Chapter: Distributed Systems : Peer To Peer Services and File System
File Service Architecture
File Service Architecture
·
An architecture that offers a clear separation of
the main concerns in providing access to files is obtained by structuring the
file service as three components:
o
A flat file service
o
A directory service
o
A client module.
·
The relevant modules and their relationship is
shown in Figure 5.
·
Figure 5. File service architecture
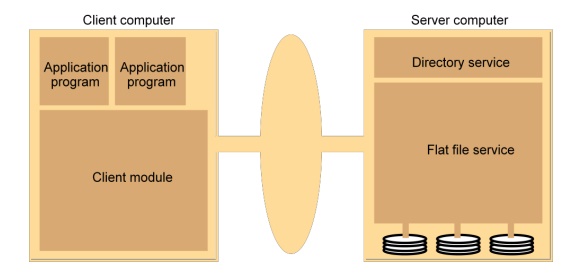
·
The Client module implements exported interfaces by
flat file and directory services on server side.
·
Responsibilities of various modules can be defined
as follows:
o
Flat file service:
§ Concerned
with the implementation of operations on the contents of file. Unique File
Identifiers (UFIDs) are used to refer to files in all requests for
·
flat file service operations. UFIDs are long
sequences of bits chosen so that each file has a unique among all of the files
in a distributed system.
·
Directory service:
o
Provides mapping between text names for the files
and their UFIDs. Clients may obtain the UFID of a file by quoting its text name
to directory service. Directory service supports functions needed generate
directories, to add new files to directories.
·
Client module:
·
It runs on each computer and provides integrated
service (flat file and directory) as a single API to application programs. For
example, in UNIX hosts, a client module emulates the full set of Unix file
operations.
·
It holds information about the network locations of
flat-file and directory server processes; and achieve better performance
through implementation of a cache of recently used file blocks at the client.
o
Flat file service interface:
·
Figure 6 contains a definition of the interface to
a flat file service.
Figure 6. Flat file service operations

·
Access control
o
In distributed implementations, access rights
checks have to be performed at the server because the server RPC interface is
an otherwise unprotected point of access to files.
·
Directory service interface
o
Figure 7 contains a definition of the RPC interface
to a directory service.
Figure 7. Directory service operations

Hierarchic file system
A
hierarchic file system such as the one that UNIX provides consists of a number
of directories arranged in a tree structure.
File
Group
A file group is a collection of files that can be located on any server
or moved between servers while maintaining the same names.
A similar
construct is used in a UNIX file system.
It helps
with distributing the load of file serving between several servers.
File
groups have identifiers which are unique throughout the system (and hence for an open
system, they must be globally unique).
To
construct globally unique ID we use some unique attribute of the machine on
which it is created. E.g: IP number, even though the file group may move
subsequently.

DFS: Case Studies
·
NFS (Network File System)
o
Developed by Sun Microsystems (in 1985)
o
Most popular, open, and widely used.
o
NFS protocol standardized through IETF (RFC 1813)
·
AFS (Andrew File System)
o
Developed by Carnegie Mellon University as part of
Andrew distributed computing environments (in 1986)
o
A research project to create campus wide file
system.
o
Public domain implementation is available on Linux
(LinuxAFS)
o
It was adopted as a basis for the DCE/DFS file
system in the Open Software Foundation (OSF, www.opengroup.org) DEC
(Distributed Computing Environment
NFS architecture
Figure 8
shows the architecture of Sun NFS
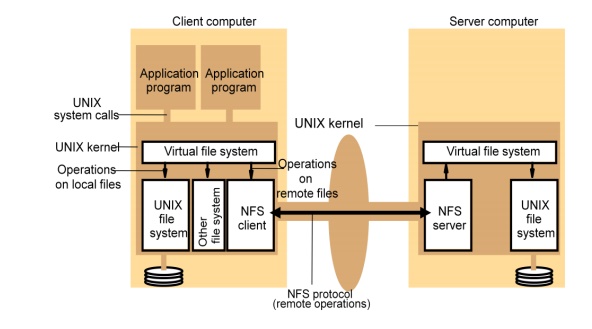
The file
identifiers used in NFS are called file handles.

A
simplified representation of the RPC interface provided by NFS version 3
servers is shown in Figure 9.
Figure 9. NFS server operations (NFS Version 3
protocol, simplified)

·
NFS access control and authentication
o
The NFS server is stateless server, so the user's
identity and access rights must be checked by the server on each request.
§ In the
local file system they are checked only on the file’s access permission
attribute.
o
Every client request is accompanied by the userID
and groupID
§ It is not
shown in the Figure 8.9 because they are inserted by the RPC system.
o
Kerberos has been integrated with NFS to provide a
stronger and more comprehensive security solution.
·
Mount service
o
Mount operation:
·
mount(remotehost, remotedirectory, localdirectory)
·
Server maintains a table of clients who have
mounted filesystems at that server.
·
Each client maintains a table of mounted file
systems holding:
o IP address,
port number, file handle>
·
Remote file systems may be hard-mounted or
soft-mounted in a client computer.
·
Figure 10 illustrates a Client with two remotely
mounted file stores.
Figure 10. Local and remote file systems accessible
on an NFS client
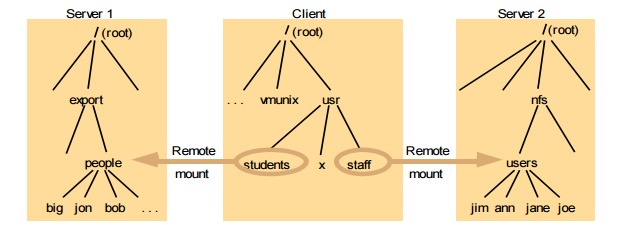
·
Automounter
o
The automounter was added to the UNIX
implementation of NFS in order to mount a remote directory dynamically whenever
an ‘empty’ mount point is referenced by a client.
§ Automounter
has a table of mount points with a reference to one or more NFS servers listed
against each.
§ it sends
a probe message to each candidate server and then uses the mount service to
mount the file system at the first server to respond.
·
Automounter keeps the mount table small.
o
Automounter Provides a simple form of replication
for read-only file systems.
·
E.g. if there are several servers with identical
copies of /usr/lib then each
§ server
will have a chance of being mounted at some clients.
§ Server
caching
o
Similar to UNIX file caching for local files:
·
pages (blocks) from disk are held in a main memory
buffer cache until the space is required for newer pages. Read-ahead and
delayed-write optimizations.
·
For local files, writes are deferred to next sync
event (30 second intervals).
·
Works well in local context, where files are always
accessed through the local cache, but in the remote case it doesn't offer
necessary synchronization guarantees to clients.
o
NFS v3 servers offers two strategies for updating
the disk:
§ Write-through
- altered pages are written to disk as soon as they are received at the server.
When a write() RPC returns, the NFS client knows that the page is on the disk.
§ Delayed
commit - pages are held only in the cache until a commit() call is received for
the relevant file. This is the default mode used by NFS v3 clients. A commit()
is issued by the client whenever a file is closed.
·
Client caching
o
Server caching does nothing to reduce RPC traffic
between client and server
§ further
optimization is essential to reduce server load in large networks.
§ NFS
client module caches the results of read, write, getattr, lookup and readdir
operations
§ synchronization
of file contents (one-copy semantics) is not guaranteed when two or more
clients are sharing the same file.
o
Timestamp-based validity check
§ It
reduces inconsistency, but doesn't eliminate it.
§ It is
used for validity condition for cache entries at the client:
§ (T - Tc < t) v (Tmclient = Tmserver)

·
it is configurable (per file) but is typically set
to 3 seconds for files and 30 secs. for directories.
·
it remains difficult to write distributed
applications that share files with NFS.
·
Other NFS optimizations
o
Sun RPC runs over UDP by default (can use TCP if
required).
o
Uses UNIX BSD Fast File System with 8-kbyte blocks.
o
reads() and writes() can be of any size (negotiated
between client and server).
o
The guaranteed freshness interval t is set
adaptively for individual files to reduce getattr() calls needed to update Tm.
o
File attribute information (including Tm) is
piggybacked in replies to all file requests.
·
NFS performance
o
Early measurements (1987) established that:
§ Write()
operations are responsible for only 5% of server calls in typical UNIX
environments.
§ hence
write-through at server is acceptable.
§ Lookup()
accounts for 50% of operations -due to step-by-step pathname resolution
necessitated by the naming and mounting semantics.
o
More recent measurements (1993) show high
performance.
§ see www.spec.org for more recent measurements.
·
NFS summary
o
NFS is an excellent example of a simple, robust,
high-performance distributed service.
o
Achievement of transparencies are other goals of
NFS:
§ Access
transparency:
·
The API is the UNIX system call interface for both
local and remote files.
§ Location
transparency:
·
Naming of filesystems is controlled by client mount
operations, but transparency can be ensured by an appropriate system
configuration.
§ Mobility
transparency:
·
Hardly achieved; relocation of files is not
possible, relocation of filesystems is possible, but requires updates to client
configurations.
§ Scalability
transparency:
·
File systems (file groups) may be subdivided and
allocated to separate servers.
§ Replication
transparency:
o
Limited to read-only file systems; for writable
files, the SUN Network Information Service (NIS) runs over NFS and is used to
replicate essential system files.
·
Hardware and software operating system
heterogeneity:
o
NFS has been implemented for almost every known
operating system and hardware platform and is supported by a variety of filling
systems.
·
Fault tolerance:
o
Limited but effective; service is suspended if a
server fails. Recovery from failures is aided by the simple stateless design.
·
Consistency:
o
It provides a close approximation to one-copy
semantics and meets the needs
of the vast majority of applications.
o
But the use of file sharing via NFS for
communication or close coordination
between processes on different computers cannot be recommended.
·
Security:
o
Recent developments include the option to use a secure
RPC implementation for authentication
and the privacy and security of the data transmitted with read and write
operations.
o
Efficiency:
§ NFS
protocols can be implemented for use in situations that generate very heavy
loads.
Related Topics