the demands of large businesses and government
organizations. From 1960 to 1980, lower-cost mini-computers such as the DEC PDP
11 and VAX Series became popular among small businesses and on college
campuses.
From 1970 to 1990, we saw
widespread use of personal computers built with VLSI microproces-sors. From
1980 to 2000, massive numbers of portable computers and pervasive devices
appeared in both wired and wireless applications. Since 1990, the use of both
HPC and HTC systems hidden in
clusters, grids, or Internet
clouds has proliferated. These systems are employed by both consumers and
high-end web-scale computing and information services.
The
general computing trend is to leverage shared web resources and massive amounts
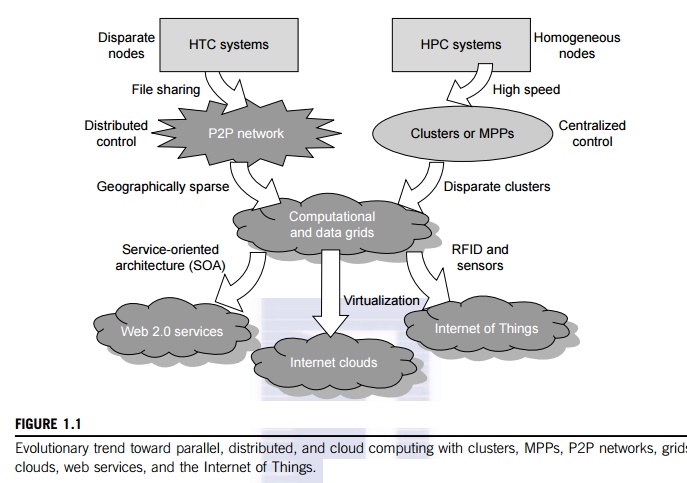
of data over the Internet. Figure 1.1 illustrates the evolution of HPC and HTC
systems. On the HPC side, supercomputers (massively parallel processors or MPPs) are gradually replaced by clusters of
cooperative computers out of a desire to share computing resources. The cluster
is often a collection of homogeneous compute nodes that are physically
connected in close range to one another. We will discuss clusters, MPPs, and
grid systems in more detail in Chapters 2 and 7.
On the
HTC side, peer-to-peer
(P2P)
networks are formed for distributed file sharing and content delivery
applications. A P2P system is built over many client machines (a concept we
will discuss further in Chapter 5). Peer machines are globally distributed in
nature. P2P, cloud computing, and web service platforms are more focused on HTC
applications than on HPC appli-cations. Clustering and P2P technologies lead to
the development of computational grids or data grids.
1.2
High-Performance Computing
For many years, HPC systems
emphasize the raw speed performance. The speed of HPC systems has increased
from Gflops in the early 1990s to now Pflops in 2010. This improvement was
driven mainly by the demands from scientific, engineering, and manufacturing
communities. For example, the Top 500 most powerful computer systems in the
world are measured by floating-point speed in Linpack benchmark results.
However, the number of supercomputer users is limited to less than 10% of all
computer users. Today, the majority of computer users are using desktop
computers or large servers when they conduct Internet searches and
market-driven computing tasks.
1.3
High-Throughput Computing
The development of market-oriented
high-end computing systems is undergoing a strategic change from an HPC
paradigm to an HTC paradigm. This HTC paradigm pays more attention to high-flux
computing. The main application for high-flux computing is in Internet searches
and web services by millions or more users simultaneously. The performance goal
thus shifts to measure high throughput or the number of tasks completed per unit of
time. HTC technology needs to not only improve in terms of batch processing speed, but
also address the acute problems of cost, energy savings, security, and
reliability at many data and enterprise computing centers. This book will
address both HPC and HTC systems to meet the demands of all computer users.
1.4
Three New Computing Paradigms
As Figure 1.1 illustrates,
with the introduction of SOA, Web 2.0 services become available. Advances in
virtualization make it possible to see the growth of Internet clouds as a new
computing paradigm. The maturity of radio-frequency identification (RFID), Global Positioning System (GPS), and sensor technologies has
triggered the development of the Internet of Things (IoT). These new paradigms are
only briefly introduced here. We will study the details of SOA in Chapter 5;
virtualization in Chapter 3; cloud computing in Chapters 4, 6, and 9; and the
IoT along with cyber-physical systems (CPS) in Chapter 9.
When the
Internet was introduced in 1969, Leonard Klienrock of UCLA declared: “As of now, computer networks are still in their
infancy, but as they grow up and become sophisticated, we will probably see the
spread of computer utilities, which like present electric and telephone
utilities, will service individual homes and offices across the country.” Many people have redefined the term “computer” since that time. In 1984, John Gage of Sun
Microsystems created the slogan, “The net-work is the computer.” In 2008, David Patterson of UC Berkeley said, “The data center is the compu-ter. There are
dramatic differences between developing software for millions to use as a service
versus distributing software to run on their PCs.” Recently, Rajkumar Buyya of Melbourne
University simply said: “The cloud is the computer.”
This
book covers clusters, MPPs, P2P networks, grids, clouds, web services, social
networks, and the IoT. In fact, the differences among clusters, grids, P2P
systems, and clouds may blur in the future. Some people view clouds as grids or
clusters with modest changes through virtualization. Others feel the changes
could be major, since clouds are anticipated to process huge data sets
gener-ated by the traditional Internet, social networks, and the future IoT. In
subsequent chapters, the distinctions and dependencies among all distributed
and cloud systems models will become clearer and more transparent.
1.5
Computing Paradigm Distinctions
The high-technology community
has argued for many years about the precise definitions of centralized
computing, parallel computing, distributed computing, and cloud computing. In
general,
distributed computing is the opposite of centralized computing. The field of parallel computing overlaps with distributed
computing to a great extent, and cloud computing overlaps with distributed, centralized, and
parallel computing. The following list defines these terms more clearly; their architec-tural
and operational differences are discussed further in subsequent chapters.
• Centralized computing This is
a computing paradigm by which all computer resources are centralized in one
physical system. All resources (processors, memory, and storage) are fully
shared and tightly coupled within one integrated OS. Many data centers and
supercomputers are centralized
systems, but they are used in parallel, distributed, and cloud computing
applications [18,26].
• Parallel computing In
parallel computing, all processors are either tightly coupled with centralized
shared memory or loosely coupled with distributed memory. Some authors refer to
this discipline as parallel
processing [15,27]. Interprocessor communication is accomplished through
shared memory or via message passing. A computer system capable of parallel
computing is commonly known as a parallel computer [28]. Programs running in a parallel computer
are called parallel
programs. The process of writing parallel programs is often referred to as parallel programming [32].
• Distributed computing This is
a field of computer science/engineering that studies distributed systems. A distributed system [8,13,37,46] consists of
multiple autonomous computers, each having its own private memory,
communicating through a computer network. Information exchange in a distributed
system is accomplished through message
passing. A computer program that runs in a distributed system is known as
a distributed program. The process of writing
distributed programs is referred to as distributed programming.
• Cloud computing An Internet cloud of resources can be either a centralized or a
distributed computing system. The cloud applies parallel or distributed
computing, or both. Clouds can be built with physical or virtualized resources
over large data centers that are centralized or distributed. Some authors
consider cloud computing to be a form of utility computing or service computing [11,19].
As an
alternative to the preceding terms, some in the high-tech community prefer the
term con-current computing or concurrent programming. These terms typically refer
to the union of parallel computing and distributing
computing, although biased practitioners may interpret them differently. Ubiquitous computing refers to computing with
pervasive devices at any place and time using wired or wireless communication. The Internet of Things (IoT) is a networked
connection of everyday objects including computers, sensors, humans, etc. The
IoT is supported by Internet clouds to achieve ubiquitous computing with any
object at any place and time. Finally, the term Internet computing is even broader and covers all computing
paradigms over the Internet. This book covers all the aforementioned computing paradigms,
placing more emphasis on distributed and cloud com-puting and their working
systems, including the clusters, grids, P2P, and cloud systems.
1.6
Distributed System Families
Since the mid-1990s,
technologies for building P2P networks and networks of clusters have been consolidated into
many national projects designed to establish wide area computing
infrastructures, known as computational
grids or data grids. Recently, we have witnessed a surge in
interest in exploring Internet cloud resources for data-intensive applications.
Internet clouds are the result of moving desktop computing to service-oriented
computing using server clusters and huge databases at data centers. This
chapter introduces the basics of various parallel and distributed families.
Grids and clouds are disparity systems that place great emphasis on resource
sharing in hardware, software, and data sets.
Design
theory, enabling technologies, and case studies of these massively distributed
systems are also covered in this book. Massively distributed systems are
intended to exploit a high degree of parallelism or concurrency among many
machines. In October 2010, the highest performing cluster machine was built in
China with 86016 CPU processor cores and 3,211,264 GPU cores in a Tianhe-1A
system. The largest computational grid connects up to hundreds of server
clus-ters. A typical P2P network may involve millions of client machines
working simultaneously. Experimental cloud computing clusters have been built
with thousands of processing nodes. We devote the material in Chapters 4
through 6 to cloud computing. Case studies of HTC systems will be examined in
Chapters 4 and 9, including data centers, social networks, and virtualized
cloud platforms
In the
future, both HPC and HTC systems will demand multicore or many-core processors
that can handle large numbers of computing threads per core. Both HPC and HTC
systems emphasize parallelism and distributed computing. Future HPC and HTC
systems must be able to satisfy this huge demand in computing power in terms of
throughput, efficiency, scalability, and reliability. The system efficiency is
decided by speed, programming, and energy factors (i.e., throughput per watt of energy consumed). Meeting
these goals requires to yield the following design objectives:
• Efficiency measures the
utilization rate of resources in an execution model by exploiting massive
parallelism in HPC. For HTC, efficiency is more closely related to job
throughput, data access, storage, and power efficiency.
• Dependability measures the
reliability and self-management from the chip to the system and application
levels. The purpose is to provide high-throughput service with Quality of
Service (QoS) assurance, even under failure conditions.
• Adaptation in the programming
model measures the ability to support billions of job requests over massive
data sets and virtualized cloud resources under various workload and service
models.
• Flexibility in application
deployment measures the ability of distributed systems to run well in both HPC
(science and engineering) and HTC (business) applications.
2. Scalable Computing Trends and New
Paradigms
Several predictable trends in
technology are known to drive computing applications. In fact, designers and
programmers want to predict the technological capabilities of future systems.
For instance, Jim Gray’s paper, “Rules of Thumb in Data Engineering,” is an excellent example of how technology
affects applications and vice versa. In addition, Moore’s law indicates that processor speed doubles
every 18 months. Although Moore’s law has been proven valid
over the last 30 years, it is difficult to say whether it will continue to be
true in the future.
Gilder’s law indicates that network bandwidth has
doubled each year in the past. Will that trend continue in the future? The
tremendous price/performance ratio of commodity hardware was driven by the
desktop, notebook, and tablet computing markets. This has also driven the
adoption and use of commodity technologies in large-scale computing. We will
discuss the future of these computing trends in more detail in subsequent
chapters. For now, it’s important to understand how
distributed systems emphasize both resource distribution and concurrency or
high degree of parallelism (DoP). Let’s review the degrees of parallelism before we
discuss the special requirements for distributed computing.
2.1
Degrees of Parallelism
Fifty years ago, when hardware was bulky and
expensive, most computers were designed in a bit-serial fashion. In this
scenario, bit-level parallelism (BLP) converts bit-serial processing to word-level
processing gradually. Over the years, users graduated from 4-bit
microprocessors to 8-, 16-, 32-, and 64-bit CPUs. This led us to the next wave
of improvement, known as instruction-level parallelism
(ILP), in which the processor executes multiple
instructions simultaneously rather than only one instruction at a time. For the past 30
years, we have practiced ILP through pipelining, super-scalar computing, VLIW (very long instruction word) architectures, and multithreading. ILP
requires branch prediction, dynamic scheduling, speculation, and compiler
support to work efficiently.
Data-level parallelism (DLP) was made popular through SIMD (single instruction, multiple data) and vector machines using vector or array types
of instructions. DLP requires even more hard-ware support and compiler assistance
to work properly. Ever since the introduction of multicore processors and chip multiprocessors (CMPs), we have been exploring task-level parallelism (TLP). A modern processor explores all of the
aforementioned parallelism types. In fact, BLP, ILP, and DLP are well supported by advances in
hardware and compilers. However, TLP is far from being very successful due to
difficulty in programming and compilation of code for efficient execution on
multicore CMPs. As we move from parallel processing to distributed processing,
we will see an increase in computing granularity to job-level parallelism (JLP). It is fair to say that
coarse-grain parallelism is built on top of fine-grain parallelism.
2.2
Innovative Applications
Both HPC and HTC systems desire
transparency in many application aspects. For example, data access, resource
allocation, process location, concurrency in execution, job replication, and
failure recovery should be made transparent to both users and system
management. Table 1.1 highlights a few key applications that have driven the
development of parallel and distributed systems over the
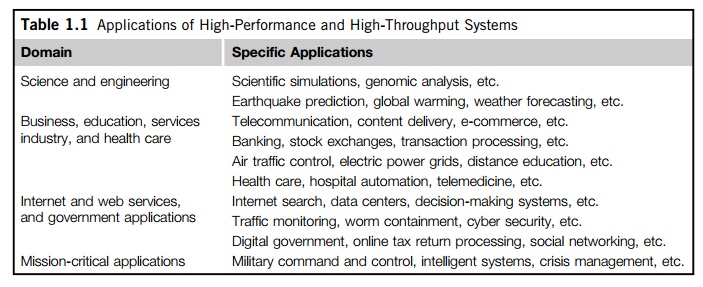
years. These applications
spread across many important domains in science, engineering, business,
education, health care, traffic control, Internet and web services, military,
and government applications.
Almost
all applications demand computing economics, web-scale data collection, system
reliability, and scalable performance. For example, distributed transaction
processing is often prac-ticed in the banking and finance industry.
Transactions represent 90 percent of the existing market for reliable banking
systems. Users must deal with multiple database servers in distributed
transactions. Maintaining the consistency of replicated transaction records is
crucial in real-time banking services. Other complications include lack of
software support, network saturation, and security threats in these
applications. We will study applications and software support in more detail in
subsequent chapters.
2.3
The Trend toward Utility Computing
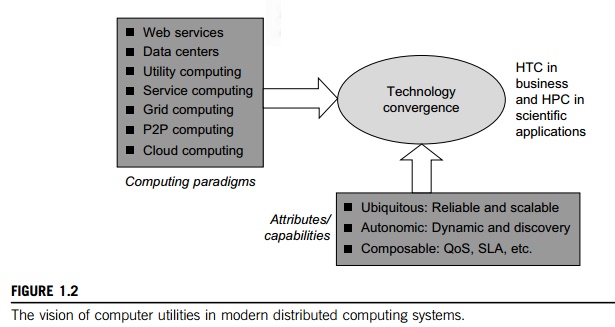
Figure 1.2 identifies major
computing paradigms to facilitate the study of distributed systems and their
applications. These paradigms share some common characteristics. First, they
are all ubiquitous in daily life. Reliability and scalability are two major
design objectives in these computing models. Second, they are aimed at
autonomic operations that can be self-organized to support dynamic dis-covery.
Finally, these paradigms are composable with QoS and SLAs (service-level agreements). These paradigms and their
attributes realize the computer utility vision.
Utility computing focuses on a business model
in which customers receive computing resources from a paid service provider. All grid/cloud
platforms are regarded as utility service providers. However, cloud computing
offers a broader concept than utility computing. Distributed cloud applications
run on any available servers in some edge networks. Major technological
challenges include all aspects of computer science and engineering. For
example, users demand new network-efficient processors, scalable memory and
storage schemes, distributed OSes, middleware for machine virtualization, new
programming models, effective resource management, and application
program development. These
hardware and software supports are necessary to build distributed systems that
explore massive parallelism at all processing levels.
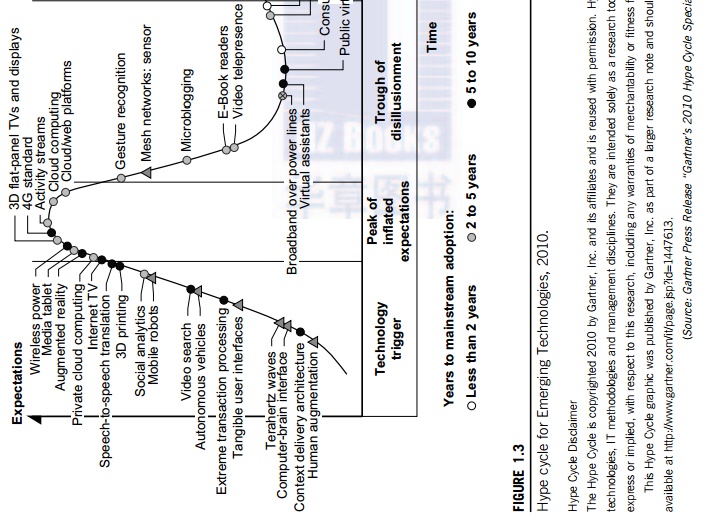
2.4
The Hype Cycle of New Technologies
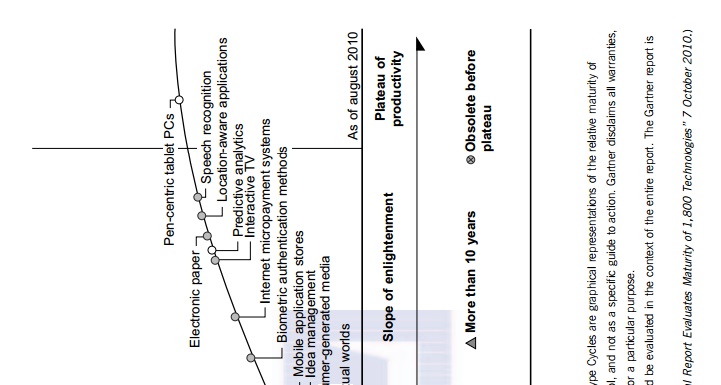
Any new and emerging
computing and information technology may go through a hype cycle, as
illustrated in Figure 1.3. This cycle shows the expectations for the technology
at five different stages. The expectations rise sharply from the trigger period
to a high peak of inflated expectations. Through a short period of
disillusionment, the expectation may drop to a valley and then increase
steadily over a long enlightenment period to a plateau of productivity. The
number of years for an emerging technology to reach a certain stage is marked
by special symbols. The hollow circles indicate technologies that will reach
mainstream adoption in two years. The gray circles represent technologies that
will reach mainstream adoption in two to five years. The solid circles
represent those that require five to 10 years to reach mainstream adoption, and
the triangles denote those that require more than 10 years. The crossed circles
represent technologies that will become obsolete before they reach the plateau.
The hype
cycle in Figure 1.3 shows the technology status as of August 2010. For example,
at that time consumer-generated
media was at
the disillusionment stage, and it was predicted to take less than two years to
reach its plateau of adoption. Internet
micropayment systems were forecast to take two to five years to move from the
enlightenment stage to maturity. It was believed that 3D printing would take five to 10 years to move from the
rising expectation stage to mainstream adop-tion, and mesh network sensors were expected to take more
than 10 years to move from the inflated expectation stage to a plateau of
mainstream adoption.
Also as
shown in Figure 1.3, the cloud
technology had just crossed the peak of the expectation stage in 2010, and it
was expected to take two to five more years to reach the productivity stage.
However, broadband
over power line technology was expected to become obsolete before leaving the
valley of disillusionment stage in 2010. Many additional technologies (denoted
by dark circles in Figure 1.3) were at their peak expectation stage in August
2010, and they were expected to take five to 10 years to reach their plateau of
success. Once a technology begins to climb the slope of enlightenment, it may
reach the productivity plateau within two to five years. Among these promis-ing
technologies are the clouds, biometric authentication, interactive TV, speech
recognition, predictive analytics, and media tablets.
3. The Internet of Things and
Cyber-Physical Systems
In this section, we will
discuss two Internet development trends: the Internet of Things [48] and
cyber-physical systems. These evolutionary trends emphasize the extension of
the Internet to every-day objects. We will only cover the basics of these
concepts here; we will discuss them in more detail in Chapter 9.
3.1
The Internet of Things
The traditional Internet
connects machines to machines or web pages to web pages. The concept of the IoT
was introduced in 1999 at MIT [40]. The IoT refers to the networked interconnection
of everyday objects, tools, devices, or computers. One can view the IoT as a
wireless network of sen-sors that interconnect all things in our daily life.
These things can be large or small and they vary with respect to time and
place. The idea is to tag every object using RFID or a related sensor or
electronic technology such as GPS.
Hype Cycle Disclaimer
The Hype Cycle is copyrighted 2010 by Gartner,
Inc. and its affiliates and is reused with permission. Hype Cycles are graphical
representations of the relative maturity of technologies, IT methodologies and
management disciplines. They are intended solely as a research tool, and not as
a specific guide to action. Gartner disclaims all warranties, express or
implied, with respect to this research, including any warranties of
merchantability or fitness for a particular purpose.
This Hype Cycle graphic was
published by Gartner, Inc. as part of a larger research note and should be
evaluated in the context of the entire report. The Gartner report is available
at http://www.gartner.com/it/page.jsp?id=1447613.
(Source: Gartner Press Release “Gartner’s 2010
Hype Cycle Special Report Evaluates Maturity of 1,800 Technologies” 7 October
2010.)
With the
introduction of the IPv6 protocol, 2128 IP addresses are available to distinguish all
the objects on Earth, including all computers and pervasive devices. The IoT
researchers have estimated that every human being will be surrounded by 1,000
to 5,000 objects. The IoT needs to be designed to track 100 trillion static or
moving objects simultaneously. The IoT demands universal addressa-bility of all
of the objects or things. To reduce the complexity of identification, search,
and storage, one can set the threshold to filter out fine-grain objects. The
IoT obviously extends the Internet and is more heavily developed in Asia and
European countries.
In the IoT era, all objects and devices are instrumented,
interconnected, and interacted with each other intelligently. This
communication can be made between people and things or among the things
themselves. Three communication patterns co-exist: namely H2H (human-to-human),
H2T (human-to-thing), and T2T (thing-to-thing). Here things include machines
such as PCs and mobile phones. The idea here is to connect things (including
human and machine objects) at any time and any place intelligently with low
cost. Any place connections include at the PC, indoor (away from PC), outdoors,
and on the move. Any time connections include daytime, night, outdoors and
indoors, and on the move as well.
The
dynamic connections will grow exponentially into a new dynamic network of
networks, called the Internet
of Things (IoT). The IoT is still in its infancy stage of development. Many
proto-type IoTs with restricted areas of coverage are under experimentation at
the time of this writing. Cloud computing researchers expect to use the cloud
and future Internet technologies to support fast, efficient, and intelligent
interactions among humans, machines, and any objects on Earth. A smart Earth
should have intelligent cities, clean water, efficient power, convenient
transportation, good food supplies, responsible banks, fast telecommunications,
green IT, better schools, good health care, abundant resources, and so on. This
dream living environment may take some time to reach fruition at different
parts of the world.
3.2
Cyber-Physical Systems
A cyber-physical system (CPS) is the result of
interaction between computational processes and the physical world. A CPS
integrates “cyber” (heterogeneous, asynchronous) with “physical” (concur-rent and information-dense) objects. A
CPS merges the “3C” technologies of computation, commu-nication, and control into an intelligent closed feedback system
between the physical world and the information world, a concept which is actively
explored in the United States. The IoT emphasizes various networking
connections among physical objects, while the CPS emphasizes exploration of virtual reality (VR) applications in the physical world. We may
transform how we interact with the physical world just like the Internet
transformed how we interact with the virtual world. We will study IoT, CPS, and
their relationship to cloud computing in Chapter 9.
Related Topics