Chapter: Fundamentals of Database Systems : Introduction to Databases : Database System Concepts and Architecture
Data Models, Schemas, and Instances
Data Models, Schemas, and Instances
One fundamental characteristic of the database approach is that it
provides some level of data abstraction. Data
abstraction generally refers to the suppression of details of data
organization and storage, and the highlighting of the essential features for
an improved understanding of data. One of the main characteristics of the
database approach is to support data abstraction so that different users can
perceive data at their preferred level of detail. A data model—a collection of concepts that can be used to describe
the structure of a database—provides the necessary means to achieve this
abstraction. By structure of a database we
mean the data types, relationships, and constraints that apply to the data.
Most data models also include a set of basic
operations for specifying retrievals and updates on the database.
In addition to the basic operations provided by the data model, it is
becoming more common to include concepts in the data model to specify the dynamic aspect or behavior of a database application. This allows the database designer
to specify a set of valid
user-defined operations that are allowed on the database objects. An example of a user-defined
operation could be COMPUTE_GPA, which can be applied to a STUDENT object. On the other hand, generic operations to insert, delete, modify,
or retrieve any kind of object are often included in the basic data model operations. Concepts to
specify behavior are fundamental to object-oriented data models (see Chapter
11) but are also being incorporated in more traditional data models. For
example, object-relational models (see Chapter 11) extend the basic relational
model to include such concepts, among others. In the basic relational data
model, there is a provision to attach behavior to the relations in the form of
persistent stored modules, popularly known as stored procedures (see Chapter
13).
1. Categories of Data
Models
Many data models have been proposed, which we can categorize according
to the types of concepts they use to describe the database structure. High-level or conceptual data models provide concepts that are close to the way
many users per-ceive data, whereas low-level
or physical data models provide
concepts that describe the details of how data is stored on the computer
storage media, typically magnetic disks. Concepts provided by low-level data
models are generally meant for computer specialists, not for end users. Between
these two extremes is a class of representational
(or implementation) data models, which provide concepts that may be easily understood by end users
but that are not too far removed from the way data is organized in computer
storage. Representational data models hide many details of data storage on disk
but can be implemented on a computer system directly.
Conceptual data models use concepts such as entities, attributes, and
relationships. An entity represents
a real-world object or concept, such as an employee or a project from the
miniworld that is described in the database. An attribute represents some property of interest that further describes
an entity, such as the employee’s name or salary. A relationship among two or more entities represents an association
among the entities, for example, a works-on relationship between an employee
and a project. Chapter 7 presents the Entity-Relationship
model—a popular high-level conceptual data model. Chapter 8 describes
additional abstractions used for advanced modeling, such as generalization,
specialization, and categories (union types).
Representational or implementation data models are the models used most
fre-quently in traditional commercial DBMSs. These include the widely used relational data model, as well as the so-called legacy data models—the network and hierarchical models—that have been widely used in the past. Part 2
is devoted to the relational data
model, and its constraints, operations and languages.5 The SQL standard for relational
databases is described in Chapters 4 and 5. Representational data models
represent data by using record structures and hence are sometimes called record-based data models.
We can regard the object data
model as an example of a new family of higher-level implementation data
models that are closer to conceptual data models. A standard for object
databases called the ODMG object model has been proposed by the Object Data
Management Group (ODMG). We describe the general characteristics of object
databases and the object model proposed standard in Chapter 11. Object data
models are also frequently utilized as high-level conceptual models,
particu-larly in the software engineering domain.
Physical data models describe how data is stored as files in the
computer by repre-senting information such as record formats, record orderings,
and access paths. An access path is
a structure that makes the search for particular database records effi-cient.
We discuss physical storage techniques and access structures in Chapters 17 and
18. An index is an example of an
access path that allows direct access to data using an index term or a keyword.
It is similar to the index at the end of this book, except that it may be
organized in a linear, hierarchical (tree-structured), or some other fashion.
2. Schemas, Instances,
and Database State
In any data model, it is important to distinguish between the description of the data-base and the database itself. The description of a
database is called the database schema, which is specified during
database design and is not expected to change frequently. Most data models have certain conventions for displaying schemas as
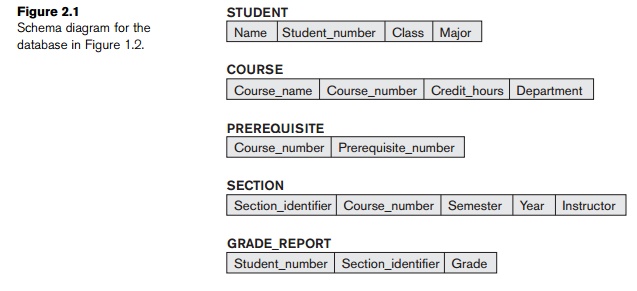
diagrams. A displayed schema is called a schema
diagram. Figure 2.1 shows a schema diagram for the database shown in Figure
1.2; the diagram displays the structure of each record type but not the actual
instances of records. We call each object in the schema—such as STUDENT or COURSE—a schema construct.
A schema diagram displays only some
aspects of a schema, such as the names of record types and data items, and
some types of constraints. Other aspects are not specified in the schema
diagram; for example, Figure 2.1 shows neither the data type of each data item,
nor the relationships among the various files. Many types of con-straints are
not represented in schema diagrams. A constraint such as students majoring in computer
science must take CS1310 before the end of their sophomore year is quite
difficult to represent diagrammatically.
The actual data in a database may change quite frequently. For example,
the data-base shown in Figure 1.2 changes every time we add a new student or
enter a new grade. The data in the database at a particular moment in time is
called a database state or snapshot. It is also called the current set of occurrences or instances in
the
database. In a given database state, each schema construct has its own current set of instances; for example,
the STUDENT construct will contain the set of individual student entities (records)
as its instances. Many database states can be constructed to correspond to a
particular database schema. Every time we insert or delete a record or change
the value of a data item in a record, we change one state of the database into
another state.
The distinction between database schema and database state is very
important. When we define a new
database, we specify its database schema only to the DBMS. At this point, the
corresponding database state is the empty
state with no data. We get the initial
state of the database when the database is first populated or loaded with
the initial data. From then on, every time an update operation is applied to
the database, we get another database state. At any point in time, the database
has a current state.8 The DBMS is partly responsible
for ensuring that every state of the database
is a valid state—that is, a state
that satisfies the structure and constraints specified in the schema. Hence,
specifying a correct schema to the DBMS is extremely important and the schema
must be designed with utmost care. The DBMS stores the descriptions of the
schema constructs and constraints—also called the meta-data—in the DBMS catalog so that DBMS software can refer to
the schema whenever it needs to. The schema is sometimes called the intension, and a database state is
called an extension of the schema.
Although, as mentioned earlier, the schema is not supposed to change
frequently, it is not uncommon that changes occasionally need to be applied to
the schema as the application requirements change. For example, we may decide
that another data item needs to be stored for each record in a file, such as
adding the Date_of_birth to the STUDENT schema
in Figure 2.1. This is known as schema
evolution. Most mod-ern DBMSs include some operations for schema evolution
that can be applied while the database is operational.
Related Topics