Chapter: Fundamentals of Database Systems : Introduction to Databases : Database System Concepts and Architecture
Classification of Database Management Systems
Classification of Database Management Systems
Several criteria are normally used to classify DBMSs. The first is the data model on which the DBMS is based.
The main data model used in many current commercial DBMSs is the relational data model. The object data model has been implemented
in some commercial systems but has not had widespread use. Many legacy
applications still run on database systems based on the hierarchical and network
data models. Examples of
hierarchical DBMSs include IMS (IBM) and some other sys-tems like System 2K
(SAS Inc.) and TDMS. IMS is still used at governmental and industrial
installations, including hospitals and banks, although many of its users have
converted to relational systems. The network data model was used by many vendors
and the resulting products like IDMS (Cullinet—now Computer Associates), DMS
1100 (Univac—now Unisys), IMAGE (Hewlett-Packard), VAX-DBMS (Digital—then
Compaq and now HP), and SUPRA (Cincom) still have a fol-lowing and their user
groups have their own active organizations. If we add IBM’s popular VSAM file
system to these, we can easily say that a reasonable percentage of
worldwide-computerized data is still in these so-called legacy database systems.
The relational DBMSs are evolving continuously, and, in particular, have
been incorporating many of the concepts that were developed in object
databases. This has led to a new class of DBMSs called object-relational DBMSs. We can categorize DBMSs based on the data
model: relational, object, object-relational, hierarchical, network, and other.
More recently, some experimental DBMSs are based on the XML (eXtended
Markup Language) model, which is a tree-structured (hierarchical) data model.
These have been called native XML DBMSs.
Several commercial relational DBMSs have added XML interfaces and storage to
their products.
The second criterion used to classify DBMSs is the number of users supported by the system. Single-user systems support only one user at a time and are mostly
used with PCs. Multiuser systems,
which include the majority of DBMSs, support con-current multiple users.
The third criterion is the number
of sites over which the database is distributed. A DBMS is centralized if the data is stored at a
single computer site. A centralized DBMS can support multiple users, but the
DBMS and the database reside totally at a single computer site. A distributed DBMS (DDBMS) can have the
actual database and DBMS software distributed over many sites, connected by a
computer network. Homogeneous DDBMSs
use the same DBMS software at all the sites, whereas heterogeneous DDBMSs can use different DBMS software at each site.
It is also possible to develop middleware software to access several
autonomous preexisting databases stored under heterogeneousDBMSs. This leads to
a federated DBMS (or multidatabase system), in which the
participating DBMSs are loosely coupled and
have a degree of local autonomy. Many DDBMSs use client-server
architecture, as we described in Section 2.5.
The fourth criterion is cost. It is difficult to propose a
classification of DBMSs based on cost. Today we have open source (free) DBMS
products like MySQL and PostgreSQL that are supported by third-party vendors
with additional services. The main RDBMS products are available as free examination
30-day copy versions as well as personal versions, which may cost under $100
and allow a fair amount of functionality. The giant systems are being sold in
modular form with components to handle distribution, replication, parallel
processing, mobile capability, and so on, and with a large number of parameters
that must be defined for the configuration. Furthermore, they are sold in the
form of licenses—site licenses allow unlimited use of the database system with
any number of copies running at the customer site. Another type of license
limits the number of concurrent users or the number of user seats at a
location. Standalone single user versions of some systems like Microsoft Access
are sold per copy or included in the overall configuration of a desktop or
laptop. In addition, data warehousing and mining features, as well as support
for additional data types, are made available at extra cost. It is possible to
pay millions of dollars for the installation and maintenance of large database
sys-tems annually.
We can also classify a DBMS on the basis of the types of access path options for storing files. One well-known
family of DBMSs is based on inverted file structures. Finally, a DBMS can be general purpose or special purpose. When performance is a primary consideration, a
special-purpose DBMS can be designed and built for a specific application; such
a system cannot be used for other applications without major changes. Many
airline reservations and telephone directory systems devel-oped in the past are
special-purpose DBMSs. These fall into the category of online transaction
processing (OLTP) systems, which
must support a large number of concurrent
transactions without imposing excessive delays.
Let us briefly elaborate on the main criterion for classifying DBMSs:
the data model. The basic relational
data model represents a database as a collection of tables, where each
table can be stored as a separate file. The database in Figure 1.2 resem-bles a
relational representation. Most relational databases use the high-level query
language called SQL and support a limited form of user views. We discuss the
rela-tional model and its languages and operations in Chapters 3 through 6, and
tech-niques for programming relational applications in Chapters 13 and 14.
The object data model defines
a database in terms of objects, their properties, and their operations. Objects
with the same structure and behavior belong to a class, and classes are organized into hierarchies (or acyclic
graphs). The operations of each class are specified in terms of predefined
procedures called methods.
Relational DBMSs have been extending their models to incorporate object
database concepts and other capabilities; these systems are referred to as object-relational or extended relational systems. We discuss
object databases and object-relational systems in Chapter 11.
The XML model has emerged as
a standard for exchanging data over the Web, and has been used as a basis for
implementing several prototype native XML systems. XML uses hierarchical tree
structures. It combines database concepts with concepts from document
representation models. Data is represented as elements; with the use of tags,
data can be nested to create complex hierarchical structures. This model
conceptually resembles the object model but uses different terminology. XML
capabilities have been added to many commercial DBMS products. We present an
overview of XML in Chapter 12.
Two older, historically important data models, now known as legacy data models, are the network and
hierarchical models. The network model
represents data as record types and also represents a limited type of 1:N
relationship, called a set type. A
1:N, or one-to-many, relationship relates one instance of a record to many
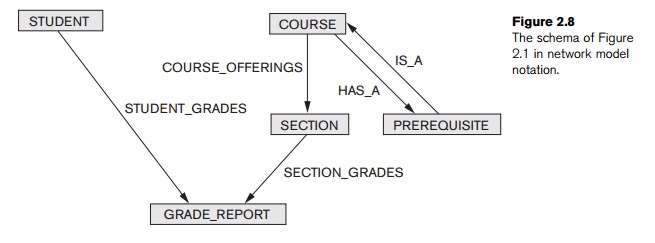
record instances using some pointer linking mechanism in these models. Figure
2.8 shows a network schema diagram for the database of Figure 2.1, where record
types are shown as rectangles and set types are shown as labeled directed
arrows.
The network model, also known as the CODASYL DBTG model, has an associated
record-at-a-time language that must be embedded in a host programming
lan-guage. The network DML was proposed in the 1971 Database Task Group (DBTG)
Report as an extension of the COBOL language. It provides commands for locating
records directly (e.g., FIND ANY <record-type> USING <field-list>, or FIND DUPLICATE <record-type> USING <field-list>). It has commands to support traversals within
set-types (e.g., GET
OWNER, GET {FIRST, NEXT, LAST} MEMBER WITHIN
<set-type> WHERE <condition>).
It also has commands to store new data
(e.g., STORE <record-type>) and to make it part of a set type (e.g., CONNECT <record-type> TO <set-type>). The language
also handles many additional considerations, such as the currency of record
types and set types, which are defined by the current position of the
navigation process within the database. It is prominently used by IDMS, IMAGE,
and SUPRA DBMSs today.
The hierarchical model
represents data as hierarchical tree structures. Each hierar-chy represents a
number of related records. There is no standard language for the hierarchical
model. A popular hierarchical DML is DL/1 of the IMS system. It dominated the
DBMS market for over 20 years between 1965 and 1985 and is still a widely used
DBMS worldwide, holding a large percentage of data in governmental, health
care, and banking and insurance databases. Its DML, called DL/1, was a de facto
industry standard for a long time. DL/1 has commands to locate a record (e.g., GET { UNIQUE, NEXT} <record-type> WHERE <condition>). It has
navigational
facilities to navigate within hierarchies (e.g., GET NEXT WITHIN PARENT or GET {FIRST,
NEXT} PATH <hierarchical-path-specification> WHERE <condition>). It has appropriate
facilities to store and update records (e.g., INSERT
<record-type>, REPLACE <record-type>). Currency
issues during navigation are also handled with additional
features in the language.
Related Topics