Chapter: Distributed Systems : Peer To Peer Services and File System
Distributed File Systems
DISTRIBUTED FILE SYSTEMS
A file
system is responsible for the organization, storage, retrieval, naming,
sharing, and protection of files. File systems provide directory services,
which convert a file name (possibly a hierarchical one) into an internal
identifier (e.g. inode, FAT index). They contain a representation of the file data
itself and methods for accessing it (read/write). The file system is
responsible for controlling access to the data and for performing low-level
operations such as buffering frequently used data and issuing disk I/O
requests.
A
distributed file system is to present certain degrees of transparency to the
user and the system: Access
transparency: Clients are unaware that files are distributed and can access
them in the same way as local files
are accessed.
Location transparency: A
consistent name space exists encompassing local as well as remote files. The name of a file does not
give it location.
Concurrency transparency: All
clients have the same view of the state of the file system. This means that if one process is modifying
a file, any other processes on the same system or remote systems that are
accessing the files will see the modifications in a coherent manner.
Failure transparency: The
client and client programs should operate correctly after a server failure.
Heterogeneity: File service should be provided
across different hardware and operating system platforms.
Scalability: The file system should work well
in small environments (1 machine, a dozen
machines) and also scale gracefully to huge ones (hundreds through tens of
thousands of systems).
Replication transparency: To
support scalability, we may wish to replicate files across multiple servers. Clients should be unaware of this.
Migration transparency: Files
should be able to move around without the client's knowledge. Support fine-grained distribution of
data: To optimize performance, we may wish to locate individual objects near
the processes that use them.
Tolerance for network partitioning: The
entire network or certain segments of it may be unavailable to a client during certain periods (e.g. disconnected
operation of a laptop). The file system should be tolerant of this.
File service types
To
provide a remote system with file service, we will have to select one of two
models of operation. One of these is the upload/download model. In this model,
there are two fundamental operations: read
file transfers an entire file from the server to the requesting client, and
write file copies the file back to
the server. It is a simple model and efficient in that it provides local access
to the file when it is being used. Three problems are evident. It can be
wasteful if the client needs access to only a small amount of the file data. It
can be problematic if the client doesn't have enough space to cache the entire
file. Finally, what happens if others need to modify the same file?
The
second model is a remote access model. The file service provides remote
operations such as open, close, read bytes, write bytes, get attributes, etc. The file system
itself runs on servers. The drawback
in this approach is the servers are accessed for the duration of file access
rather than once to download the file and again to upload it.
Another
important distinction in providing file service is that of understanding the
difference between directory service
and file service. A directory
service, in the context of file systems, maps human-friendly textual names for
files to their internal locations, which can be used by the file service. The
file service itself provides the file interface (this is mentioned above).
Another component of file distributed file systems is the client module. This
is the client-side interface for file and directory service. It provides a
local file system interface to client software (for example, the vnode file
system layer of a UNIX kernel).
Introduction
·
File system were originally developed for
centralized computer systems and desktop computers.
·
File system was as an operating system facility
providing a convenient programming interface to disk storage.
·
Distributed file systems support the sharing of
information in the form of files and hardware resources.
·
With the advent of distributed object systems
(CORBA, Java) and the web, the picture has become more complex.
·
Figure 1 provides an overview of types of storage
system.
Figure 1. Storage systems and their properties
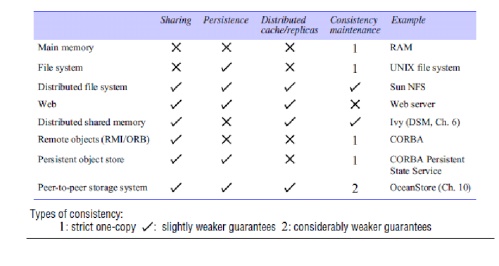
·
Figure 2 shows a typical layered module structure
for the implementation of a non-distributed file system in a conventional
operating system.
·
Figure 2.
File system modules

·
File systems are responsible for the organization,
storage, retrieval, naming, sharing and protection of files.
·
Files contain both data and attributes.
·
A typical attribute record structure is illustrated
in Figure 3.
Figure 3. File attribute record structure

·
Figure 4 summarizes the main operations on files
that are available to applications in UNIX systems.

Distributed
File system requirements
Related requirements in distributed file systems are:
·
Transparency
·
Concurrency
·
Replication
·
Heterogeneity
·
Fault tolerance
·
Consistency
·
Security
·
Efficiency
Case
studies
File service architecture • This is
an abstract architectural model that underpins both NFS and AFS. It is based upon a division of responsibilities
between three modules – a client module that emulates a conventional file
system interface for application programs, and server modules, that perform
operations for clients on directories and on files. The architecture is
designed to enable a stateless
implementation of the server module.
SUN NFS • Sun Microsystems’s Network
File System (NFS) has been
widely adopted in industry and in
academic environments since its introduction in 1985. The design and
development of NFS were undertaken by staff at Sun Microsystems in 1984.
Although several distributed file services had already been developed and used
in universities and research laboratories, NFS was the first file service that
was designed as a product. The design and implementation of NFS have achieved
success both technically and commercially.
Andrew File System • Andrew is
a distributed computing environment developed at Carnegie Mellon University (CMU) for use as a campus computing and
information system. The design of the Andrew File System (henceforth
abbreviated AFS) reflects an intention to support information sharing on a
large scale by minimizing client-server communication. This is achieved by
transferring whole files between server and client computers and caching them
at clients until the server receives a more up-to-date version.
Related Topics