Chapter: Advanced Computer Architecture : Instruction Level Parallelism
Dynamic Scheduling
Dynamic Scheduling
Overcoming Data Hazards with Dynamic Scheduling:
The
Dynamic Scheduling is used handle some cases when dependences are unknown at a
compile time. In which the hardware rearranges the instruction execution to
reduce the stalls while maintaining data flow and exception behavior.
It also
allows code that was compiled with one pipeline in mind to run efficiently on a
different pipeline. Although a dynamically scheduled processor cannot change
the data flow, it tries to avoid stalling when dependences, which could
generate hazards, are present.
Dynamic Scheduling:
A major
limitation of the simple pipelining techniques is that they all use in-order
instruction issue and execution: Instructions are issued in program order and
if an instruction is stalled in the pipeline, no later instructions can
proceed. Thus, if there is a dependence between two closely spaced instructions
in the pipeline, this will lead to a hazard and a stall. If there are multiple
functional units, these units could lie idle. If instruction j depends on a
long-running instruction i, currently in execution in the pipeline, then all
instructions after j must be stalled until i is finished and j can execute.
For
example, consider this code:
DIV.D F0,F2,F4
ADD.D F10,
F0, F8
SUB.D F12, F8,
F14
Out-of-order
execution introduces the possibility of WAR and WAW hazards, which do not exist
in the five-stage integer pipeline and its logical extension to an in-order
floating-point pipeline.
Out-of-order
completion also creates major complications in handling exceptions. Dynamic
scheduling with out-of-order completion must preserve exception behavior in the
sense that exactly those exceptions that would arise if the program were
executed in strict program order actually do arise.
Imprecise
exceptions can occur because of two possibilities:
1. The
pipeline may have already completed instructions that are later in program
order than the instruction causing the exception, and
2. The
pipeline may have not yet completed some instructions that are earlier in
program order than the instruction causing the exception.
To allow
out-of-order execution, we essentially split the ID pipe stage of our simple
five-stage pipeline into two stages:
1. Issue—Decode instructions, check for structural
hazards.
2. Read operands—Wait until no data hazards, then read
operands.
In a
dynamically scheduled pipeline, all instructions pass through the issue stage
in order (inorder issue); however, they can be stalled or bypass each other in
the second stage (read operands) and thus enter execution out of order.
Score-boarding
is a technique for allowing instructions to execute out-of-order when there are
sufficient resources and no data dependences; it is named after the CDC 6600
scoreboard, which developed this capability. We focus on a more sophisticated
technique, called Tomasulo’s algorithm that has several major enhancements over
scoreboarding.
1. Dynamic Scheduling Using
Tomasulo’s Approach :
This
scheme was invented by RobertTomasulo, and was first used in the IBM 360/91. it
uses register renaming to eliminate output and anti-dependencies, i.e. WAW and
WAR hazards. Output and anti-dependencies are just name dependencies; there is
no actual data dependence
Tomasulo's
algorithm implements register renaming through the use of what are called
reservation stations. Reservation stations are buffers which fetch and store
instruction operands as soon as they are available.
In
addition, pending instructions designate the reservation station that will
provide their input. Finally, when successive writes to a register overlap in
execution, only the last one is actually used to update the register. As
instructions are issued, the register specifies for pending operands are
renamed to the names of the reservation station, which provides register
renaming.
The basic
structure of a Tomasulo-based MIPS processor, including both the floating-point
unit and the load/store unit.
Instructions
are sent from the instruction unit into the instruction queue from which they
are issued in FIFO order.
The
reservation stations include the operation and the actual operands, as well as
information used for detecting and resolving hazards. Load buffers have three functions:
hold the components of the effective address until it is computed, track
outstanding loads that are waiting on the memory, and hold the results of
completed loads that are waiting for the CDB.
Similarly, store buffers have three functions: hold
the components of the effective until it is computed, hold the destination
memory addresses of outstanding stores that are waiting for the data value to
store, and hold the address and value to store until the memory unit is
available.
All
results from either the FP units or the load unit are put on the CDB, which
goes to the FP register file as well as to the reservation stations and store
buffers. The FP adders implement addition and subtraction, and the FP
multipliers do multiplication and division.
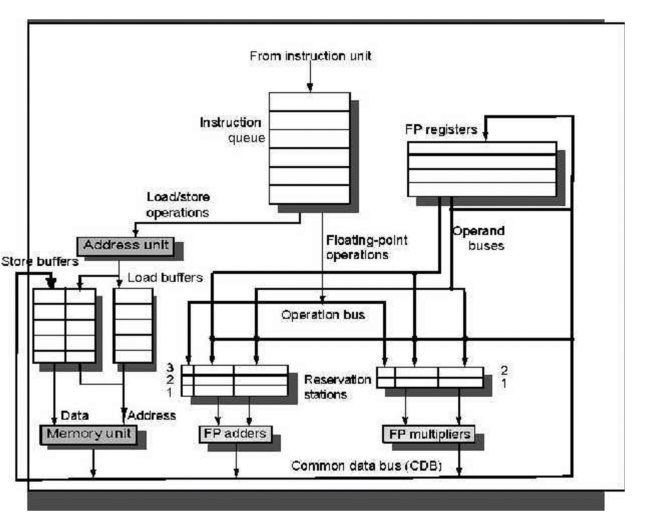
FIGURE 1.1 The basic structure of
a MIPS floating point unit using Tomasulo’s algorithm.
There are
only three steps in Tomasulo’s Aprroach :
Issue—Get the next instruction from the head of the
instruction queue. If there is a matching reservation station that is empty,
issue the instruction to the station with the operand values (renames
registers)
2. Execute (EX) — When all the operands are
available, place into the corresponding reservation stations for execution. If
operands are not yet available, monitor the common data bus (CDB) while waiting
for it to be computed.
3. Write result (WB)—When the
result is available, write it on the CDB and from there into the registers and
into any reservation stations (including store buffers) waiting for this
result. Stores also write data to memory during this step: When both the
address and data value are available, they are sent to the memory unit and the
store completes.
Each
reservation station has six fields:
Ø Op—The
operation to perform on source operands S1 and S2.
Ø Qj,
Qk—The reservation stations that will produce the corresponding source operand;
a value of zero indicates that the source operand is already available in Vj or
Vk, or is unnecessary.
Ø Vj,
Vk—The value of the source operands. Note that only one of the V field or the Q
field is valid for each operand. For loads, the Vk field is used to the offset
from the instruction.
Ø A–used to
hold information for the memory address calculation for a load or store.
Ø Busy—Indicates
that this reservation station and its accompanying functional unit are
occupied.
Related Topics