Chapter: Multicore Application Programming For Windows, Linux, and Oracle Solaris : Coding for Performance
The Impact of Data Structures on Performance
The
Impact of Data Structures on Performance
Data structure is probably what most people think of first when they
hear the word structure within the
context of applications. Data structure is arguably the most critical structure in the program since each
data structure will potentially be accessed millions of times during the run of
an application. Even a slight gain in performance here can be magnified by the
number of accesses and become significant.
When an application needs an item of data, it fetches it from memory and
installs it in cache. The idea with caches is that data that is frequently
accessed will become resi-dent in the cache. The cost of fetching data from the
cache is substantially lower than the cost of fetching it from memory. Hence,
the application will spend less time waiting for frequently accessed data to be
retrieved from memory. It is important to realize that each fetch of an item of
data will also bring adjacent items into the caches. So, placing data that is
likely to be used at nearly the same time in close proximity will mean that
when one of the items of data is fetched, the related data is also fetched.
The amount of data loaded into each level of cache by a load instruction
depends on the size of the cache line. As discussed in “Using Caches to Hold
Recently Used Data” in Chapter 1, 64 bytes is a typical length for a cache
line; however, some caches have longer lines than this, and some caches have
shorter lines. Often the caches that are closer to the processor have shorter
lines, and the lines further from the processor have longer lines. Figure 2.2
illustrates what happens when a line is fetched into cache from memory.
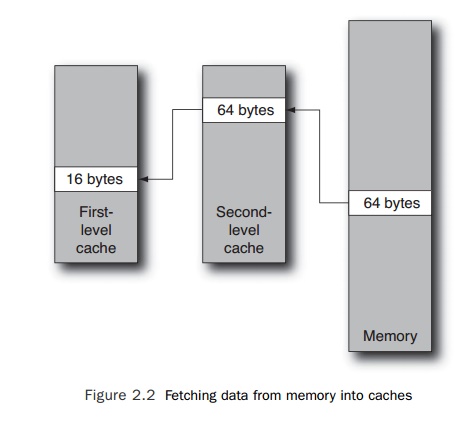
On a cache miss, a cache line will be fetched from memory and installed
into the sec-ond-level cache. The portion of the cache line requested by the
memory operation is installed into the first-level cache. In this scenario,
accesses to data on the same 16-byte cache line as the original item will also
be available from the first-level cache. Accesses to data that share the same
64-byte cache line will be fetched from the second-level cache. Accesses to
data outside the 64-byte cache line will result in another fetch from memory.
If data is fetched from memory when it is needed, the processor will
experience the entire latency of the memory operation. On a modern processor,
the time taken to per-form this fetch can be several hundred cycles. However,
there are techniques that reduce this latency:
Out-of-order execution is where the processor will search the instruction stream for future instructions that it can
execute. If the processor detects a future load instruction, it can fetch the
data for this instruction at the same time as fetching data for a previous load
instruction. Both loads will be fetched simultaneously, and in the best case,
the total cost of the loads can be potentially halved. If more than two loads
can be simultaneously fetched, the cost is further reduced.
n Hardware prefetching of data streams is where part of the processor is dedicated to detecting streams of data being read from memory. When a stream of data is iden-tified, the hardware starts fetching the data before it is requested by the processor. If the hardware prefetch is successful, the data might have become resident in the cache before it was actually needed. Hardware prefetching can be very effective in situations where data is fetched as a stream or through a strided access pattern. It is not able to prefetch data where the access pattern is less apparent.
n Software prefetching is the act of adding instructions to fetch data from memory before it is needed. Software
prefetching has an advantage in that it does not need to guess where the data
will be requested from in the memory, because the prefetch instruction can
fetch from exactly the right address, even when the address is not a linear
stride from the previous address. Software prefetch is an advantage when the
access pattern is nonlinear. When the access pattern is predictable, hardware
prefetching may be more efficient because it does not take up any space in the
instruction stream.
Another approach to covering memory latency costs is with CMT
processors. When one thread stalls because of a cache miss, the other running
threads get to use the processor resources of the stalled thread. This
approach, unlike those discussed earlier, does not improve the execution speed
of a single thread. This can enable the processor to achieve more work by sustaining
more active threads, improving throughput rather than single-threaded
performance.
There are a number of common coding styles that can often result in
suboptimal lay-out of data in memory. The following subsections describe each
of these.
Improving
Performance Through Data Density and Locality
Paying attention to the order in which variables are declared and laid
out in memory can improve performance. As discussed earlier, when a load brings
a variable in from memory, it also fetches the rest of the cache line in which
the variable resides. Placing variables that are commonly accessed together
into a structure so that they reside on the same cache line will lead to
performance gains. Consider the structure shown in Listing 2.27.
Listing 2.27 Data
Structure
struct
s
{
int var1;
int padding1[15]; int var2;
int padding2[15];
}
When the structure member var1 is accessed, the fetch will also bring in the sur-rounding 64 bytes.
The size of an integer variable is 4 bytes, so the total size of var1 plus padding1 is 64
bytes. This ensures that the variable var2 is located on the next cache line. Listing 2.28 shows the structure reordered so that var1 and var2 are
adjacent. This will usually ensure that both are fetched at the same time.
Listing 2.28 Reordered Data
Structure So That Important Structure Members Are Likely to Share a Cache Line
struct s
{
int var1; int var2;
int padding1[15]; int padding2[15]
}
If the structure does not fit
exactly into the length of the cache line, there will be situations when the
adjacent var1 and var2 are split over two cache lines. This intro-duces a dilemma. Is it
better to pack the structures as close as possible to fit as many of them as
possible into the same cache line, or is it better to add padding to the structures
to make them consistently align with the cache line boundaries? Figure 2.3
shows the two situations.
The answer will depend on various factors. In most cases, the best
answer is probably to pack the structures as tightly as possible. This will mean
that when one structure is accessed, the access will also fetch parts of the
surrounding structures. The situation
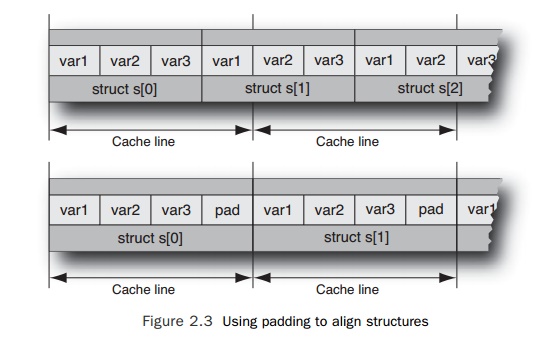
where it is appropriate to add padding to the structure is when the
structures are always accessed randomly, so it is more important to ensure that
the critical data is not split across a cache line.
The performance impact of poorly ordered structures
can be hard to detect. The cost is spread over all the accesses to the
structure over the entire application. Reordering the structure members can
improve the performance for all the routines that access the structures.
Determining the optimal layout for the structure members can also be
diffi-cult. One guideline would be to order the structure members by access
frequency or group them by those that are accessed in the hot regions of code.
It is also worth consid-ering that changing the order of structure members
could introduce a performance regression if the existing ordering happens to
have been optimal for a different fre-quently executed region of code.
A similar optimization is structure splitting, where an existing
structure is split into members that are accessed frequently and members that
are accessed infrequently. If the infrequently accessed structure members are
removed and placed into another structure, then each fetch of data from memory
will result in more of the critical structures being fetched in one action.
Taking the previous example, where we assume that var3 is rarely needed, we would end up with a resulting pair of structures,
as shown in Figure 2.4.
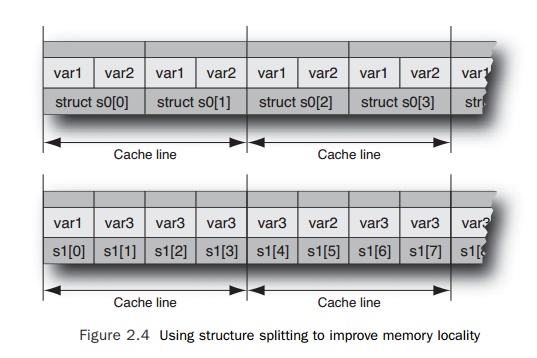
In this instance, the original structure s has been split into two, with s0 containing all the frequently accessed data and s1 containing all the infrequently accessed data. In the limit, this
optimization is converting what might be an array of structures into a set of
arrays, one for each of the original structure members.
Selecting
the Appropriate Array Access Pattern
One common data access pattern is striding through
elements of an array. The perform-ance of the application would be better if
the array could be arranged so that the selected elements were contiguous.
Listing 2.29 shows an example of code accessing an array with a stride.
Listing 2.29 Noncontiguous Memory Access Pattern
{
double ** array; double total=0;
…
for (int i=0; i<cols; i++) for
(int j=0; j<rows; j++)
total += array[j][i];
…
}
C/C++
arrays are laid out in memory so that the adjacent elements of the final index
(in this case indexed by the variable i) are adjacent in memory; this is called row-major order. However, the inner loop
within the loop nest is striding over the first index into the matrix and
accessing the ith element of that array. These elements will not be
located in contiguous memory.
In Fortran, the opposite ordering is followed, so
adjacent elements of the first index are adjacent in memory. This is called column-major order. Accessing elements
by a stride is a common error in codes translated from Fortran into C. Figure
2.5 shows how mem-ory is addressed in C, where adjacent elements in a row are
adjacent in memory.
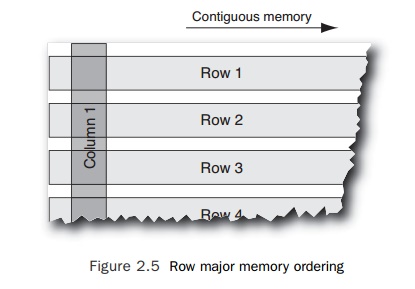
Fortunately,
most compilers are often able to correctly interchange the loops and improve
the memory access patterns. However, there are many situations where the compiler
is unable to make the necessary transformations because of aliasing or the
order in which the elements are accessed in the loop. In these cases, it is
necessary for the developer to determine the appropriate layout and then
restructure the code appropriately.
Choosing Appropriate Data
Structures
Choosing
the best structure to hold data, such as choosing an algorithm of the
appropri-ate complexity, can have a major impact on overall performance. This
harks back to the discussions of algorithmic complexity earlier in this
chapter. Some structures will be effi-cient when data is accessed in one
pattern, while other structures will be more efficient if the access pattern is
changed.
Consider a simple example. Suppose you have a
dictionary of words for a spell-checker application. You don’t know at compile
time how many words will be in the dictionary, so the easiest way to cope with
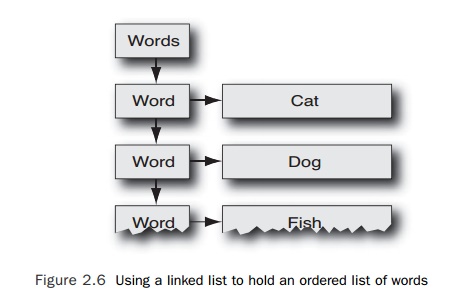
this might be to read in the words and place them onto a linked list, as shown
in Figure 2.6.
Every
time the application needs to check whether a word is in the dictionary, it
traverses the linked list of words, so a spell-check of the entire document is
an O(N2) activity.
An
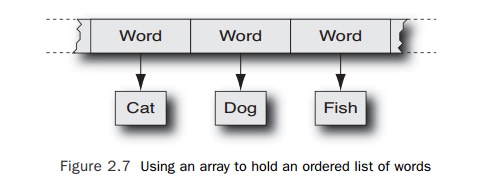
alternative implementation might be to allocate an array of known length to
hold pointers to the various words, as shown in Figure 2.7.
Although there might be some complications in
getting the array to be the right length to hold all the elements, the benefit
comes from being able to do a binary search on the sorted list of words held in
the array. A binary search is an O(log2(N)) activity, so performing
a spell-check on an entire document would be an O(N∗log2(N)) activity, which, as indicated
earlier, would be a significantly faster approach.
As in any
example, there are undoubtedly better structures to choose for holding a
dictionary of words. Choosing the appropriate one for a particular application
is a case of balancing the following factors:
n Programmer
time to implement the algorithm. There will probably be constraints on the
amount of time that a developer can spend on implementing a single part of the
application.
n User
sensitivity to application performance. Some features are rarely used, so a
user might accept that, for example, performing a spell-check on an entire
document will take time. It may also be the case that the compute part of the
task is not time critical; in the case of a spell-check, if a spelling error is
reported, the user may spend time reading the text to determine the appropriate
word to use, during which the application could continue and complete the
spell-check of the rest of the document.
n The
problem size is not large enough to justify the more complex algorithm. If the
application is limited to documents of only a few hundred words, it is unlikely
that a spell-check of the entire document would ever take more than about half
a second. Any performance gains from the use of an improved algorithm would be
unnoticeable.
In many
situations, there are preexisting libraries of code that implement different
data management structures. For C++, the Standard Template Library provides a
wealth of data structures. Careful coding to encapsulate the use of the data
structures can mini-mize developer time by allowing the original structures to
be easily replaced with more efficient ones should that prove necessary.
Related Topics