Chapter: Distributed Systems : Peer To Peer Services and File System
Naming Services
Naming Services
Which one
is easy for humans and machines? and why?
·
74.125.237.83 or google.com
·
128.250.1.22 or distributed systems website
·
128.250.1.25 or Prof. Buyya
·
Disk 4, Sector 2, block 5 OR /usr/raj/hello.c
Introduction
·
In a distributed system, names are used to refer to
a wide variety of resources such as:
o
Computers, services, remote objects, and files, as
well as users.
·
Naming is fundamental issue in DS design as it
facilitates communication and resource sharing.
o
A name in the form of URL is needed to access a
specific web page.
o
Processes cannot share particular resources managed
by a computer system unless they can name them consistently
o
Users cannot communicate within one another via a
DS unless they can name one another, with email address.
·
Names are not the only useful means of
identification: descriptive attributes are another.
What are Naming Services?
·
How do Naming Services facilitate communication and
resource sharing?
o
An URL facilitates the localization of a
resource exposed on the Web.
§ e.g., abc.net.au means it is likely to be an
Australian entity?
o
A consistent and uniform naming helps
processes in a distributed system to interoperate and manage resources.
§ e.g., commercials use .com; non-profit
organizations use .org
o
Users refers to each other by means of their names
(i.e. email) rather than their system ids
o
Naming Services are not only useful to locate
resources but also to gather additional information about them
such as attributes
What are Naming Services?
In a
Distributed System, a Naming Service is a specific service whose aim is to
provide a consistent and uniform naming of resources, thus allowing other programs
or services to localize them and obtain the required metadata for interacting
with them.
Key benefits
·
Resource localization
·
Uniform naming
·
Device independent address (e.g., you can move
domain name/web site from one server to another server seamlessly).
The role of names and name services
·
Resources are accessed using identifier or reference
o
An identifier can be stored in variables and
retrieved from tables quickly
o
Identifier includes or can be transformed to an
address for an object
§ E.g. NFS file handle, Corba remote object reference
o
A name is
human-readable value (usually a string) that can be resolved to an identifier or address
§ Internet domain name, file pathname, process number
w E.g
./etc/passwd, http://www.cdk3.net/
o
For many purposes, names are preferable to
identifiers
o
because the binding of the named resource to a
physical location is deferred and can be changed
o
because they are more meaningful to users Resource names are resolved by name services
o
to give identifiers and other useful attributes
Requirements for name spaces
o
Allow simple but meaningful names to be used
o
Potentially infinite number of names
o
Structured
o
to allow similar subnames without clashes
o
to group related names
o
Allow re-structuring of name trees
o
for some types of change, old programs should
continue to work
o
Management of trust
Composed naming domains used to access a resource
from a URL
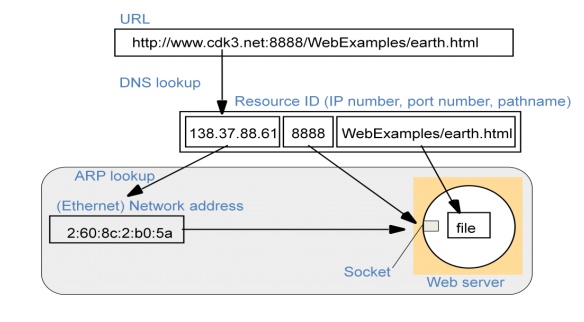
A key
attribute of an entity that is usually relevant in a distributed system is its
address. For example:
The DNS
maps domain names to the attributes of a host computer: its IP address, the
type of entry (for example, a reference to a mail server or another host) and,
for example, the length of time the host’s entry will remain valid.
The X500
directory service can be used to map a person’s name onto attributes including
their email address and telephone number.
The CORBA
Naming Service maps the name of a remote object onto its remote object
reference, whereas the Trading Service maps the name of a remote object onto
its remote object reference, together with an arbitrary number of attributes
describing the object in terms understandable by human users.
Name Services and the Domain Name System
A name
service stores a collection of one or more naming contexts, sets of bindings
between textual names and attributes for objects such as computers, services,
and users.
The major
operation that a name service supports is to resolve names.
Uniform Resource Identifiers
Uniform
Resource Identifiers (URIs) came about from the need to identify resources on
the Web, and other Internet resources such as electronic mailboxes. An
important goal was to identify resources in a coherent way, so that they could
all be processed by common software such as browsers. URIs are ‘uniform’ in
that their syntax incorporates that of indefinitely many individual types of
resource identifiers (that is, URI schemes), and there are procedures for
managing the global namespace of schemes. The advantage of uniformity is that
it eases the process of introducing new types of identifier, as well as using
existing types of identifier in new contexts, without disrupting existing
usage.
Uniform Resource Locators: Some URIs
contain information that can be used to locate and access a resource; others are pure resource names. The familiar
term Uniform Resource Locator (URL) is often used for URIs that provide
location information and specify the method for accessing the resource.
Uniform Resource Names: Uniform
Resource Names (URNs) are URIs that are used as pure resource names rather than locators. For example, the URI:
mid:0E4FC272-5C02-11D9-B115-000A95B55BC8@hpl.hp.com
Navigation
Navigation
is the act of chaining multiple Naming Services in order to resolve a single
name to the corresponding resource.
o
Namespaces allows for structure in names.
o
URLs provide a default structure that decompose the
location of a resource in
o
protocol used for retrieval
o
internet end point of the service exposing the
resource
o
service specific path
o
This decomposition facilitates the resolution of
the name into the corresponding resource
o
Moreover, structured namespaces allows for
iterative navigation…
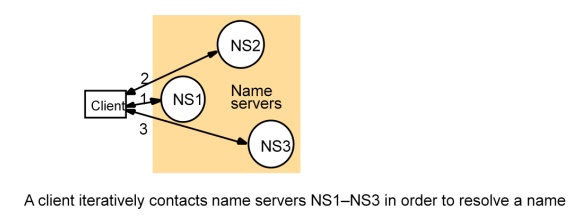
Iterative navigation
Reason for NFS iterative name resolution
This is
because the file service may encounter a symbolic link (i.e. an alias) when resolving a name. A symbolic
link must be interpreted in the client’s file system name space because it may
point to a file in a directory stored at another server. The client computer
must determine which server this is, because only the client knows its mount
points
Server controlled navigation
o
In an alternative model, name server coordinates
naming resolution and returns the results to the client. It can be:
o
Recursive:
§ it is performed by the naming server
§ the server becomes like a client for the next
server
§ this is necessary in case of client connectivity
constraints
o
Non recursive:
§ it is performed by the client or the first server
§ the server bounces back the next hop to its client
Non-recursive and recursive server-controlled
navigation
DNS
offers recursive navigation as an option, but iterative is the standard
technique. Recursive navigation must be used in domains that limit client
access to their DNS information for security reasons.


Lecture Notes: (To be attached)
Textbook :
George Coulouris, Jean Dollimore, Tim Kindberg, , "Distributed
Systems: Concepts and
Design",
4th Edition, Pearson Education, 2005. PP.
350-356.
Application

The
Domain Name System is a name service design whose main naming database is used
across the Internet.
This
original scheme was soon seen to suffer from three major shortcomings:
It did not
scale to large numbers of computers.
Local
organizations wished to administer their own naming systems.
A general
name service was needed – not one that serves only for looking up computer
addresses.
Domain names • The DNS is designed for use in
multiple implementations, each of which may
have its own name space. In practice, however, only one is in widespread
use, and that is the one used for naming across the Internet. The Internet DNS
name space is partitioned both organizationally and according to geography. The
names are written with the highest-level domain on the right. The original
top-level organizational domains (also called generic domains) in use across the Internet were:
com – Commercial organizations
edu – Universities and other educational institutions gov – US governmental agencies
mil – US military organizations
net – Major network support centres
org – Organizations not mentioned above int – International
organizations
New
top-level domains such as biz and mobi have been added since the early
2000s. A full list of current generic domain names is available from the
Internet Assigned Numbers Authority [www.iana.org I]. In
addition, every country has its own domains:
us – United States
uk – United Kingdom fr – France
... – ...
DNS - The Internet Domain Name System
o
A distributed naming database (specified in RFC
1034/1305)
o
Name structure reflects administrative structure of
the Internet
o
Rapidly resolves domain names to IP addresses
o
exploits caching heavily
o
typical query time ~100 milliseconds
o
Scales to millions of computers
o
partitioned database
o
caching
o
Resilient to failure of a server
o
Replication
Basic DNS algorithm for name resolution (domain
name -> IP number)
o
Look for the name in the local cache
o
Try a superior DNS server, which responds with:
o
–another recommended DNS server
o
–the IP address (which may not be entirely up to
date)
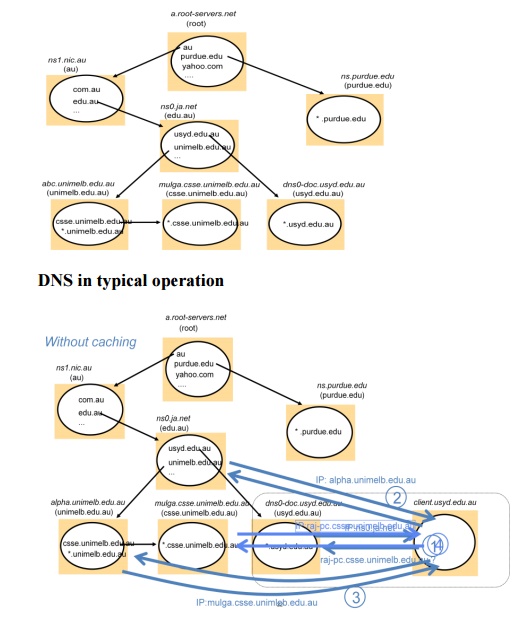
DNS name servers: Hierarchical organisation
Note:
Name server names are in italics, and the corresponding domains are in
parentheses. Arrows denote name server entries
DNS server functions and configuration
o
Main function is to resolve domain names for
computers, i.e. to get their IP addresses
o
caches the results of previous searches until they
pass their 'time to live'
o
Other functions:
o
get mail host
for a domain
o
reverse resolution - get domain name from IP
address
o
Host information - type of hardware and OS
o
Well-known services - a list of well-known services
offered by a host
o
Other attributes can be included (optional)
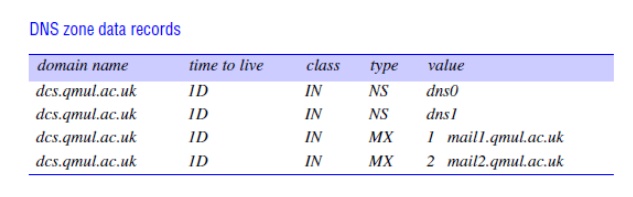
DNS resource records
The DNS
architecture allows for recursive navigation as well as iterative navigation.
The resolver specifies which type of navigation is required when contacting a
name server. However, name servers are not bound to implement recursive
navigation. As was pointed out above, recursive navigation may tie up server
threads, meaning that other requests might be delayed.

The data
for a zone starts with an SOA-type
record, which contains the zone parameters that specify, for example, the
version number and how often secondaries should refresh their copies. This is
followed by a list of records of type NS
specifying the name servers for the domain and a list of records of type MX giving the domain names of mail
hosts, each prefixed by a number expressing its preference. For example, part
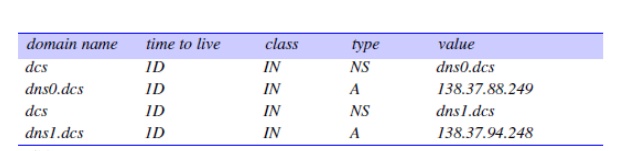
of the database for the domain dcs.qmul.ac.uk
at one point is shown in the following figure where the time to live 1D means 1 day.
The
majority of the remainder of the records in a lower-level zone like dcs.qmul.ac.uk will be of type A and map the domain name of a computer
onto its IP address. They may contain some aliases for the well-known services,
for example:

If the
domain has any subdomains, there will be further records of type NS specifying their name servers, which
will also have individual A entries.
For example, at one point the database for qmul.ac.uk
contained the following records for the name servers in its subdomain dcs.qmul.ac.uk:
DNS issues
o
Name tables change infrequently, but when they do,
caching can result in the delivery of stale data.
o
Clients are responsible for detecting this and
recovering
o
Its design makes changes to the structure of the
name space difficult. For example:
o
merging previously separate domain trees under a
new root
o
moving subtrees to a different part of the
structure (e.g. if Scotland became a separate country, its domains should all
be moved to a new country-level domain.)
o
Directory service: 'yellow pages' for the resources
in a network
§ Retrieves
the set of names that satisfy a given description
o
e.g. X.500, LDAP, MS Active Directory Services
§ (DNS holds some descriptive data, but:
·
the data is very incomplete
·
DNS isn't organised to search it)
o
Discovery service:- a directory service that also:
§ is
automatically updated as the network configuration changes meets the needs of
clients in spontaneous networks (Section 2.2.3)
§ discovers
services required by a client (who may be mobile) within the current scope, for example, to find the most
suitable printing service for image files after arriving at a hotel.
§ Examples of- discovery services: Jini discovery service, the 'service location protocol',
the 'simple service discovery protocol' (part of UPnP), the 'secure discovery
service'.
The name
services store collections of <name,
attribute> pairs, and how the attributes are looked up from a name. It
is natural to consider the dual of this arrangement, in which attributes are used as values to be
looked up. In these services, textual names can be considered to be just
another attribute. Sometimes users wish to find a particular person or
resource, but they do not know its name, only some of its other attributes.
For
example, a user may ask: ‘What is the name of the user with telephone number
020-555 9980?’ Likewise, sometimes users require a service, but they are not
concerned with what system entity supplies that service, as long as the service
is conveniently accessible.
For
example, a user might ask, ‘Which computers in this building are Macintoshes
running the Mac OS X operating system?’ or ‘Where can I print a high-resolution
colour image?’
A service
that stores collections of bindings between names and attributes and that looks
up entries that match attribute-based specifications is called a directory service.
Examples
are Microsoft’s Active Directory Services, X.500 and its cousin LDAP, Univers
and
Profile.
Directory
services are sometimes called yellow
pages services, and conventional name services are correspondingly called white pages services, in an analogy with
the traditional types of telephone directory. Directory services are also
sometimes known as attribute-based name
services.
A
directory service returns the sets of attributes of any objects found to match
some specified attributes. So, for example, the request ‘TelephoneNumber = 020
5559980’ might return {‘Name = John Smith’, ‘TelephoneNumber = 020 555 9980’,
‘emailAddress = john@dcs.gormenghast.ac.uk’, ...}.
The
client may specify that only a subset of the attributes is of interest – for
example, just the email addresses of matching objects. X.500 and some other
directory services also allow objects to be looked up by conventional
hierarchic textual names. The Universal Directory and Discovery Service (UDDI),
which was presented in Section 9.4, provides both white pages and yellow pages
services to provide information about organizations and the web services they
offer.
UDDI
aside, the term discovery service
normally denotes the special case of a directory service for services provided
by devices in a spontaneous networking environment. As Section 1.3.2 described,
devices in spontaneous networks are liable to connect and disconnect
unpredictably. One core difference between a discovery service and other
directory services is that the address of a directory service is normally well
known and preconfigured in clients, whereas a device entering a spontaneous
networking environment has to resort to multicast navigation, at least the
first time it accesses the local discovery service.
Attributes
are clearly more powerful than names as designators of objects: programs can be
written to select objects according to precise attribute specifications where
names might not be known. Another advantage of attributes is that they do not
expose the structure of organizations to the outside world, as do
organizationally partitioned names. However, the relative simplicity of use of
textual names makes them unlikely to be replaced by attribute-based naming in
many applications.
Discovery service
A
database of services with lookup based on service description or type, location
and other criteria, E.g.
Find a printing service in this hotel compatible with a Nikon camera
Send the video from my camera to the digital TV in my room.
Automatic
registration of new services
Automatic
connection of guest's clients to the discovery service
Related Topics