Chapter: Distributed and Cloud Computing: From Parallel Processing to the Internet of Things : Distributed System Models and Enabling Technologies
System Models for Distributed and Cloud Computing
SYSTEM MODELS FOR DISTRIBUTED AND CLOUD COMPUTING
Distributed and cloud
computing systems are built over a large number of autonomous computer nodes.
These node machines are interconnected by SANs, LANs, or WANs in a hierarchical
man-ner. With today’s networking technology, a
few LAN switches can easily connect hundreds of machines as a working cluster.
A WAN can connect many local clusters to form a very large cluster of clusters.
In this sense, one can build a massive system with millions of computers connected
to edge networks.
Massive systems are
considered highly scalable, and can reach web-scale connectivity, either
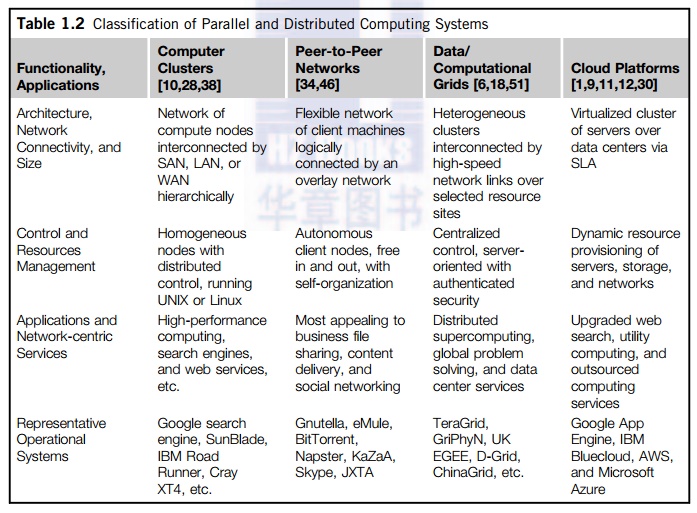
physically or logically. In Table 1.2, massive systems are classified into four
groups: clusters,
P2P networks, computing grids, and Internet clouds over huge data centers. In terms of node
number, these four system classes may
involve hundreds, thousands, or even millions of computers as participating
nodes. These machines work collectively, cooperatively, or collaboratively at
various levels. The table entries characterize these four system classes in
various technical and application aspects.
From the
application perspective, clusters are most popular in supercomputing
applications. In 2009, 417 of the Top 500 supercomputers were built with
cluster architecture. It is fair to say that clusters have laid the necessary
foundation for building large-scale grids and clouds. P2P networks appeal most
to business applications. However, the content industry was reluctant to accept
P2P technology for lack of copyright protection in ad hoc networks. Many
national grids built in the past decade were underutilized for lack of reliable
middleware or well-coded applications. Potential advantages of cloud computing
include its low cost and simplicity for both providers and users.
1. Clusters of Cooperative Computers
A computing cluster consists
of interconnected stand-alone computers which work cooperatively as a single
integrated computing resource. In the past, clustered computer systems have
demonstrated impressive results in handling heavy workloads with large data
sets.
1.1
Cluster Architecture
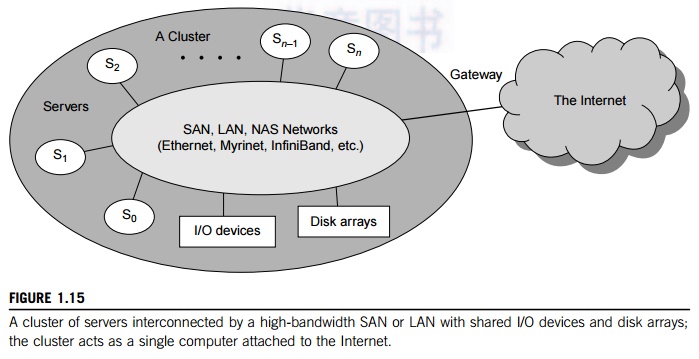
Figure 1.15 shows the
architecture of a typical server cluster built around a low-latency,
high-bandwidth interconnection network. This network can be as simple as a SAN
(e.g., Myrinet) or a LAN (e.g., Ethernet). To build a larger cluster with more
nodes, the interconnection network can be built with multiple levels of Gigabit
Ethernet, Myrinet, or InfiniBand switches. Through hierarchical construction
using a SAN, LAN, or WAN, one can build scalable clusters with an increasing
number of nodes. The cluster is connected to the Internet via a virtual private
network (VPN) gateway. The gateway IP address locates the cluster. The system
image of a computer is decided by the way the OS manages the shared cluster
resources. Most clusters have loosely coupled node computers. All resources of
a server node are managed by their own OS. Thus, most clusters have multiple
system images as a result of having many autonomous nodes under different OS
control.
1.2
Single-System Image
Greg Pfister [38] has
indicated that an ideal cluster should merge multiple system images into a single-system image (SSI). Cluster designers desire a cluster operating system or some middle-ware to
support SSI at various levels, including the sharing of CPUs, memory, and I/O
across all cluster nodes. An SSI is an illusion created by software or hardware
that presents a collection of resources as one integrated, powerful resource.
SSI makes the cluster appear like a single machine to the user. A cluster with
multiple system images is nothing but a collection of inde-pendent computers.
1.3
Hardware, Software, and Middleware Support
In Chapter 2, we will discuss
cluster design principles for both small and large clusters. Clusters exploring
massive parallelism are commonly known as MPPs. Almost all HPC clusters in the
Top 500 list are also MPPs. The building blocks are computer nodes (PCs, workstations,
servers, or SMP), special communication software such as PVM or MPI, and a
network interface card in each computer node. Most clusters run under the Linux
OS. The computer nodes are interconnected by a high-bandwidth network (such as
Gigabit Ethernet, Myrinet, InfiniBand, etc.).
Special
cluster middleware supports are needed to create SSI or high availability (HA). Both sequential and
parallel applications can run on the cluster, and special parallel environments
are needed to facilitate use of the cluster resources. For example, distributed
memory has multiple images. Users may want all distributed memory to be shared
by all servers by forming distribu-ted
shared memory (DSM). Many SSI features are expensive or difficult to achieve at
various cluster operational levels.
Instead of achieving SSI, many clusters are loosely coupled machines. Using
virtualization, one can build many virtual clusters dynamically, upon user
demand. We will discuss virtual clusters in Chapter 3 and the use of virtual
clusters for cloud computing in Chapters 4, 5, 6, and 9.
1.4
Major Cluster Design Issues
Unfortunately, a cluster-wide
OS for complete resource sharing is not available yet. Middleware or OS
extensions were developed at the user space to achieve SSI at selected
functional levels. Without this middleware, cluster nodes cannot work together
effectively to achieve cooperative computing. The software environments and
applications must rely on the middleware to achieve high performance. The
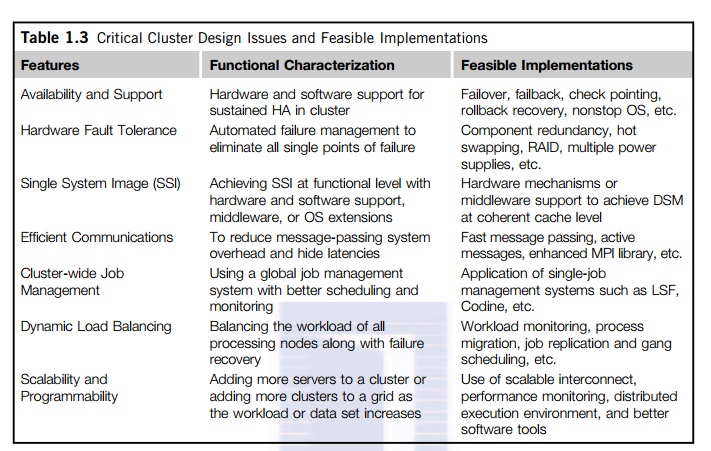
cluster benefits come from scalable performance, efficient message passing,
high system availability, seamless fault tolerance, and cluster-wide job
management, as summarized in Table 1.3. We will address these issues in Chapter
2.
2. Grid Computing Infrastructures
In the past 30 years, users
have experienced a natural growth path from Internet to web and grid computing
services. Internet services such as the Telnet command enables a local computer to connect
to a remote computer. A web service such as HTTP enables remote access of
remote web pages. Grid computing is envisioned to allow close interaction among
applications running on distant computers simultaneously. Forbes Magazine has projected the global growth of the
IT-based economy from $1 trillion in 2001 to $20 trillion by 2015. The
evolution from Internet to web and grid services is certainly playing a major
role in this growth.
2.1
Computational Grids
Like an electric utility
power grid, a computing
grid offers
an infrastructure that couples computers, software/middleware, special
instruments, and people and sensors together. The grid is often con-structed
across LAN, WAN, or Internet backbone networks at a regional, national, or
global scale. Enterprises or organizations present grids as integrated
computing resources. They can also be viewed as virtual platforms to support virtual organizations. The computers used in a
grid are pri-marily workstations, servers, clusters, and supercomputers.
Personal computers, laptops, and PDAs can be used as access devices to a grid
system.
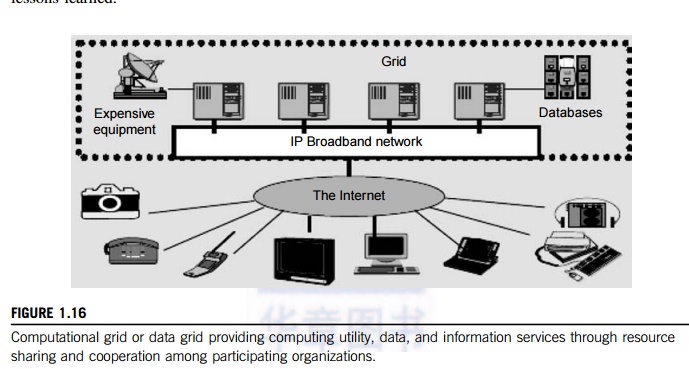
Figure
1.16 shows an example computational grid built over multiple resource sites
owned by different organizations. The resource sites offer complementary
computing resources, including workstations, large servers, a mesh of
processors, and Linux clusters to satisfy a chain of computational needs. The
grid is built across various IP broadband networks including LANs and WANs
already used by enterprises or organizations over the Internet. The grid is
presented to users as an integrated resource pool as shown in the upper half of
the figure.
Special instruments may be
involved such as using the radio telescope in SETI@Home search of life in the
galaxy and the austrophysics@Swineburne for pulsars. At the server end, the
grid is a network. At the client end, we see wired or wireless terminal
devices. The grid integrates the computing, communication, contents, and
transactions as rented services. Enterprises and consumers form the user base,
which then defines the usage trends and service characteristics. Many national
and international grids will be reported in Chapter 7, the NSF TeraGrid in US,
EGEE in Europe, and ChinaGrid in China for various distributed scientific grid
applications.
2.2
Grid Families
Grid technology demands new
distributed computing models, software/middleware support, network protocols,
and hardware infrastructures. National grid projects are followed by industrial
grid plat-form development by IBM, Microsoft, Sun, HP, Dell, Cisco, EMC,
Platform Computing, and others. New grid service providers (GSPs) and new grid
applications have emerged rapidly, similar to the growth of Internet and web
services in the past two decades. In Table 1.4, grid systems are classified in
essentially two categories: computational
or data grids and P2P
grids.
Computing or data grids are built primarily at the national level. In Chapter
7, we will cover grid applications and lessons learned.

3. Peer-to-Peer Network Families
An example of a well-established
distributed system is the client-server
architecture. In this sce-nario, client machines (PCs and workstations) are
connected to a central server for compute, e-mail, file access, and database
applications. The P2P
architecture offers a distributed model of networked systems. First, a P2P
network is client-oriented instead of server-oriented. In this section, P2P
sys-tems are introduced at the physical level and overlay networks at the
logical level.
3.1
P2P Systems
In a P2P system, every node
acts as both a client and a server, providing part of the system resources.
Peer machines are simply client computers connected to the Internet. All client
machines act autonomously to join or leave the system freely. This implies that
no master-slave relationship exists among the peers. No central coordination or
central database is needed. In other words, no peer machine has a global view
of the entire P2P system. The system is self-organizing with distributed
control.
Figure
1.17 shows the architecture of a P2P network at two abstraction levels.
Initially, the peers are totally unrelated. Each peer machine joins or leaves
the P2P network voluntarily. Only the participating peers form the physical network at any time. Unlike the cluster or grid, a P2P
network does not use a dedicated interconnection network. The physical network
is simply an ad hoc network formed at various Internet domains randomly using
the TCP/IP and NAI protocols. Thus, the physical network varies in size and
topology dynamically due to the free membership in the P2P network.
3.2
Overlay Networks
Data items or files are
distributed in the participating peers. Based on communication or file-sharing
needs, the peer IDs form an overlay
network at the logical level. This overlay is a virtual network
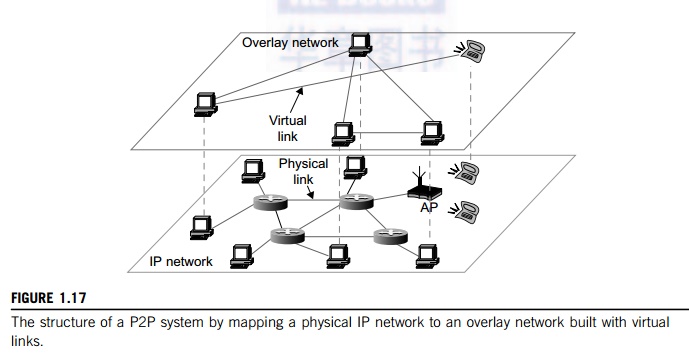
formed by mapping each
physical machine with its ID, logically, through a virtual mapping as shown in
Figure 1.17. When a new peer joins the system, its peer ID is added as a node
in the overlay network. When an existing peer leaves the system, its peer ID is
removed from the overlay network automatically. Therefore, it is the P2P
overlay network that characterizes the logical connectivity among the peers.
There
are two types of overlay networks: unstructured and structured. An unstructured overlay network is characterized by a random graph. There is no
fixed route to send messages or files among the nodes. Often, flooding is applied to
send a query to all nodes in an unstructured overlay, thus resulting in heavy
network traffic and nondeterministic search results. Structured overlay net-works follow certain connectivity
topology and rules for inserting and removing nodes (peer IDs) from the overlay graph. Routing mechanisms are
developed to take advantage of the structured overlays.
3.3
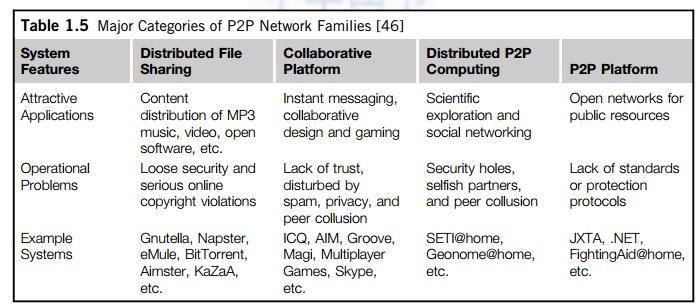
P2P Application Families
Based on application, P2P
networks are classified into four groups, as shown in Table 1.5. The first
family is for distributed file sharing of digital contents (music, videos,
etc.) on the P2P network. This includes many popular P2P networks such as
Gnutella, Napster, and BitTorrent, among others. Colla-boration P2P networks
include MSN or Skype chatting, instant messaging, and collaborative design,
among others. The third family is for distributed P2P computing in specific
applications. For example, SETI@home provides 25 Tflops of distributed
computing power, collectively, over 3 million Internet host machines. Other P2P
platforms, such as JXTA, .NET, and FightingAID@home, support naming, discovery,
communication, security, and resource aggregation in some P2P applications. We
will dis-cuss these topics in more detail in Chapters 8 and 9.
3.4
P2P Computing Challenges
P2P computing faces three
types of heterogeneity problems in hardware, software, and network
requirements. There are too many hardware models and architectures to select
from; incompatibility exists between software and the OS; and different
network connections and protocols
make it too complex to apply
in real applications. We need system scalability as the workload increases.
System scaling is directly related to performance and bandwidth. P2P networks
do have these properties. Data location is also important to affect collective
performance. Data locality, network proximity, and interoperability are three
design objectives in distributed P2P applications.
P2P performance is affected by routing efficiency and
self-organization by participating peers. Fault tolerance, failure management,
and load balancing are other important issues in using overlay networks. Lack
of trust among peers poses another problem. Peers are strangers to one another.
Security, privacy, and copyright violations are major worries by those in the
industry in terms of applying P2P technology in business applications [35]. In
a P2P network, all clients provide resources including computing power, storage
space, and I/O bandwidth. The distributed nature of P2P net-works also increases
robustness, because limited peer failures do not form a single point of
failure.
By replicating data in multiple peers, one can easily lose data in
failed nodes. On the other hand, disadvantages of P2P networks do exist.
Because the system is not centralized, managing it is difficult. In addition,
the system lacks security. Anyone can log on to the system and cause damage or
abuse. Further, all client computers connected to a P2P network cannot be
considered reliable or virus-free. In summary, P2P networks are reliable for a
small number of peer nodes. They are only useful for applica-tions that require
a low level of security and have no concern for data sensitivity. We will
discuss P2P networks in Chapter 8, and extending P2P technology to social networking
in Chapter 9.
4. Cloud Computing over the Internet
Gordon Bell, Jim Gray, and
Alex Szalay [5] have advocated: “Computational science is changing to be
data-intensive. Supercomputers must be balanced systems, not just CPU farms but also petascale I/O and
networking arrays.” In the future, working with large data sets
will typically mean sending the computations (programs) to the data, rather
than copying the data to the workstations. This reflects the trend in IT of
moving computing and data from desktops to large data centers, where there is
on-demand provision of software, hardware, and data as a service. This data
explosion has promoted the idea of cloud computing.
Cloud computing has been defined differently by
many users and designers. For example, IBM, a major player in cloud computing,
has defined it as follows: “A cloud is a pool of
virtualized computer
resources. A cloud can host a variety of
different workloads, including batch-style backend jobs and interactive and
user-facing applications.” Based on this definition, a cloud allows workloads to be deployed and scaled out quickly through rapid provisioning of
virtual or physical machines. The cloud supports redundant, self-recovering,
highly scalable programming models that allow workloads to recover from many
unavoidable hardware/software failures. Finally, the cloud system should be
able to monitor resource use in real time to enable rebalancing of allocations
when needed.
4.1
Internet Clouds
Cloud computing applies a
virtualized platform with elastic resources on demand by provisioning hardware,
software, and data sets dynamically (see Figure 1.18). The idea is to move
desktop computing to a service-oriented platform using server clusters and huge
databases at data centers. Cloud computing leverages its low cost and
simplicity to benefit both users and providers. Machine virtualization has
enabled such cost-effectiveness. Cloud computing intends to satisfy many user
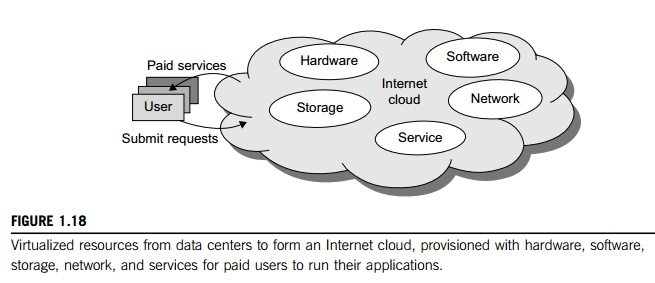
applications simultaneously.
The cloud ecosystem must be designed to be secure, trustworthy, and dependable.
Some computer users think of the cloud as a centralized resource pool. Others
consider the cloud to be a server cluster which practices distributed computing
over all the servers used.
4.2
The Cloud Landscape
Traditionally, a distributed
computing system tends to be owned and operated by an autonomous administrative
domain (e.g., a research laboratory or company) for on-premises computing
needs. However, these traditional systems have encountered several performance
bottlenecks: constant system maintenance, poor utilization, and increasing
costs associated with hardware/software upgrades. Cloud computing as an
on-demand computing paradigm resolves or relieves us from these problems.
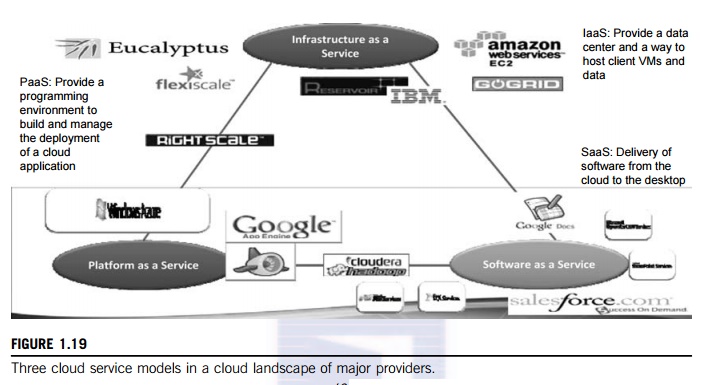
Figure 1.19 depicts the cloud landscape and major cloud players, based on three
cloud service models. Chapters 4, 6, and 9 provide details regarding these
cloud service offerings. Chapter 3 covers the relevant virtualization tools.
• Infrastructure as a Service
(IaaS) This model puts together infrastructures demanded by users—namely servers, storage, networks, and the data
center fabric. The user can deploy and run on multiple VMs running guest OSes
on specific applications. The user does not manage or control the underlying
cloud infrastructure, but can specify when to request and release the needed
resources.
• Platform as a Service (PaaS)
This model enables the user to deploy user-built applications onto a
virtualized cloud platform. PaaS includes middleware, databases, development
tools, and some runtime support such as Web 2.0 and Java. The platform includes
both hardware and software integrated with specific programming interfaces. The
provider supplies the API and software tools (e.g., Java, Python, Web 2.0,
.NET). The user is freed from managing the cloud infrastructure.
• Software as a Service (SaaS)
This refers to browser-initiated application software over thousands of paid
cloud customers. The SaaS model applies to business processes, industry
applications, consumer
relationship management (CRM), enterprise resources planning (ERP), human resources (HR), and collaborative
applications. On the customer side, there is no upfront investment in servers or software licensing. On
the provider side, costs are rather low, compared with conventional hosting of
user applications.
Internet clouds offer four deployment modes: private, public, managed, and hybrid [11]. These modes demand different levels of
security implications. The different SLAs imply that the security
responsibility is shared among all the cloud providers, the cloud resource
consumers, and the third-party cloud-enabled software providers. Advantages of
cloud computing have been advocated by many IT experts, industry leaders, and
computer science researchers.
In Chapter 4, we will describe major cloud platforms that have been
built and various cloud services offerings. The following list highlights eight
reasons to adapt the cloud for upgraded Internet applications and web services:
1. Desired location in areas
with protected space and higher energy efficiency
2. Sharing of peak-load capacity
among a large pool of users, improving overall utilization
3. Separation of infrastructure
maintenance duties from domain-specific application development
4. Significant reduction in
cloud computing cost, compared with traditional computing paradigms
5. Cloud computing programming
and application development
6. Service and data discovery
and content/service distribution
7. Privacy, security, copyright,
and reliability issues
8. Service agreements, business
models, and pricing policies
Related Topics