Chapter: Fundamentals of Database Systems : Introduction to Databases : Database System Concepts and Architecture
Centralized and Client/Server Architectures for DBMSs
Centralized and Client/Server Architectures for DBMSs
1. Centralized DBMSs
Architecture
Architectures for DBMSs have followed trends similar to those for
general computer system architectures. Earlier architectures used mainframe
computers to provide the main processing for all system functions, including
user application programs and user interface programs, as well as all the DBMS
functionality. The reason was that most users accessed such systems via
computer terminals that did not have processing power and only provided
display capabilities. Therefore, all processing was performed remotely on the
computer system, and only display information and controls were sent from the
computer to the display terminals, which were connected to the central
computer via various types of communications networks.
As prices of hardware declined, most users replaced their terminals with
PCs and workstations. At first, database systems used these computers similarly
to how they had used display terminals, so that the DBMS itself was still a centralized DBMS in which all the DBMS
functionality, application program execution, and user inter-face processing
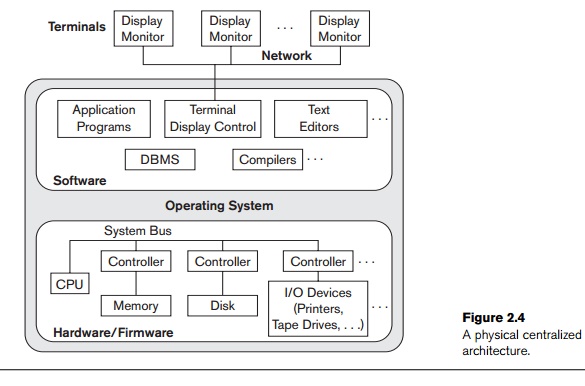
were carried out on one machine. Figure 2.4 illustrates the physical components
in a centralized architecture. Gradually, DBMS systems started to exploit the
available processing power at the user side, which led to client/server DBMS
architectures.
2. Basic Client/Server Architectures
First, we discuss client/server
architecture in general, then we see how it is applied to DBMSs. The client/server architecture was
developed to deal with computing environments in which a large number of PCs,
workstations, file servers, printers, database servers,
Web
servers, e-mail servers, and other software and equipment are connected via a
network. The idea is to define specialized
servers with specific functionalities. For example, it is possible to
connect a number of PCs or small workstations as clients to a file server that maintains the files of
the client machines. Another machine can be designated as a printer server by being connected to
various printers; all print requests by the clients are forwarded to this
machine. Web servers or e-mail servers also
fall into the specialized server category. The resources provided by specialized servers can be accessed by many client
machines. The client machines provide the user with the
appropriate interfaces to utilize these servers, as well as with local processing power to run local applications.
This concept can be carried over to other software packages, with specialized
programs—such as a CAD (computer-aided design) package—being stored on specific
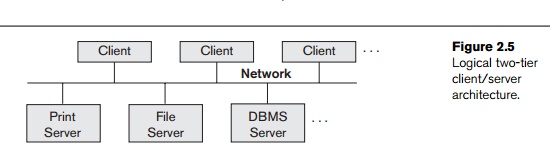
server machines and being made accessible to multiple clients. Figure 2.5
illustrates client/server architecture at the logical level; Figure 2.6 is a
simplified diagram that shows the physical architecture. Some machines would be
client sites only (for example, diskless work-stations or workstations/PCs with
disks that have only client software installed).
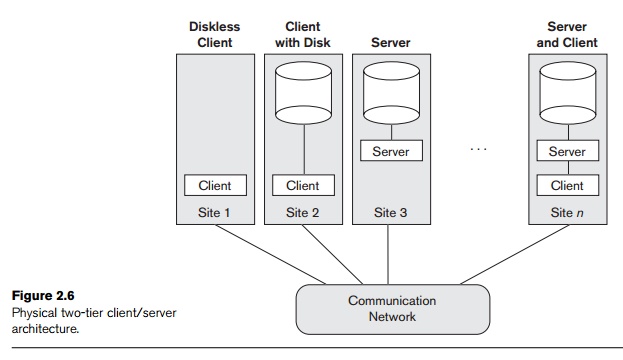
Other machines would be dedicated servers, and others would have both
client and server functionality.
The concept of client/server architecture assumes an underlying
framework that consists of many PCs and workstations as well as a smaller
number of mainframe machines, connected via LANs and other types of computer
networks. A client in this framework
is typically a user machine that provides user interface capabilities and local
processing. When a client requires access to additional functionality— such as
database access—that does not exist at that machine, it connects to a server
that provides the needed functionality. A server
is a system containing both hard-ware and software that can provide services to
the client machines, such as file access, printing, archiving, or database
access. In general, some machines install only client software, others only
server software, and still others may include both client and server software,
as illustrated in Figure 2.6. However, it is more common that client and server
software usually run on separate machines. Two main types of basic DBMS
architectures were created on this underlying client/server framework: two-tier and three-tier.13 We discuss them next.
3. Two-Tier
Client/Server Architectures for DBMSs
In relational database management systems (RDBMSs), many of which
started as centralized systems, the system components that were first moved to
the client side were the user interface and application programs. Because SQL
(see Chapters 4 and 5) provided a standard language for RDBMSs, this created a
logical dividing point between client and server. Hence, the query and
transaction functionality related to SQL processing remained on the server
side. In such an architecture, the server is often called a query server or transaction server because it provides these two functionalities.
In an RDBMS, the server is also often called an SQL server.
The user interface programs and application programs can run on the
client side. When DBMS access is required, the program establishes a connection
to the DBMS (which is on the server side); once the connection is created, the
client program can communicate with the DBMS. A standard called Open Database Connectivity
(ODBC) provides an application programming interface (API), which allows client-side programs
to call the DBMS, as long as both client and server machines have the necessary
software installed. Most DBMS vendors provide ODBC drivers for their systems. A
client program can actually connect to several RDBMSs and send query and
transaction requests using the ODBC API, which are then processed at the server
sites. Any query results are sent back to the client program, which can process
and display the results as needed. A related standard for the Java programming
language, called JDBC, has also been
defined. This allows Java client programs to access one or more DBMSs through a
standard interface.
The different approach to two-tier client/server architecture was taken
by some object-oriented DBMSs, where the software modules of the DBMS were
divided between client and server in a more integrated way. For example, the server level may include the part of
the DBMS software responsible for handling data storage on disk pages, local
concurrency control and recovery, buffering and caching of disk pages, and
other such functions. Meanwhile, the client
level may handle the user interface; data dictionary functions; DBMS
interactions with programming language compilers; global query optimization,
concurrency control, and recovery across multiple servers; structuring of
complex objects from the data in the buffers; and other such functions. In this
approach, the client/server interaction is more tightly coupled and is done
internally by the DBMS modules—some of which reside on the client and some on
the server—rather than by the users/programmers. The exact division of
functionality can vary from system to system. In such a client/server
architecture, the server has been called a data
server because it provides data in disk pages to the client. This data can
then be structured into objects for the client programs by the client-side DBMS
software.
The architectures described here are called two-tier architectures because the soft-ware components are
distributed over two systems: client and server. The advan-tages of this
architecture are its simplicity and seamless compatibility with existing
systems. The emergence of the Web changed the roles of clients and servers,
leading to the three-tier architecture.
4. Three-Tier and n-Tier Architectures for Web
Applications
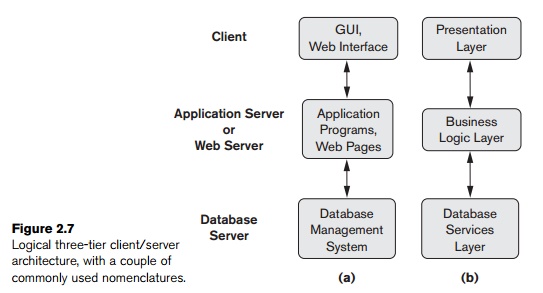
Many Web applications use an architecture called the three-tier architecture, which adds an
intermediate layer between the client and the database server, as illustrated
in Figure 2.7(a).
This intermediate layer or middle
tier is called the application
server or the Web server, depending on the application.
This server plays an intermediary role by run-ning application programs and
storing business rules (procedures or constraints) that are used to access data
from the database server. It can also improve database security by checking a
client’s credentials before forwarding a request to the data-base server. Clients
contain GUI interfaces and some additional application-specific business rules.
The intermediate server accepts requests from the client, processes the request
and sends database queries and commands to the database server, and then acts
as a conduit for passing (partially) processed data from the database server to
the clients, where it may be processed further and filtered to be presented to
users in GUI format. Thus, the user
interface, application rules, and data
access act as the three tiers. Figure 2.7(b) shows another architecture
used by database and other application package vendors. The presentation layer
displays information to the user and allows data entry. The business logic
layer handles intermediate rules and constraints before data is passed up to
the user or down to the DBMS. The bottom layer includes all data management
services. The middle layer can also act as a Web server, which retrieves query
results from the database server and formats them into dynamic Web pages that
are viewed by the Web browser at the client side.
Other architectures have also been proposed. It is possible to divide
the layers between the user and the stored data further into finer components,
thereby giving rise to n-tier
architectures, where n may be four or
five tiers. Typically, the business logic layer is divided into multiple
layers. Besides distributing programming and data throughout a network, n-tier applications afford the advantage
that any one tier can run on an appropriate processor or operating system
platform and can be handled independently. Vendors of ERP (enterprise resource
planning) and CRM (customer relationship management) packages often use a middleware layer, which accounts for the
front-end modules (clients) communicating with a number of back-end databases
(servers).
Advances in encryption and decryption technology make it safer to
transfer sensitive data from server to client in encrypted form, where it will
be decrypted. The latter can be done by the hardware or by advanced software.
This technology gives higher levels of data security, but the network security
issues remain a major concern. Various technologies for data compression also
help to transfer large amounts of data from servers to clients over wired and
wireless networks.
Related Topics