Chapter: Advanced Computer Architecture : Multiple Issue Processors
VLIW Approach
VLIW
Approach
The compiler may be required to ensure that
dependences within the issue packet cannot be present or, at a minimum,
indicate when a dependence may be present.
The first multiple-issue processors that required
the instruction stream to be explicitly organized to avoid dependences. This
architectural approach was named VLIW, standing for Very Long Instruction Word,
and denoting that the instructions, since they contained several instructions,
were very wide (64 to 128 bits, or more).
The basic architectural concepts and compiler technology
are the same whether multiple operations are organized into a single
instruction, or whether a set of instructions in an issue packet is
preconfigured by a compiler to exclude dependent operations (since the issue
packet can be thought of as a very large instruction). Early VLIWs were quite
rigid in their instruction formats and effectively required recompilation of
programs for different versions of the hardware.
VLIWs use multiple, independent functional units.
Rather than attempting to issue multiple, independent instructions to the
units, a VLIW packages the multiple operations into one very long instruction,
or requires that the instructions in the issue packet satisfy the s a m e c o n
s t r a i n t s . we will assume that multiple operations are placed in one
instruction, as in the original VLIW approach. Since the burden for choosing
the instructions to be issued simultaneously falls on the compiler, the
hardware in a superscalar to make these issue decisions is unneeded.
Since this advantage of a VLIW increases as the
maximum issue rate grows, we focus on a wider-issue processor. Indeed, for
simple two issue processors, the overhead of a superscalar is probably minimal.
Because VLIW approaches make sense for wider processors, we choose to focus our
example on such architecture.
For example, a VLIW processor might have
instructions that contain five operations, including: one integer operation
(which could also be a branch), two floating-point operations, and two memory
references. The instruction would have a set of fields for each functional
unit— perhaps 16 to 24 bits per unit, yielding an instruction length of between
112 and 168 bits.
To keep the functional units busy, there must be
enough parallelism in a code sequence to fill the available operation slots.
This parallelism is uncovered by unrolling loops and scheduling the code within
the single larger loop body. If the unrolling generates straighline code, then
local scheduling techniques, which operate on a single basic block, can be used.
If finding and exploiting the parallelism requires scheduling code across
branches, a substantially more complex global scheduling algorithm must be
used.
Global
scheduling algorithms are not only more complex in structure, but they must
deal with significantly more complicated tradeoffs in optimization, since
moving code across branches is expensive. Trace scheduling is one of these
global scheduling techniques developed specifically for VLIWs.
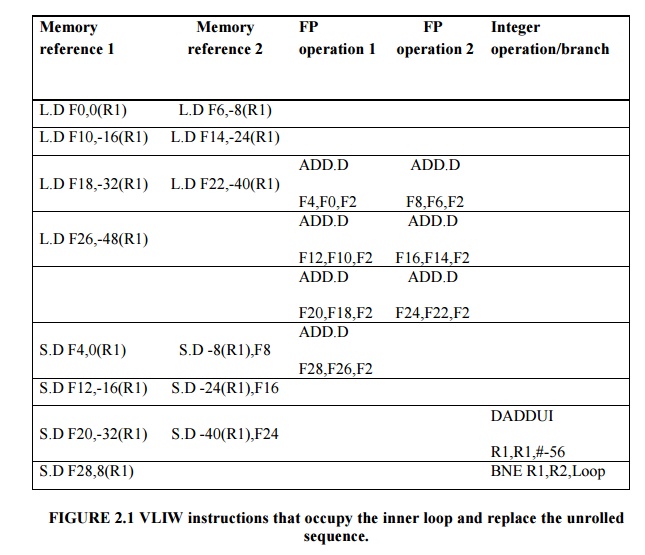
Suppose we have a VLIW that could issue two memory
references, two FP operations, and one integer operation or branch in every
clock cycle. Show an unrolled version of the loop x[i] = x[i] +s (see page 223
for the MIPS ode) for such a processor. Unroll as many times as necessary to
eliminate any stalls. Ignore the branch-delay slot.
The code is shown in Figure 2.1.The loop has been
unrolled to make seven copies of the body, which eliminates all stalls (i.e.,
completely empty issue cycles), and runs in 9 cycles. This code yields a
running rate of seven results in 9 cycles, or 1.29 cycles per result, nearly
twice as fast as the two-issue superscalar that used unrolled and scheduled
code.
For the
original VLIW model, there are both technical and logistical problems. The
technical problems are the increase in code size and the limitations of
lock-step operation. Two different elements combine to increase code size
substantially for a VLIW. First, generating enough operations in a
straight-line code fragment requires ambitiously unrolling loops (as earlier
examples) thereby increasing code size. Second, whenever instructions are not
full, the unused functional units translate to wasted bits in the instruction
encoding.
we saw
that only about 60% of the functional units were used, so almost half of each
instruction was empty. In most VLIWs, an instruction may need to be left
completely empty if no operations can be scheduled.
Early
VLIWs operated in lock-step; there was no hazard detection hardware at all.
This structure dictated that a stall in any functional unit pipeline must cause
the entire processor to stall, since all the functional units must be kept
synchronized. Although a compiler may be able to schedule the deterministic
functional units to prevent stalls, predicting which data accesses will
encounter a cache stall and scheduling them is very difficult.
Hence,
caches needed to be blocking and to cause all the functional units to stall. As
the issue rate and number of memory references becomes large, this
synchronization restriction becomes unacceptable. In more recent processors,
the functional units operate more independently, and the compiler is used to
avoid hazards at issue time, while hardware checks allow for unsynchronized
execution once instructions are issued.
Binary
code compatibility has also been a major logistical problem for VLIWs. In a
strict VLIW approach, the code sequence makes use of both the instruction set
definition and the detailed pipeline structure, including both functional units
and their latencies.
One possible
solution to this migration problem and the problem of binary code compatibility
in general, is object-code translation or emulation. This technology is
developing quickly and could play a significant role in future migration
schemes. Another approach is to temper the strictness of the approach so that
binary compatibility is still feasible. This later approach is used in the
IA-64 architecture.
The major challenge for all multiple-issue
processors is to try to exploit large amounts of ILP. When the parallelism
comes from unrolling simple loops in FP programs, the original loop probably
could have been run efficiently on a vector processor.
Related Topics