Chapter: Advanced Computer Architecture : Multiprocessors and Thread Level Parallelism
Symmetric Shared Memory Architectures
Symmetric Shared Memory
Architectures
The
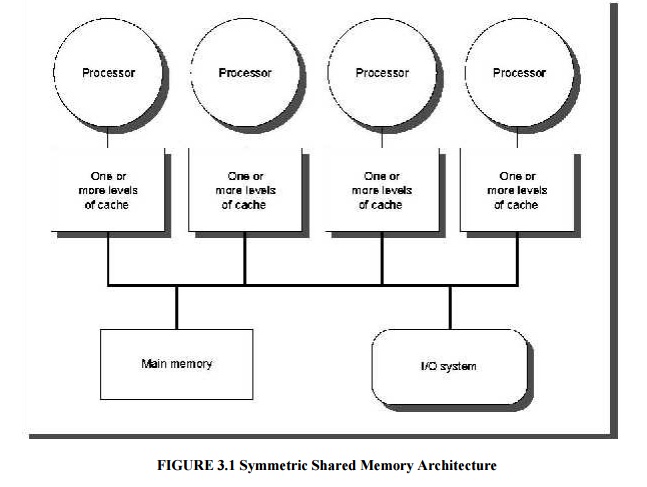
Symmetric Shared Memory Architecture consists of several processors with a
single physical memory shared by all processors through a shared bus which is
shown below.
`
Small-scale shared-memory machines usually support the caching of both shared
and private data. Private data is used by a single processor, while shared data
is used by multiple processors, essentially providing communication among the
processors thro ugh reads and writes of the shared data. When a private item is
cached, its location is migrated to the cache, reducing the average access time
as well as the memory bandwidth required. Since no other processor uses the
data, the program behavior is identical to that in a uniprocessor.
1. Cache
Coherence in Multiprocessors:
Introduction of caches caused a coherence problem
for I/O operations, The same problem exists in the case of multiprocessors,
because the view of memory held by two different processors is through their
individual caches.
The problem and shows how two different processors
can have two different values for the same location. This difficulty is
generall y referred to as the c a c h e -
Coherence
problem.
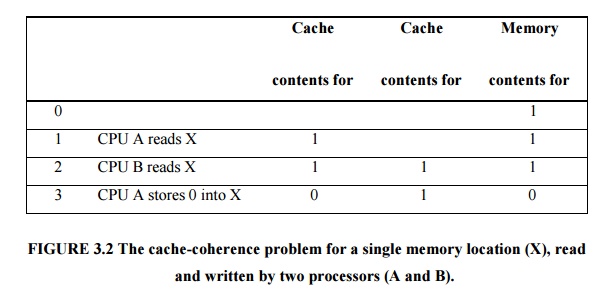
We initially assume that neither cache contains the
variable and that X has the value 1.We also assume a write-through cache; a
write-back cache adds some additional but similar complications.
After the value of X has been written by A, A’s
cache and the memory both contain the new value, but B’s cache does not, and if
B reads the value of X, it will receive 1!
Informally, we could say that a memory system is
coherent if any read of a data item returns the most recently written value of
that data item. This simple definition contains two different aspects of memory
system behavior, both of which are critical to writing correct shared-memory
programs.
The first
aspect, called coherence, defines what values can be returned by a read. The
second aspect, called consistency, determines when a written value will be
returned by a read. Let’s look at coherence first.
A memory system
is coherent if
Ø A read by
a processor, P, to a location X that follows a write by P to X, with no writes
of X by another processor occurring between the write and the read by P, always
returns the value written by P.
Ø A read by
a processor to location X that follows a write by another processor to X
returns the written value if the read and write are sufficiently separated in
time and no other writes to X occur between the two accesses.
Ø Writes to
the same location are serialized: that is, two writes to the same location by
any two processors are seen in the same order by all processors. For example,
if the values 1 and then 2 are written to a location, processors can never read
the value of the location as 2 and then later read it as 1.
Coherence
and consistency are complementary: Coherence defines the behavior of reads and
writes to the same memory location, while consistency defines the behavior of
reads and writes with respect to accesses to other memory locations.
2. Basic Schemes for Enforcing
Coherence
Coherent
caches provide migration, since a data item can be moved to a local cache and
used there in a transparent fashion. This migration reduces both the latency to
access a shared data item that is allocated remotely and the bandwidth demand
on the shared memory.
Coherent
caches also provide replication for shared data that is being simultaneously
read, since the caches make a copy of the data item in the local cache.
Replication reduces both latency of access and contention for a read shared
data item.
The
protocols to maintain coherence for multiple processors are called
cache-coherence protocols. There are two classes of protocols, which use
different techniques to track the sharing status, in use:
Directory
based—The sharing status of a block of physical memory is kept in just one
location, called the directory; we focus on this approach in section 6.5, when
we discuss scalable shared-memory architecture.
Snooping—Every
cache that has a copy of the data from a block of physical memory also has a
copy of the sharing status of the block, and no centralized state is kept. The
caches are usually on a shared-memory bus, and all cache controllers monitor or
snoop on the bus to determine whether or not they have a copy of a block that
is requested on the bus.
3. Snooping Protocols
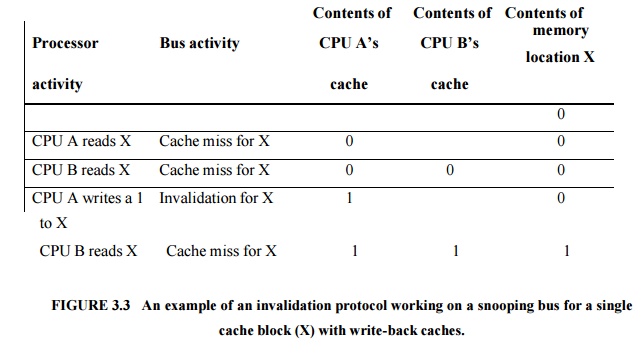
The
method which ensures that a processor has exclusive access to a data item
before i t writes that item. This style of protocol is called a write
invalidate protocol because it invalidates other copies on a write. It is by
far the most common protocol, both for snooping and for directory schemes.
Exclusive access ensures that no other readable or writable copies of an item
exist when the write occurs: all other cached copies of the item are
invalidated.
Since the write requires exclusive access, any copy
held by the reading processor must be invalidated (hence the protocol name).
Thus, when the read occurs, it misses in the cache and is forced to fetch a new
copy of the data.
For a write, we require that the writing processor
have exclusive access, preventing any other processor from being able to write
simultaneously.
If two processors do attempt to write the same data
simultaneously, one of them wins the race, causing the other processor’s copy
to be invalidated. For the other processor to
complete
its write, it must obtain a new copy of the data, which must now contain the
updated value. Therefore, this protocol enforces write serialization.
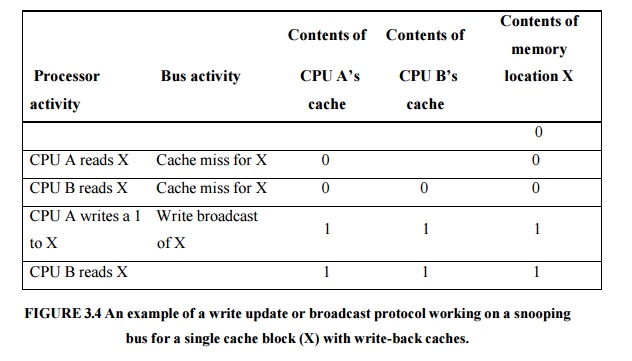
The
alternative to an invalidate protocol is to update all the cached copies of a
data item when that item is written. This type of protocol is called a write
update or writes broadcast protocol. Figure 6.8 shows an example of a write
update protocol in operation. In the decade since these protocols were
developed, invalidate has emerged as the winner for the vast majority of
designs.
The
performance differences between write update and write invalidate protocols
arise from three characteristics:
Ø Multiple
writes to the same word with no intervening reads require multiple write
broadcasts in an update protocol, but only one initial invalidation in a write
invalidate protocol.
Ø With
multiword cache blocks, each word written in a cache block requires a write
broadcast in an update protocol, although only the first write to any word in
the block needs to generate an invalidate in an invalidation protocol. An
invalidation protocol works on cache blocks, while an update protocol must work
on individual words (or bytes, when bytes are written). It is possible to try
to merge writes in a write broadcast scheme.
Ø The delay
between writing a word in one processor and reading the written value in
another processor is usually less in a write update scheme, since the written
Ø data are
immediately updated in the reader’s cache
4. Basic Implementation
Techniques
The
serialization of access enforced by the bus also forces serialization of
writes, since when two processors compete to write to the same location, one
must obtain bus access before the other. The first processor to obtain bus
access will cause th e other processor’s copy to be invalidated, causing writes
to be strictly serialized. One implication of this scheme is that a write to a
shared data item cannot complete until it obtains bus access.
For a
write-back cache, however, the problem of finding the most recent data value is
harder, since the most recent value of a data item can be in a cache rather
than in memory. Happily, write-back caches can use the same snooping scheme
both for caches misses and for writes: Each processor snoops every address
placed on the bus. If a processor finds that it has a dirty copy of the
requested cache block, it provides that cache block in response to the read
request and causes the memory access to be aborted.
Since
write-back caches generate lower requirements for memory bandwidth, they are
greatly preferable in a multiprocessor, despite the slight increase in
complexity. Therefore, we focus on implementation with write-back caches.
The
normal cache tags can be used to implement the process of snooping, and the
valid bit for each block makes invalidation easy to implement. Read misses,
whether generated by an invalidation or by some other event, are also
straightforward since they simply rely on the snooping capability. For writes
we’d like to know whether any other copies of the block are cached, because, if
there are no other cached copies, then the write need not be placed on the bus
in a write-back cache. Not sending the write reduces both the time taken by the
write and the required bandwidth.
Related Topics