Chapter: Multicore Application Programming For Windows, Linux, and Oracle Solaris : Coding for Performance
Using Libraries to Structure Applications
Using Libraries to
Structure Applications
Libraries are the usual mechanism for structuring applications as they
become larger. There are some good technical reasons to use libraries:
n Common
functionality can be extracted into a library that can be shared between
different projects or applications. This can lead to better code reuse, more
efficient
use of developer
time, and more effective use of memory and disk space.
n Placing
functionality into libraries can lead to more convenient upgrades where only
the library is upgraded instead of replacing all the executables that use the
library.
n Libraries
can provide better separation between interface and implementation. The
implementation details of the library can be hidden from the users, allowing
the implementation of the library to evolve while maintaining a consistent
interface.
n Stratifying
functionality into libraries according to frequency of use can improve
application start-up time and memory footprint by loading only the libraries
that are needed. Functionality can be loaded on demand rather than setting up
all pos-sible features when the application starts.
n Libraries
can be used as a mechanism to dynamically provide enhanced functional-ity. The
functionality can be made available without having to change or even restart
the application.
n Libraries
can enable functionality to be selected based on the runtime environ-ment or
characteristics of the system. For instance, an application may load differ-ent
optimized libraries depending on the underlying hardware or select libraries at
runtime depending on the type of work it is being asked to perform.
On the
other hand, there are some nontechnical reasons why functionality gets placed
into libraries. These reasons may represent the wrong choice for the user.
n Libraries
often represent a convenient product for an organizational unit. One group of
developers might be responsible for a particular library of code, but that does
not automatically imply that a single library represents the best way for that
code to be delivered to the end users.
n Libraries
are also used to group related functionality. For example, an application might
contain a library of string-handling functions. Such a library might be
appropriate if it contains a large body of code. On the other hand, if it
contains only a few small routines, it might be more appropriate to combine it
with another library.
There is
a strong attraction to breaking applications down into a set of libraries.
Libraries make sense for all the reasons outlined previously, but it is quite
possible to have either inappropriate splits of functionality or libraries that
implement too little functionality.
There are
costs associated with libraries. A call into a function provided by a library
will typically be more costly than a call into a function that is in the main
executable. Code provided in a library may also have more overhead than code
provided in the exe-cutable. There are a few contributors to cost:
n Library
calls may be implemented using a table of function addresses. This table may be
a list of addresses for the routines included in a library. A library routine
calls
into this table, which then jumps to the actual code for the routine.
n Each
library and its data are typically placed onto new TLB entries. Calls into a
library will usually also result in an ITLB miss and possibly a DTLB miss if
the code accesses library-specific data.
n If the
library is being lazy loaded (that is, loaded into memory on demand), there
will be costs associated with disk access and setting up the addresses of the
library functions in memory.
n Unix
platforms typically provide libraries as position-independent code. This
enables the same library to be shared in memory between multiple running
appli-cations. The cost of this is an increase in code length. Windows makes
the opposite trade-off; it uses position-dependent code in libraries, reducing
the opportunity of sharing libraries between running applications but producing
slightly faster code.
Listing 2.9 shows code for two trivial libraries
that can be used to examine how memory is laid out at runtime.
Listing 2.9 Defining
Two Libraries
$ more liba.c
#include <stdio.h>
void ina()
{
printf( "In library A\n" );
}
$ more libb.c
#include <stdio.h>
void inb()
{
printf( "In library B\n" );
}
Listing 2.10 shows the process of compiling these
two libraries on Solaris.
Listing 2.10 Compiling
Two Libraries
$ cc -G -Kpic -o liba.so liba.c
$ cc -G -Kpic -o libb.so libb.c
The compiler flag -G tells the compiler to make a library, while the flag -Kpic tells the compiler to use position-independent code. The advantage of
position-independent code is that the library can reside at any location in
memory. The same library can even be shared between multiple applications and
have each application map it at a different address.
The main program shown in Listing 2.11 will call
the code in liba.so and then
pause so we can examine the memory layout of the application.
Listing 2.11 Calling
Library Code
$
more libmain.c
#include
<unistd.h>
void ina(); void inb();
void
main()
{
ina();
sleep(20);
}
$
cc libmain.c -L. -R. -la –lb
The compile command in Listing 2.11 builds the main
executable. The flag -L tells the linker where to find
the library at link time. The flag -R tells the runtime linker where to locate the file at runtime. In the
example, these two flags are set to the current directory. The application will
link and execute only if the current directory does con-tain the library.
However, other approaches are more resilient. Running this application enables
us to look at the memory map using the utility pmap. Listing 2.12 shows the memory map.
Listing 2.12 Memory
Map of Application and Libraries on Solaris
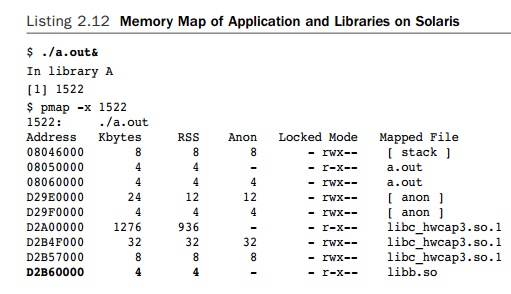

In the
memory map shown in Listing 2.12, each library has at least two mapped
seg-ments. The first is mapped with read and execute permissions that contain
the code in the library. The second contains data and is mapped with read,
write, and execute per-missions. Both libraries are mapped in, even though the
code does not contain any calls to libb.so and makes no use of the library.
The RSS column
indicates that the library has been loaded into memory. The x86 processor uses
a 4KB default page size, so pages of memory are allocated in 4KB chunks.
Although both liba.so and libb.so contain only a few bytes of
code, both libraries are allocated 4KB of memory for instructions. The same is
true for data. The concern is that each 4KB will require a single TLB entry for
a virtual address to physical address mapping when a routine in that page is
called. If liba.so
and libb.so had been
combined, the functions in the two libraries could have been placed into a single 4KB
segment for each of the instructions and data.
It is
possible to look at the sequence of events when the application is loaded by
set-ting the environment variable LD_DEBUG=flags. Listing 2.13 shows an edited
form of the output.
Listing 2.13 Output
from Setting the Environment Variable LD_DEBUG=files
$ LD_DEBUG=files ./a.out
01615: file=/export/home/darryl/a.out [ ELF ]; generating link map
01615: file=a.out; analyzing
01615:
file=liba.so; needed by
a.out
01615: file=./liba.so [ ELF ];
generating link map
01615:
file=libb.so; needed by
a.out
01615: file=./libb.so [ ELF ];
generating link map
01615:
file=libc.so.1; needed by
a.out
01615: file=/lib/libc.so.1 [
ELF ]; generating link map
01615: file=./liba.so; analyzing
01615: file=./libb.so; analyzing
01615: file=/lib/libc.so.1; analyzing
01615:
1: transferring control: a.out
This shows the sequence of starting the
application, having the runtime linker exam-ine the application, and
identifying the need for the libraries liba.so, libb.so, and libc.so.1. Once those libraries are loaded, it examines them for other libraries
that might be needed.
The linker performs a sizable amount of work.
However, the time spent processing the libraries is likely to be dominated by
the time spent fetching them from disk. The more data and instructions a
library contains, the more time it will take to read the library from disk. It
is possible to use lazy loading to avoid loading libraries from disk until they
are actually used. Listing 2.14 shows the application built with lazy loading
enabled and the resulting runtime linking.
Listing 2.14 Linking
a Library to Use Lazy Loading
$
cc libmain.c -L. -R. -z lazyload -la -lb
$
LD_DEBUG=files ./a.out
01712:
file=/export/home/darryl/a.out [ ELF ]; generating link map 01712: file=a.out;
analyzing
01712: file=libc.so.1; needed by a.out
01712: file=/lib/libc.so.1; analyzing 01712: 1:
transferring control: a.out
01712: 1: file=liba.so; lazy loading from file=a.out: symbol=ina
01712:
1: file=./liba.so [ ELF ]; generating link map 01712: 1: file=./liba.so;
analyzing
In
library A
In this instance, the application runs without
loading either liba.so or libb.so up until the point where the symbol ina() is required from the library liba.so. At that point, the runtime linker loads and processes the library. The
lazy loading of libraries has meant that the application did not need to load libb.so at all, thus reducing application start-up time.
One more thing to consider for the costs for libraries is the cost of
calling code resid-ing in libraries. The easiest way to demonstrate this is to
modify the example code so it calls the routine ina() twice and then to use the debugger to examine what happens at runtime.
The first call will load the library into memory, but that will happen only
once and can be ignored. The second time the routine is called will be
representative of all calls to all library routines. Listing 2.15 shows the
output from the Solaris Studio debug-ger, dbx, showing execution up until the first call to the routine ina().
Listing 2.15 Execution Until the First Call to the Routine ina
$ dbx a.out
Reading a.out
![]()
Reading ld.so.1 Reading libc.so.1 (dbx) stop in main
dbx: warning: 'main' has no debugger info
--will trigger on first instruction
(2) stop
in main
(dbx) run
Running: a.out (process id 1744)
stopped in main at 0x08050ab0 0x08050ab0: main :
pushl %ebp (dbx) nexti
stopped in main at 0x08050ab1 0x08050ab1: main+0x0001: movl %esp,%ebp
(dbx) nexti
stopped in main at 0x08050ab3
0x08050ab3:
main+0x0003: call ina [PLT] [
0x8050964, .-0x14f ]
At this stage, the application has reached the first call to the routine
ina(). As can
be seen from the disassembly, this call is actually a call to the procedure
linkage table (PLT). This table contains a jump to the actual start address of
the routine. However, the first time that the routine is called, the runtime
linker will have to load the lazily loaded library from disk. Listing 2.15
earlier skips this first call. Listing 2.16 shows the code as it steps through
the second call to the routine ina().
Listing 2.16 Jumping
Through the PLT to the Routine ina
(dbx) nexti
Reading liba.so
In library A
stopped in main at 0x08050ab8
0x08050ab8: main+0x0008: call ina
[PLT] [ 0x8050964, .-0x154 ]
(dbx) stepi
stopped in (unknown) at 0x08050964
0x08050964: ina [PLT]: jmp
*_GLOBAL_OFFSET_TABLE_+0x1c [ 0x8060b24 ] (dbx) stepi
stopped in
ina at 0xd2990510
0xd2990510:
ina : pushl %ebp
By the second time the call to ina() is encountered, the library has already been loaded, and the call is
again into the PLT. Using the debugger to step into the call, we can see that
this time the target is a jump instruction to the start of the routine.
All calls to library functions, possibly even those
within the library, will end up routed through the PLT. This imposes a small
overhead on every call. There are ways to limit the scope of library functions
so they are not visible outside the library and so calls within the library to
those functions will not need to be routed through the PLT.
The same procedure can be followed on Linux.
Listing 2.17 shows the steps necessary to compile the application on Linux.
Listing 2.17 Compiling
Libraries and Application on Linux
$ gcc
-shared -fpic -o liba.so liba.c $ gcc
-shared -fpic -o libb.so libb.c
$
gcc libmain.c `pwd`/liba.so
`pwd`/libb.so
Listing 2.18 shows the steps to use the Linux
debugger, gdb, to step through the process of
calling the library function ina().
Listing 2.18 Stepping
Through Library Call on Linux
$
gdb a.out
(gdb)
display /i $eip
(gdb)
break main
Breakpoint
1 at 0x8048502 (gdb) run
Starting program: /home/darryl/a.out Breakpoint 1,
0x08048502 in main () 0x8048502 <main+14>: sub $0x4,%esp (gdb) nexti
0x8048505
<main+17>: call 0x804841c <ina@plt>
(gdb)
nexti
In
library A
0x804850a
<main+22>: call 0x804841c <ina@plt>
(gdb)
stepi
0x804841c
<ina@plt>: jmp *0x804a008
(gdb)
stepi
0xb7ede42c
<ina>: push %ebp
The sequence for Linux shown in Listing 2.18 is
basically the same as the sequence for Solaris shown in Listing 2.15 and
Listing 2.16. The executable calls into the PLT, and then the application jumps
from there into the routine.
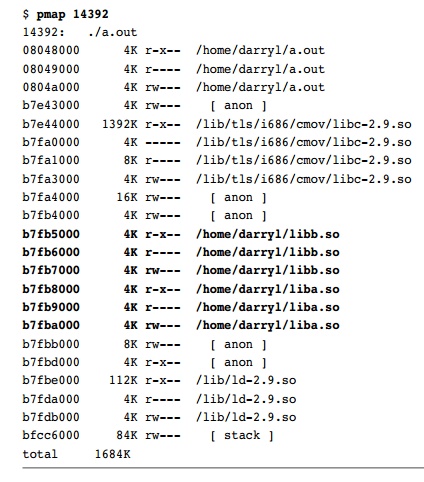
The memory map for Linux shown in Listing 2.19 looks very similar to the
memory map for Solaris shown in Listing 2.12. In the Linux memory map, both liba.so and libb.so are
mapped onto three 4KB pages.
Listing 2.19 Application Memory Map on Linux
Therefore, there is a balance between the convenience of the developers
of libraries and the convenience of the libraries’ users. Rough guidelines for
when to use libraries are as follows:
n Libraries make sense when they contain code that is rarely executed. If
a substan-tial amount of code does not need to be loaded from disk for the
general use of the application, then the load time of the application can be
reduced if this func-tionality is placed in a library that is loaded only when
needed.
It is useful to place code that is common to multiple applications into
shared libraries, particularly if the applications are out of the control of
the developers of the libraries. This is the situation with most operating
systems, where the applica-tions that use the libraries will be developed
separately from the core operating system. Most applications use libc, the C standard library, so it makes sense to deliver this library as a
shared library that all applications can use. If the internals of the operating
system change or if a bug is fixed, then the libraries can be modified without
needing to change the applications that use those libraries. This is a form of
encapsulation.
n Device drivers are usually packaged as libraries. There is a temptation
to produce multiple libraries, some of which are core and some of which are
device specific. If there is likely to only ever be a single device of a
specific type attached to a sys-tem, then it is better to provide a single
library. If there are likely to be multiple types of devices attached that all
share the common core, then it might be appro-priate to split the code into
device-specific and common code.
n Libraries can also provide dynamically loaded functionality. A library
could be released to provide an existing application with new functionality.
Placing as much functionality into as few libraries as possible is the most
efficient approach, but in many instances the need to dynamically manage
functionality will outweigh any overhead induced by packaging the functionality
as libraries.
In general, it is best to make libraries lazy
loaded when needed rather than have all the libraries load at start-up time.
This will improve the application start-up time. Listing 2.20 shows code for a
simple library that will be lazy loaded.
Listing 2.20 Simple
Library with Initialization Code
#include
<stdio.h>
void
initialise()
{
printf( "Initialisation code run\n" );
}
#pragma
init (initialise)
void
doStuff()
{
printf( "Doing stuff\n" );
}
The application shown in Listing 2.21 uses the
library from Listing 2.20.
Listing 2.21 Application
That Calls Library Code
#include <stdio.h> void doStuff(); void
main()
{
printf( "Application now running\n" ); doStuff();
printf( "Application now exiting\n" );
}
Listing 2.22 shows the results of
compiling, linking, and running this application on Solaris without lazy
loading.
Listing 2.22 Using
Library Code Without Lazy Loading
$ cc -O -G -o liba.so liba.c
$ cc -O -o main main.c -L.
-R. -la
$ ./main
Initialisation code run
Application now running
Doing stuff
Application
now exiting
Listing 2.23 shows the same test but with the
library being lazy loaded.
Listing 2.23 Using
Library Code with Lazy Loading
$ cc -O -G -o liba.so liba.c
$ cc -O -o main main.c -L. -R.
-zlazyload -la
$ ./main
Application now running
Initialisation code run
Doing stuff
Application
now exiting
This
change in the linking has enabled the library to be loaded after the
application has started. Therefore, the start-up time of the application is not
increased by having to load the library first. It is not a significant issue
for the example code, which uses one small library, but can be a significant
issue when multiple large libraries need to be loaded before the application
can start.
There is
one situation where libraries that are tagged as being lazy loaded are loaded
anyway. If an application needs to find a symbol and the application was not
explicitly linked with the library containing that object at compile time, then
the application will load all the dependent libraries in order to resolve any
unresolved symbols, undoing the usefulness of lazy loading. Suppose we add a
second library that prints the message “Library B initializing” when it is
loaded but contains no other code. Listing 2.24 shows the command line to
compile this library to have a lazy-loaded dependence on liba.
Listing 2.24 Compiling
libb to Have a Lazy-Loaded
Dependence on liba
$
cc -O -G -o libb.so libb.c -zlazyload
-R. -L. –la
The next step, shown in Listing 2.25, is to deliberately link the
application so that it lazy loads libb but does not have a dependence on liba. This would usually cause the linker to
fail with an unresolved symbol error, but we can switch that safety check off
using the -znodefs flag.
Listing 2.25 Compiling
the Application to Only Recode the Dependence on libb
$
cc -O -G -o main main.c -zlazyload
-znodefs -R. -L. –lb
The
resulting application contains an unresolved symbol for ina() but has a lazy-loaded dependence
on libb. When
the application is run, it will be unable to resolve the symbol ina(), so the runtime linker will
start loading all the lazy-loaded libraries. Once it has loaded libb, it will then lazy load the
dependencies of libb, where it will finally load liba and locate the routine ina(). Listing 2.26 shows the
resulting output.
Listing 2.26 Output Showing libb Being Lazy Loaded
as Part of Search for doStuff()
$
./main
Application
now running
Library
B initialising
Initialisation
code run
Doing
stuff
Application
now exiting
The other reason that lazy loading would be
unsuccessful is if the code is not opti-mally distributed between the
libraries. If each library requires code from another in order to work, then
there is no way that a subset can be loaded without pulling them all into the
application. Therefore, the distribution of code between the libraries is a critical
factor in managing the start-up time of an application.
Related Topics