Chapter: Digital Signal Processing : Applications of DSP
Speech signal processing
Speech signal processing:
The topic of speech signal
processing can be loosely defined as the manipulation of sampled speech signals
by a digital processor to obtain a new signal with some desired properties.
Speech signal processing is a diverse field that
relies on knowledge of language at the levels of Signal processing
Acoustics (P¥)
Phonetics (
^ ^ ^ ) Language-independent
Phonology (
^ ^ )
Morphology (
i ^ ^ ^ )
Syntax ( ^ ,
£ ) Language-dependent
Semantics (\%X¥)
Pragmatics ( i f , f f l ^ )
7 layers
for describing speech From Speech to Speech Signal, in terms of Digital Signal Processing
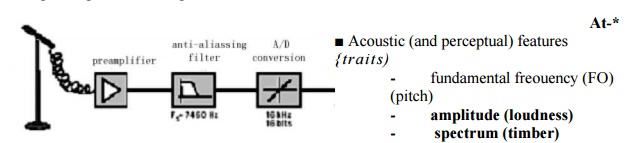
It is based on the fact that
- Most of energy between 20 Hz to about 7KHz ,
- Human ear sensitive to energy between 50 Hz and 4KHz
© In terms of acoustic or perceptual, above features are considered.
© From Speech to Speech Signal, in terms of Phonetics (Speech production), the digital model of Speech Signal will be discussed in Chapter 2.
© Motivation of converting speech to digital signals:
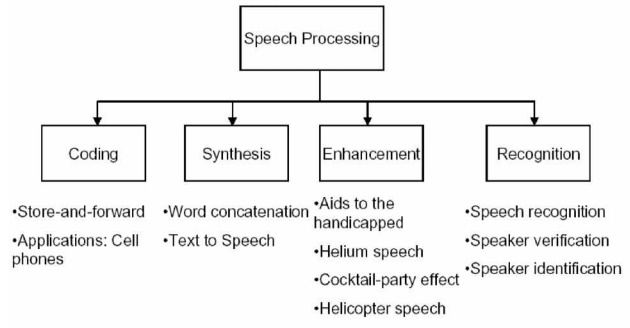
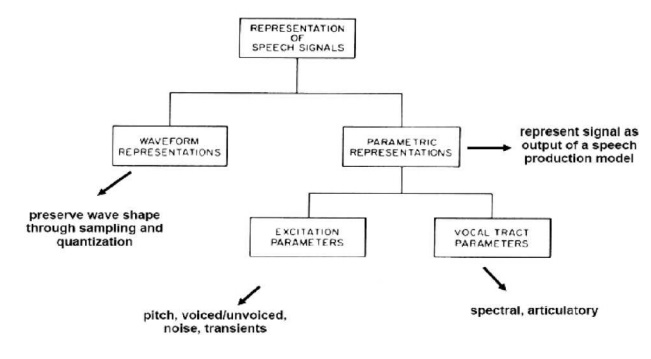
Speech
coding, A PC and SBC fine
Adaptive predictive coding (APC) is a technique used for speech coding, that is data compression of spccch signals APC assumes that the input speech signal is repetitive with a period significantly longer than the average frequency content. Two predictors arc used in APC.
The high frequency components (up to 4 kHz) are
estimated using a 'spectral’ or 'formant’ prcdictor and the low frequency
components (50-200 Hz) by a ‘pitch’ or ‘fine structure’ prcdictor (see figure
7.4). The spcctral estimator may he of order 1- 4 and the pitch estimator about
order 10. The low-frequency components of the spccch signal are due to the
movement of the tongue, chin and spectral envelope, formants
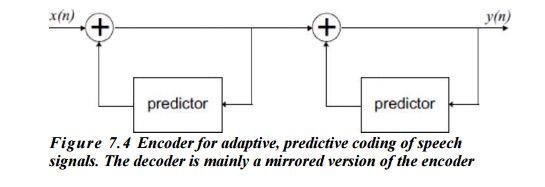
The high-frequency components originate from the
vocal chords and the noise-like sounds (like in ‘s’) produced in the front of
the mouth.
The output signal y(n)together with the predictor parameters, obtained adaptively in
the encoder, are transmitted to the decoder, where the spcech signal is
reconstructed. The decoder has the same structure as the encoder but the
predictors arc not adaptive and arc invoked in the reverse order. The
prediction parameters are adapted for blocks of data corresponding to for
instance 20 ms time periods.
A PC' is used for coding spcech at 9.6 and 16
kbits/s. The algorithm works well in noisy environments, but unfortunately the
quality of the processed speech is not as good as for other methods like CELP
described on next page.
Related Topics