Chapter: Distributed Systems : Peer To Peer Services and File System
Peer-To-Peer (P2P)
PEER-TO-PEER SYSTEMS
Peer-to-peer (P2P) computing or networking is a distributed application
architecture that partitions tasks
or work loads between peers. Peers are equally privileged, equipotent
participants in the application. They are said to form a peer-to-peer network
of nodes.
Peers
make a portion of their resources, such as processing power, disk storage or
network and width, directly available to other network participants, without
the need for central coordination by servers or stable hosts. Peers are both
suppliers and consumers of resources, in contrast to the traditional
client-server model in which the consumption and supply of resources is
divided. Emerging collaborative P2P systems are going beyond the era of peers
doing similar things while sharing resources, and are looking for diverse peers
that can bring in unique resources and capabilities to a virtual community
thereby empowering it to engage in greater tasks beyond those that can be
accomplished by individual peers, yet that are beneficial to all the peers.
While P2P
systems had previously been used in many application domains, the architecture
was popularized by the file sharing system Napster, originally released in
1999. The concept has inspired new structures and philosophies in many areas of
human interaction. In such social contexts, peer-to-peer as a meme refers to
theegalitarian social networking that has emerged throughout society, enabled
by Internettechnologies in general.
The
demand for services in the Internet can be expected to grow to a scale that is
limited only by the size of the world’s population. The goal of peer-to-peer
systems is to enable the sharing of data and resources on a very large scale by
eliminating any requirement for separately managed servers and their associated
infrastructure. The scope for expanding popular services by adding to the
number of the computers hosting them is limited when all the hosts must be
owned and managed by the service provider. Administration and fault recovery
costs tend to dominate. The network bandwidth that can be provided to a single
server site over available physical links is also a major constraint.
System-level services such as Sun NFS (Section 12.3), the Andrew File System
(Section 12.4) or video servers (Section 20.6.1) and application-level services
such as Google, Amazon or eBay all exhibit this problem to varying degrees.
Peer-to-peer
systems aim to support useful distributed services and applications using data
and computing resources available in the personal computers and workstations
that are present in the Internet and other networks in ever-increasing numbers.
This is increasingly attractive as the performance difference between desktop
and server machines narrows and broadband network connections proliferate. But
there is another, broader aim: has defined peer-topeer applications as
‘applications
that exploit resources available at the edges of the Internet – storage,
cycles, content, human presence’. Each type of resource sharing mentioned in
that definition is already represented by distributed applications available
for most types of personal computer. The purpose of this chapter is to describe
some general techniques that simplify the construction of peer-to-peer
applications and enhance their scalability, reliability and security.
Traditional
client-server systems manage and provide access to resources such as files, web
pages or other information objects located on a single server computer or a
small cluster of tightly coupled servers. With such centralized designs, few
decisions are required about the placement of the resources or the management
of server hardware resources, but the scale of the service is limited by the
server hardware capacity and network connectivity. Peer-to-peer systems provide
access to information resources located on computers throughout a network
(whether it be the Internet or a corporate network). Algorithms for the
placement and subsequent retrieval of information objects are a key aspect of
the system design. The aim is to deliver a service that is fully decentralized
and self-organizing, dynamically balancing the storage and processing loads
between all the participating computers as computers join and leave the
service. Peer-to-peer systems share these characteristics:
Their
design ensures that each user contributes resources to the system.
Although
they may differ in the resources that they contribute, all the nodes in a
peer-to-peer system have the same functional capabilities and responsibilities.
Their
correct operation does not depend on the existence of any centrally
administered systems.
They can
be designed to offer a limited degree of anonymity to the providers and users
of resources.
A key
issue for their efficient operation is the choice of an algorithm for the
placement of data across many hosts and subsequent access to it in a manner
that balances the workload and ensures availability without adding undue
overheads.
Napster and its legacy
The first
application in which a demand for a globally scalable information storage and
retrieval service emerged was the downloading of digital music files. Both the
need for and the feasibility of a peer-to-peer solution were first demonstrated
by the Napster filesharing system [OpenNap 2001] which provided a means for
users to share files. Napster became very popular for music exchange soon after
its launch in 1999. At its peak, several million users were registered and
thousands were swapping music files simultaneously. Napster’s architecture
included centralized indexes, but users supplied the files, which were stored
and accessed on their personal computers. Napster’s method of operation is
illustrated by the sequence of steps shown in Figure 10.2.
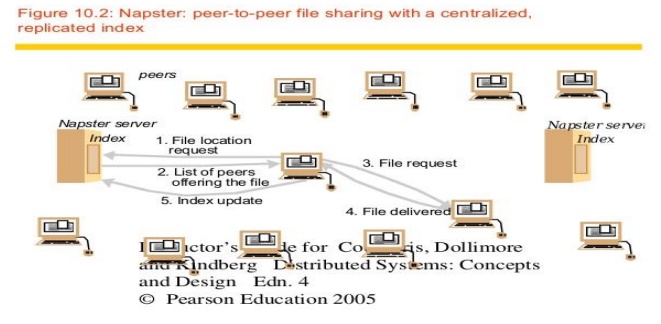
Note that
in step 5clients are expected to add their own music files to the pool of
shared resources by transmitting a link to the Napster indexing service for
each available file. Thus the motivation for Napster and the key to its success
was the making available of a large, widely distributed set of files to users
throughout the Internet, fulfilling Shirky’s dictum by providing access to
‘shared resources at the edges of the Internet’. Napster was shut down as a
result of legal proceedings instituted against the operators of the Napster
service by the owners of the copyright in some of the material (i.e., digitally
encoded music) that was made available on it (see the box below). Anonymity for
the receivers and the providers of shared data and other resources is a concern
for the designers of peer-to-peer systems. In systems with many nodes, the
routing of requests and results can be made sufficiently tortuous to conceal
their source and the contents of files can be distributed across multiple
nodes, spreading the responsibility for making them available. Mechanisms for
anonymous communication that are resistant to most forms of traffic analysis
are available If files are also encrypted before they are placed on servers,
the owners of the servers can plausibly deny any knowledge of the contents. But
these anonymity techniques add to the cost of resource sharing, and recent work
has shown that the anonymity available is weak against some attacks The Freenet
projects are focused on providing Internet-wide file services that offer
anonymity for the providers and users of the shared files. Ross Anderson has
proposed the Eternity Service , a storage service that provides long-term
guarantees of data
Peer-to-peer systems and
copyright ownership issues
The
developers of Napster argued that they were not liable for the infringement of
the copyright owners’ rights because they were not participating in the copying
process, which was performed entirely between users’ machines. Their argument
failed because the index servers were deemed an essential part of the process.
Since the index servers were located at well-known addresses, their operators
were unable to remain anonymous and so could be targeted in lawsuits.
A more
fully distributed file-sharing service might have achieved a better separation
of legal responsibilities, spreading the responsibility across all of the users
and thus making the pursuit of legal remedies very difficult, if not
impossible.
Whatever
view one takes about the legitimacy of file copying for the purpose of sharing
copyright-protected material, there are legitimate social and political
justifications for the anonymity of clients and servers in some application
contexts. The most persuasive justification arises when anonymity is used to
overcome censorship and maintain freedom of expression for individuals in
oppressive societies or organizations. It is known that email and web sites
have played a significant role in achieving public awareness at times of
political crisis in such societies; their role could be strengthened if the
authors could be protected by anonymity.
Peer-to-peer
middleware systems are designed specifically to meet the need for the automatic
placement and subsequent location of the distributed objects managed by
peer-to-peer systems and applications.
Functional requirements • The
function of peer-to-peer middleware is to simplify the construction of services that are implemented
across many hosts in a widely distributed network. To achieve this it must
enable clients to locate and communicate with any individual resource made
available to a service, even though the resources are widely distributed
amongst the hosts. Other important requirements include the ability to add new
resources and to remove them at will and to add hosts to the service and remove
them. Like other middleware, peer-to-peer middleware should offer a simple
programming interface to application programmers that is independent of the
types of distributed resource that the application manipulates.
Non-functional requirements • To
perform effectively, peer-to-peer middleware must also address the following non-functional
requirements
Global
scalability: One of the aims of peer-to-peer applications is to exploit the
hardware resources of very large numbers of hosts connected to the Internet.
Peer-topeer middleware must therefore be designed to support applications that
access millions of objects on tens of thousands or hundreds of thousands of
hosts.
Load
balancing: The performance of any system designed to exploit a large number of
computers depends upon the balanced distribution of workload across them. For
the systems we are considering, this will be achieved by a random placement of
resources together with the use of replicas of heavily used resources.
Optimization
for local interactions between neighbouring peers: The ‘network distance’
between nodes that interact has a substantial impact on the latency of
individual interactions, such as client requests for access to resources.
Network traffic loadings are also impacted by it. The middleware should aim to
place resources close to the nodes that access them the most.
Accommodating to highly dynamic host availability: Most
peer-to-peer systems are constructed
from host computers that are free to join or leave the system at any time. The
hosts and network segments used in peer-to-peer systems are not owned or
managed by any single authority; neither their reliability nor their continuous
participation in the provision of a service is guaranteed. A major challenge
for peerto- peer systems is to provide a dependable service despite these
facts. As hosts join the system, they must be integrated into the system and
the load must be redistributed
to
exploit their resources. When they leave the system whether voluntarily or
involuntarily, the system must detect their departure and redistribute their
load and resources.
Routing overlays
In
peer-to-peer systems a distributed algorithm known as a routing overlay takes responsibility for locating nodes and
objects. The name denotes the fact that the middleware takes the form of a
layer that is responsible for routing requests from any client to a host that
holds the object to which the request is addressed. The objects of interest may
be placed at and subsequently relocated to any node in the network without
client involvement. It is termed an overlay since it implements a routing
mechanism in the application layer that is quite separate from any other
routing mechanisms deployed at the network level such as IP routing. The
routing overlay ensures that any node can access any object by routing each
request through a sequence of nodes, exploiting knowledge at each of them to
locate the destination object. Peer-to-peer systems usually store multiple
replicas of objects to ensure availability. In that case, the routing overlay
maintains knowledge of the location of all the available replicas and delivers
requests to the nearest ‘live’ node (i.e. one that has not failed) that has a
copy of the relevant object. The GUIDs used to identify nodes and objects are
an example of the ‘pure’ names. These are also known as opaque identifiers,
since they reveal nothing about the locations of the objects to which they
refer. The main task of a routing overlay is the following:
Routing of requests to objects: A
client wishing to invoke an operation on an object submits a request including the object’s GUID to
the routing overlay, which routes the request to a node at which a replica of
the object resides.
But the
routing overlay must also perform some other tasks:
Insertion of objects: A node
wishing to make a new object available to a peer-to-peer service computes a GUID for the object and
announces it to the routing overlay,which then ensures that the object is
reachable by all other clients.
Deletion of objects: When
clients request the removal of objects from the service the routing overlay must make them unavailable.
Node addition and removal: Nodes
(i.e., computers) may join and leave the service. When a node joins the service, the routing overlay
arranges for it to assume some of the responsibilities of other nodes. When a
node leaves (either voluntarily or as a result of a system or network fault),
its responsibilities are distributed amongst the other nodes.
Related Topics