Chapter: Fundamentals of Database Systems : Advanced Database Models, Systems, and Applications : Enhanced Data Models for Advanced Applications
Information Retrieval (IR) Concepts
Information Retrieval (IR) Concepts
Information retrieval is the process of retrieving documents from a collection in response to a query (or a search
request) by a user. This section provides an overview of information retrieval
(IR) concepts. In Section 27.1.1, we introduce information retrieval in general
and then discuss the different kinds and levels of search that IR encompasses.
In Section 27.1.2, we compare IR and database technologies. Section 27.1.3
gives a brief history of IR. We then present the different modes of user
interaction with IR systems in Section 27.1.4. In Section 27.1.5, we describe
the typical IR process with a detailed set of tasks and then with a simplified
process flow, and end with a brief discussion of digital libraries and the Web.
1. Introduction to
Information Retrieval
We first review the distinction between structured and unstructured data
(see Section 12.1) to see how information retrieval differs from structured
data management. Consider a relation (or table) called HOUSES with the attributes:
HOUSES(Lot#,
Address, Square_footage, Listed_price)
This is an example of structured
data. We can compare this relation with home-buying contract documents,
which are examples of unstructured data.
These types of documents can vary from city to city, and even county to county,
within a given state in the United States. Typically, a contract document in a
particular state will have a standard list of clauses described in paragraphs
within sections of the docu-ment, with some predetermined (fixed) text and some
variable areas whose content is to be supplied by the specific buyer and
seller. Other variable information would include interest rate for financing,
down-payment amount, closing dates, and so on. The documents could also
possibly include some pictures taken during a home inspection. The information
content in such documents can be considered unstructured
data that can be stored in a variety of possible arrangements and for-mats.
By unstructured information, we
generally mean information that does not have a well-defined formal model and
corresponding formal language for representation and reasoning, but rather is
based on understanding of natural language.
With the advent of the World Wide Web (or Web, for short), the volume of
unstructured information stored in messages and documents that contain textual
and multimedia information has exploded. These documents are stored in a
variety of standard formats, including HTML, XML (see Chapter 12), and several audio
and video formatting standards. Information retrieval deals with the problems
of storing, indexing, and retrieving (searching) such information to satisfy
the needs of users. The problems that IR deals with are exacerbated by the fact
that the number of Web pages and the number of social interaction events is
already in the billions, and is growing at a phenomenal rate. All forms of
unstructured data described above are being added at the rates of millions per
day, expanding the searchable space on the Web at rapidly increasing rates.
Historically, information
retrieval is “the discipline that deals with the structure, analysis,
organization, storage, searching, and retrieval of information” as defined by
Gerald Salton, an IR pioneer. We can enhance the definition slightly to say that it applies in the
context of unstructured documents to satisfy a user’s information needs. This
field has existed even longer than the database field, and was originally
concerned with retrieval of cataloged information in libraries based on titles,
authors, topics, and keywords. In academic programs, the field of IR has long
been a part of Library and Information Science programs. Information in the
context of IR does not require machine-understandable structures, such as in
relational database systems. Examples of such information include written
texts, abstracts, documents, books, Web pages, e-mails, instant messages, and
collections from digital libraries. Therefore, all loosely represented
(unstructured) or semistructured information is also part of the IR discipline.
We introduced XML modeling and retrieval in Chapter 12 and discussed
advanced data types, including spatial, temporal, and multimedia data, in
Chapter 26. RDBMS vendors are providing modules to support many of these data
types, as well as XML data, in the newer versions of their products, sometimes
referred to as extended RDBMSs, or object-relational database management
systems (ORDBMSs, see Chapter
11). The challenge of dealing with unstructured data is largely an information
retrieval problem, although database researchers have been applying data-base
indexing and search techniques to some of these problems.
IR systems go beyond database systems in that they do not limit the user
to a specific query language, nor do they expect the user to know the
structure (schema) or content of a particular database. IR systems use a user’s
information need expressed as a free-form
search request (sometimes called a keyword
search query, or just query) for
interpretation by the system. Whereas the IR field historically dealt with cataloging, processing, and accessing
text in the form of documents for decades, in today’s world the use of Web
search engines is becoming the dominant way to find information. The traditional
problems of text indexing and making collections of documents searchable have
been transformed by making the Web itself into a quickly accessible repository
of human knowledge.
An IR system can be characterized at different levels: by types of users, types of data, and the types of the information
need, along with the size and scale of the information repository it
addresses. Different IR systems are designed to address specific problems that
require a combination of different characteristics. These characteristics can
be briefly described as follows:
Types of Users. The user may be an expert user (for example, a curator or a
librarian), who is searching for specific information that is clear in
his/her mind and forms relevant queries for the task, or a layperson user with a generic information need. The latter cannot
create highly relevant queries for search (for example, students trying to find
information about a new topic, researchers trying to assimilate different
points of view about a historical issue, a scientist verifying a claim by
another scientist, or a person trying to shop for clothing).
Types of Data. Search systems can be tailored to specific types of data. For example, the problem of retrieving
information about a specific topic may be handled more efficiently by
customized search systems that are built to collect and retrieve only
information related to that specific topic. The information repository could be
hierarchically organized based on a concept or topic hierarchy. These topical domain-specific or vertical IR systems are not as large as or as diverse as the
generic World Wide Web, which contains information on all kinds of topics.
Given that these domain-specific collections exist and may have been acquired
through a specific process, they can be exploited much more efficiently by a
specialized system.
Types of Information Need. In the context of Web search, users’ information needs may be defined as navigational, informational, or
transactional. Navigational search refers to
finding a particular piece of information (such as the Georgia Tech University Website) that a user needs quickly.
The purpose of informational search is
to find current information about a topic (such as research activities in the college of computing at Georgia
Tech—this is the classic IR system task). The goal of transactional search is to reach a site where further interaction
happens (such as joining a social network, product shopping, online
reservations, accessing databases, and so on).
Levels of Scale. In the words of Nobel Laureate Herbert Simon,
What information consumes is rather obvious: it consumes the attention of its recipients. Hence a wealth of information creates a poverty of attention, and a need to allocate that attention efficiently among the overabundance of information sources that might consume it.
This overabundance of information sources in effect creates a high
noise-to-signal ratio in IR systems. Especially on the Web, where billions of
pages are indexed, IR interfaces are built with efficient scalable algorithms
for distributed searching, indexing, caching, merging, and fault tolerance. IR
search engines can be limited in level to more specific collections of
documents. Enterprise search systems
offer IR solutions for searching different entities in an enterprise’s intranet, which consists of the network
of computers within that enterprise. The searchable entities include e-mails,
corporate documents, manuals, charts, and presentations, as well as reports
related to people, meetings, and projects. They still typically deal with
hundreds of millions of entities in large global enterprises. On a smaller
scale, there are personal information systems such as those on desktops and
laptops, called desktop search engines (for example, Google Desktop),
for retrieving files, folders, and different kinds of entities stored on the computer. There are peer-to-peer
systems, such as BitTorrent, which allows sharing of music in the form of audio
files, as well as spe-cialized search engines for audio, such as Lycos and
Yahoo! audio search.
2. Databases and IR
Systems: A Comparison
Within the computer science discipline, databases and IR systems are
closely related fields. Databases deal with structured information retrieval
through well-defined formal languages for representation and manipulation based
on the theoretically founded data models. Efficient algorithms have been
developed for operators that allow rapid execution of complex queries. IR, on
the other hand, deals with unstructured search with possibly vague query or
search semantics and without a well-defined logical schematic representation.
Some of the key differences between databases and IR systems are listed in
Table 27.1.
Whereas databases have fixed schemas defined in some data model such as
the relational model, an IR system has no fixed data model; it views data or
documents according to some scheme, such as the vector space model, to aid in
query processing (see Section 27.2). Databases using the relational model employ
SQL for queries and transactions. The queries are mapped into relational
algebra operations and search algorithms (see Chapter 19) and return a new
relation (table) as the query result, providing an exact answer to the query
for the current state of the database. In IR systems, there is no fixed
language for defining the structure (schema) of the document or for operating
on the document—queries tend to be a set of query terms (keywords) or a
free-form natural language phrase. An IR query result is a list of document
ids, or some pieces of text or multimedia objects (images, videos, and so on),
or a list of links to Web pages.
The result of a database query is an exact answer; if no matching
records (tuples) are found in the relation, the result is empty (null). On the
other hand, the answer to a user request in an IR query represents the IR
system’s best attempt at retrieving the
Table 27.1 A Comparison of Databases
and IR Systems
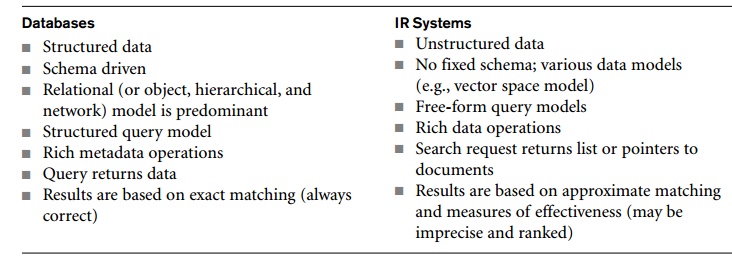
information most relevant to that query. Whereas database systems
maintain a large amount of metadata and allow their use in query optimization,
the operations in IR systems rely on the data values themselves and their
occurrence frequencies. Complex statistical analysis is sometimes performed to
determine the relevance of each
document or parts of a document to the user request.
3. A Brief History of
IR
Information retrieval has been a common task since the times of ancient
civilizations, which devised ways to organize, store, and catalog documents and
records. Media such as papyrus scrolls and stone tablets were used to record
documented information in ancient times. These efforts allowed knowledge to be
retained and transferred among generations. With the emergence of public
libraries and the printing press, large-scale methods for producing,
collecting, archiving, and distributing documents and books evolved. As
computers and automatic storage systems emerged, the need to apply these
methods to computerized systems arose. Several techniques emerged in the 1950s,
such as the seminal work of H. P. Luhn, who pro-posed using words and their frequency counts as indexing units
for documents, and using measures of word overlap between queries and documents
as the retrieval criterion. It was soon realized that storing large amounts of
text was not difficult. The harder task was to search for and retrieve that
information selectively for users with specific information needs. Methods that
explored word distribution statistics gave rise to the choice of keywords based
on their distribution properties and keyword-based weighting schemes.
The earlier experiments with document retrieval systems such as SMART in the 1960s adopted the inverted file organization based on
keywords and their weights as the method of indexing (see Section 27.5). Serial
(or sequential) organization proved inadequate if queries required fast, near
real-time response times. Proper organization of these files became an
important area of study; document classification and clustering schemes ensued.
The scale of retrieval experiments remained a challenge due to lack of
availability of large text collections. This soon changed with the World Wide
Web. Also, the Text Retrieval Conference (TREC) was launched by NIST (National
Institute of Standards and Technology) in 1992 as a part of the TIPSTER program
with the goal of providing a platform for evaluating information retrieval
methodologies and facilitating technology transfer to develop IR products.
A search engine is a
practical application of information retrieval to large-scale document
collections. With significant advances in computers and communications
technologies, people today have interactive access to enormous amounts of
user-generated distributed content on the Web. This has spurred the rapid
growth in search engine technology, where search engines are trying to discover
different kinds of real-time content found on the Web. The part of a search
engine responsible for discovering, analyzing, and indexing these new
documents is known as a crawler.
Other types of search engines exist for specific domains of knowledge. For example, the biomedical literature
search database was started in the 1970s and is now supported by the PubMed
search engine, which gives access to over 20 million abstracts.
While continuous progress is being made to tailor search results to the
needs of an end user, the challenge remains in providing high-quality,
pertinent, and timely information that is precisely aligned to the information
needs of individual users.
4. Modes of Interaction
in IR Systems
In the beginning of Section 27.1, we defined information retrieval as
the process of retrieving documents from a collection in response to a query
(or a search request) by a user. Typically the collection is made up of
documents containing unstructured data. Other kinds of documents include
images, audio recordings, video strips, and maps. Data may be scattered
nonuniformly in these documents with no definitive structure. A query is a set of terms (also referred to as keywords)
used by the searcher to specify an information need (for example, the terms
‘databases’ and ‘operating systems’ may be regarded as a query to a computer
science bibliographic database). An informational request or a search query may
also be a natural language phrase or a question (for example, “What is the
currency of China?” or “Find Italian restaurants in Sarasota, Florida.”).
There are two main modes of interaction with IR systems—retrieval and
browsing—which, although similar in goal, are accomplished through different
interaction tasks. Retrieval is
concerned with the extraction of relevant information from a repository of
documents through an IR query, while browsing
signifies the activity of a user visiting or navigating through similar or
related documents based on the user’s assessment of relevance. During browsing,
a user’s information need may not be defined a priori and is flexible. Consider the following browsing scenario:
A user specifies ‘Atlanta’ as a keyword. The information retrieval system
retrieves links to relevant result documents containing various aspects of
Atlanta for the user. The user comes across the term ‘Georgia Tech’ in one of
the returned documents, and uses some access technique (such as clicking on the
phrase ‘Georgia Tech’ in a document, which has a built-in link) and visits
documents about Georgia Tech in the same or a different Website (repository).
There the user finds an entry for ‘Athletics’ that leads the user to
information about various athletic programs at Georgia Tech. Eventually, the
user ends his search at the Fall schedule for the Yellow Jackets foot-ball
team, which he finds to be of great interest. This user activity is known as
browsing. Hyperlinks are used to
interconnect Web pages and are mainly used for browsing. Anchor texts are text phrases within documents used to label
hyperlinks and are very relevant to browsing.
Web search combines both aspects—browsing and retrieval—and is one of the main applications of information retrieval
today. Web pages are analogous to documents. Web search engines maintain an
indexed repository of Web pages, usually using the technique of inverted
indexing (see Section 27.5). They retrieve the most relevant Web pages for the
user in response to the user’s search request with a possible ranking in
descending order of relevance. The rank
of a Webpage in a retrieved set is the measure of its relevance to the
query that generated the result set.
5. Generic IR Pipeline
As we mentioned earlier, documents are made up of unstructured natural
language text composed of character strings from English and other languages.
Common examples of documents include newswire services (such as AP or Reuters),
corporate manuals and reports, government notices, Web page articles, blogs,
tweets, books, and journal papers. There are two main approaches to IR:
statistical and semantic.
In a statistical approach,
documents are analyzed and broken down into chunks of text (words, phrases, or n-grams, which are all subsequences of
length n characters in a text or
document) and each word or phrase is counted, weighted, and measured for
relevance or importance. These words and their properties are then compared
with the query terms for potential degree of match to produce a ranked list of
resulting documents that contain the words. Statistical approaches are further
classified based on the method employed. The three main statistical approaches
are Boolean, vector space, and probabilistic (see Section 27.2).
Semantic approaches to IR use knowledge-based techniques of retrieval that broadly rely on the syntactic,
lexical, sentential, discourse-based, and pragmatic levels of knowledge
understanding. In practice, semantic approaches also apply some form of
statistical analysis to improve the retrieval process.
Figure 27.1 shows the various stages involved in an IR processing
system. The steps shown on the left in Figure 27.1 are typically offline
processes, which prepare a set of documents for efficient retrieval; these are
document preprocessing, document modeling, and indexing. The steps involved in
query formation, query processing, searching mechanism, document retrieval, and
relevance feedback are shown on the right in Figure 27.1. In each box, we
highlight the important concepts and issues. The rest of this chapter describes
some of the concepts involved in the various tasks within the IR process shown
in Figure 27.1.
Figure 27.2 shows a simplified IR processing pipeline. In order to
perform retrieval on documents, the documents are first represented in a form
suitable for retrieval. The significant terms and their properties are
extracted from the documents and are represented in a document index where the
words/terms and their properties are stored in a matrix that contains these
terms and the references to the documents that contain them. This index is then
converted into an inverted index (see Figure 27.4) of a word/term vs. document
matrix. Given the query words, the documents

containing these words—and the document properties, such as date of
creation, author, and type of document—are fetched from the inverted index and
compared with the query. This comparison results in a ranked list shown to the
user. The user can then provide feedback on the results that triggers implicit
or explicit query expansion to fetch results that are more relevant for the
user. Most IR systems allow for an interactive search where the query and the
results are successively refined.
Related Topics