Chapter: Fundamentals of Database Systems : Introduction to Databases : Database System Concepts and Architecture
The Database System Environment
The Database System Environment
A DBMS is a complex software system. In this section we discuss the
types of soft-ware components that constitute a DBMS and the types of computer
system soft-ware with which the DBMS interacts.
1. DBMS Component
Modules
Figure 2.3 illustrates, in a simplified form, the typical DBMS
components. The fig-ure is divided into two parts. The top part of the figure
refers to the various users of the database environment and their interfaces.
The lower part shows the internals of the DBMS responsible for storage of data
and processing of transactions.
The database and the DBMS catalog are usually stored on disk. Access to
the disk is controlled primarily by the operating
system (OS), which schedules disk
read/write. Many DBMSs have their own buffer
management module to schedule disk read/write, because this has a
considerable effect on performance. Reducing disk read/write improves
performance considerably. A higher-level stored
data manager module of the DBMS
controls access to DBMS information that is stored on disk, whether it is part of the database or the catalog.
Let us consider the top part of Figure 2.3 first. It shows interfaces
for the DBA staff, casual users who work with interactive interfaces to
formulate queries, application programmers who create programs using some host
programming languages, and parametric users who do data entry work by supplying
parameters to predefined transactions. The DBA staff works on defining the
database and tuning it by making changes to its definition using the DDL and
other privileged commands.
The DDL compiler processes schema definitions, specified in the DDL, and
stores descriptions of the schemas (meta-data) in the DBMS catalog. The catalog
includes information such as the names and sizes of files, names and data types
of data items, storage details of each file, mapping information among schemas,
and constraints. In addition, the catalog stores many other types of
information that are needed by the DBMS modules, which can then look up the
catalog information as needed.
Casual users and persons with
occasional need for information from the database interact using some form of
interface, which we call the interactive
query interface in Figure 2.3. We have not explicitly shown any menu-based
or form-based interac-tion that may be used to generate the interactive query
automatically. These queries are parsed and validated for correctness of the
query syntax, the names of files and
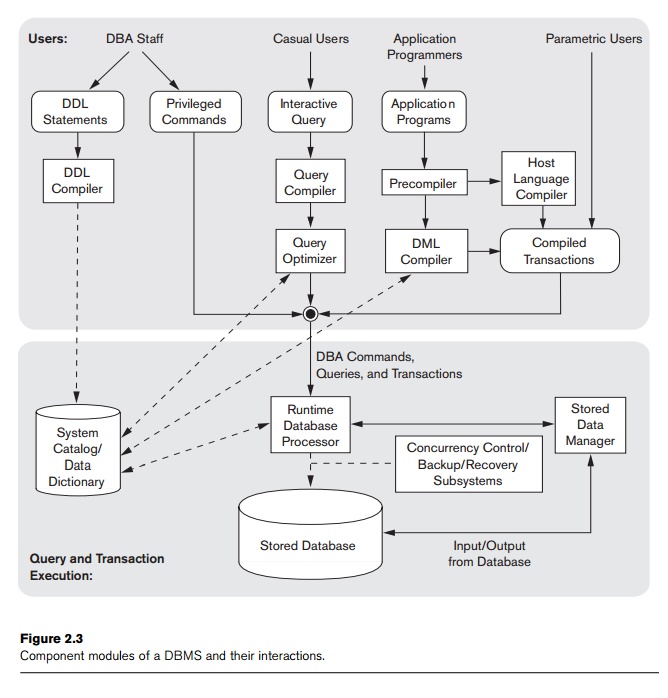
data elements, and so on by a query compiler that compiles them into
an internal form. This internal query is subjected to query optimization
(discussed in Chapters 19 and 20). Among other things, the query optimizer is concerned with the rearrangement and possible
reordering of operations, elimination of redundancies, and use of correct
algorithms and indexes during execution. It consults the system catalog for
statistical and other physical information about the stored data and generates
executable code that performs the necessary operations for the query and makes
calls on the runtime processor.
Application programmers write
programs in host languages such as Java, C, or C++ that are submitted to a
precompiler. The precompiler
extracts DML commands from an application program written in a host programming
language. These commands are sent to the DML compiler for compilation into
object code for database access. The rest of the program is sent to the host
language compiler. The object codes for the DML commands and the rest of the
program are linked, forming a canned transaction whose executable code includes
calls to the runtime database processor. Canned transactions are executed
repeatedly by parametric users, who simply supply the parameters to the
transactions. Each execution is considered to be a separate transaction. An
example is a bank withdrawal transaction where the account number and the
amount may be supplied as parameters.
In the lower part of Figure 2.3,
the runtime database processor
executes (1) the privileged commands, (2) the executable query plans, and (3)
the canned transactions with runtime parameters. It works with the system catalog and may update it with
statistics. It also works with the stored
data manager, which in turn uses basic operating system services for
carrying out low-level input/output (read/write) operations between the disk
and main memory. The runtime database processor handles other aspects of data
transfer, such as management of buffers in the main memory. Some DBMSs have
their own buffer management module while others depend on the OS for buffer
management. We have shown concurrency
control and backup and recovery
systems separately as a module in this figure. They are integrated into the
working of the runtime database processor for purposes of transaction
management.
It is now common to have the client program that accesses the DBMS
running on a separate computer from the computer on which the database resides.
The former is called the client computer
running a DBMS client software and the latter is called the database server. In some cases, the
client accesses a middle computer, called the application server, which in turn accesses the database server. We
elaborate on this topic in Section
2.5.
Figure 2.3 is not meant to
describe a specific DBMS; rather, it illustrates typical DBMS modules. The DBMS
interacts with the operating system when disk accesses—to the database or to
the catalog—are needed. If the computer system is shared by many users, the OS
will schedule DBMS disk access requests and DBMS processing along with other
processes. On the other hand, if the computer system is mainly dedicated to
running the database server, the DBMS will control main memory buffering of
disk pages. The DBMS also interfaces with compilers for general-purpose host
programming languages, and with application servers and client programs running
on separate machines through the system network interface.
2. Database System Utilities
In addition to possessing the
software modules just described, most DBMSs have database utilities that help the DBA manage the database system.
Common utilities have the following
types of functions:
Loading. A loading utility is used to load existing data files—such as text files or sequential files—into the
database. Usually, the current (source) for mat of the data file and the
desired (target) database file structure are specified to the utility, which
then automatically reformats the data and stores it in the database. With the
proliferation of DBMSs, transferring data from one DBMS to another is becoming
common in many organizations. Some vendors are offering products that generate
the appropriate loading programs, given the existing source and target database
storage descriptions (internal schemas). Such tools are also called conversion tools. For the hierarchical
DBMS called IMS (IBM) and for many network DBMSs including IDMS (Computer
Associates), SUPRA (Cincom), and IMAGE (HP), the vendors or third-party
companies are making a variety of conversion tools available (e.g., Cincom’s
SUPRA Server SQL) to transform data into the relational model.
Backup. A backup utility creates a backup
copy of the database, usually by dumping
the entire database onto tape or other mass storage medium. The backup copy can
be used to restore the database in case of catastrophic disk failure.
Incremental backups are also often used, where only changes since the previous
backup are recorded. Incremental backup is more complex, but saves storage
space.
Database storage reorganization. This
utility can be used to reorganize a set of
database files into different file organizations, and create new access paths
to improve performance.
Performance monitoring. Such a
utility monitors database usage and provides statistics to the DBA. The DBA
uses the statistics in making decisions such as whether or not to reorganize
files or whether to add or drop indexes to improve performance.
Other utilities may be available for sorting files, handling data
compression, monitoring access by users, interfacing with the network, and
performing other functions.
3. Tools, Application Environments, and Communications Facilities
Other tools are often available
to database designers, users, and the DBMS. CASE tools are used in the design phase of
database systems. Another tool that can be quite useful in large organizations
is an expanded data dictionary (or data repository) system. In addition to storing catalog information about schemas
and constraints, the data dictionary stores other information, such as design
decisions, usage standards, application program descriptions, and user
information. Such a system is also called an information repository. This information can be accessed directly by users or the DBA when
needed. A data dictionary utility is similar to the DBMS catalog, but it includes a wider variety of information and
is accessed mainly by users rather than by the DBMS software.
Application development
environments, such as PowerBuilder (Sybase)
or JBuilder (Borland), have been
quite popular. These systems provide an environment for developing database
applications and include facilities that help in many facets of database
systems, including database design, GUI development, querying and updating, and
application program development.
The DBMS also needs to interface with communications software, whose function is to allow users at
locations remote from the database system site to access the data-base through
computer terminals, workstations, or personal computers. These are connected to
the database site through data communications hardware such as Internet
routers, phone lines, long-haul networks, local networks, or satellite
communication devices. Many commercial database systems have communication
packages that work with the DBMS. The integrated DBMS and data communications
system is called a DB/DC system. In
addition, some distributed DBMSs are physically distributed over multiple
machines. In this case, communications net-works are needed to connect the
machines. These are often local area
networks (LANs), but they can
also be other types of networks.
Related Topics