Chapter: Fundamentals of Database Systems : Introduction to Databases : Database System Concepts and Architecture
Three-Schema Architecture and Data Independence
Three-Schema Architecture and Data Independence
Three of the four important characteristics of the database approach,
listed in Section 1.3, are (1) use of a catalog to store the database
description (schema) so as to make it self-describing, (2) insulation of
programs and data (program-data and program-operation independence), and (3)
support of multiple user views. In this section we specify an architecture for
database systems, called the three-schema
architecture,9 that was proposed to help achieve
and visualize these characteristics. Then
we discuss the concept of data independence further.
1. The Three-Schema
Architecture
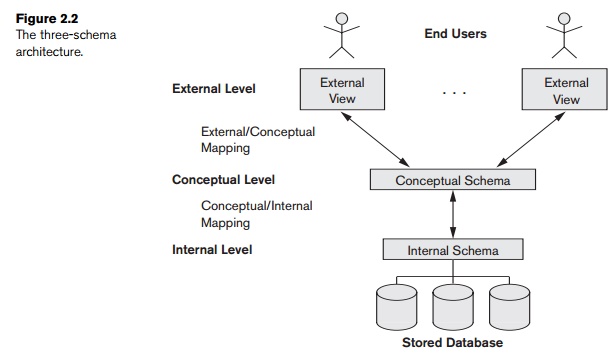
The goal of the three-schema architecture, illustrated in Figure 2.2, is
to separate the user applications from the physical database. In this
architecture, schemas can be defined at the following three levels:
The internal level has an internal
schema, which describes the physical stor-age structure of the database.
The internal schema uses a physical data model and describes the complete
details of data storage and access paths for the database.
The conceptual level has a conceptual
schema, which describes the structure of the whole database for a
community of users. The conceptual schema hides the details of physical storage
structures and concentrates on describing entities, data types, relationships,
user operations, and constraints. Usually, a representational data model is
used to describe the conceptual schema when a database system is implemented.
This implementation conceptual schema is
often based on a conceptual schema design
in a high-level data model.
The external or view level includes a number of external schemas or user views. Each external schema describes the part of the database that
a particular user group is interested in and hides the rest of the database
from that user group. As in the previous level, each external schema is
typically implemented using a representational data model, possibly based on
an external schema design in a high-level data model.
The three-schema architecture is a convenient tool with which the user
can visualize the schema levels in a database system. Most DBMSs do not
separate the three levels completely and explicitly, but support the
three-schema architecture to some extent. Some older DBMSs may include
physical-level details in the conceptual schema. The three-level ANSI
architecture has an important place in database technology development because
it clearly separates the users’ external level, the database’s con-ceptual
level, and the internal storage level for designing a database. It is very much
applicable in the design of DBMSs, even today. In most DBMSs that support user
views, external schemas are specified in the same data model that describes the
conceptual-level information (for example, a relational DBMS like Oracle uses
SQL for this). Some DBMSs allow different data models to be used at the
conceptual and external levels. An example is Universal Data Base (UDB), a DBMS
from IBM, which uses the relational model to describe the conceptual schema,
but may use an object-oriented model to describe an external schema.
Notice that the three schemas are only descriptions of data; the stored data that actually exists is at the physical level only. In a DBMS based on
the three-schema architecture, each
user group refers to its own external schema. Hence, the DBMS must transform a
request specified on an external schema into a request against the conceptual
schema, and then into a request on the internal schema for processing over the
stored database. If the request is a database retrieval, the data extracted
from the stored database must be reformatted to match the user’s external view.
The processes of transforming requests and results between levels are called mappings. These mappings may be
time-consuming, so some DBMSs—especially those that are meant to support small
databases—do not support external views. Even in such systems, however, a
certain amount of mapping is necessary to transform requests between the
conceptual and internal levels.
2. Data Independence
The three-schema architecture can be used to further explain the concept
of data independence, which can be defined as the capacity to change the
schema at one level of a database
system without having to change the schema at the next higher level. We can define
two types of data independence:
Logical data independence is the
capacity to change the conceptual schema
without having to change external schemas or application programs. We may
change the conceptual schema to expand the database (by adding a record type or
data item), to change constraints, or to reduce the database (by removing a
record type or data item). In the last case, external schemas that refer only
to the remaining data should not be affected. For example, the external schema
of Figure 1.5(a) should not be affected by changing the GRADE_REPORT file (or record type) shown in Figure 1.2 into the one shown in Figure 1.6(a). Only the view definition and the mappings need
to be changed in a DBMS that supports logical data independence. After the
conceptual schema undergoes a logical reorganization, application pro-grams
that reference the external schema constructs must work as before.
Changes to constraints can be applied to the conceptual schema without
affecting the external schemas or application programs.
Physical data independence is the
capacity to change the internal schema without
having to change the conceptual schema. Hence, the external schemas need not be
changed as well. Changes to the internal schema may be needed because some physical
files were reorganized—for example, by creating additional access
structures—to improve the performance of retrieval or update. If the same data
as before remains in the database, we should not have to change the conceptual
schema. For example, providing an access path to improve retrieval speed of
section records (Figure 1.2) by semester and year should not require a query
such as list all sections offered in fall
2008 to be changed, although the query would be executed more efficiently
by the DBMS by utilizing the new access path.
Generally, physical data independence exists in most databases and file
environments where physical details such as the exact location of data on
disk, and hard-ware details of storage encoding, placement, compression, splitting,
merging of records, and so on are hidden from the user. Applications remain
unaware of these details. On the other hand, logical data independence is
harder to achieve because it allows structural and constraint changes without
affecting application programs—a much stricter requirement.
Whenever we have a multiple-level DBMS, its catalog must be expanded to
include information on how to map requests and data among the various levels.
The DBMS uses additional software to accomplish these mappings by referring to
the mapping information in the catalog. Data independence occurs because when
the schema is changed at some level, the schema at the next higher level
remains unchanged; only the mapping
between the two levels is changed. Hence, application programs refer-ring to
the higher-level schema need not be changed.
The three-schema architecture can make it easier to achieve true data
independence, both physical and logical. However, the two levels of mappings
create an overhead during compilation or execution of a query or program,
leading to inefficiencies in the DBMS. Because of this, few DBMSs have
implemented the full three-schema architecture.
Related Topics